Milch (DE)#
print("Hallo Welt!")
Hallo Welt!
Ausgangspunkt#
Die maßgebliche Motivation für GenDifS ist das Konzept der skos:Collection-Klasse, veranschaulicht in dem Milch-Beispiel aus dem SKOS-Primer 4 Advanced SKOS: When KOSs are not Simple Anymore > 4.1 Collections of Concepts:
milk
<milk by source animal>
cow milk
goat milk
buffalo milk
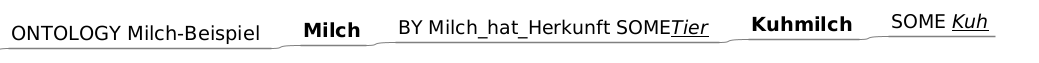
Fig. 12 Beispiel Milch#
ttl dieses Beispiels erzeugen#
import sys
sys.path.append('../py/')
from gd06 import GenDifS_Map
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 3
1 import sys
2 sys.path.append('../py/')
----> 3 from gd06 import GenDifS_Map
ModuleNotFoundError: No module named 'gd06'
mm = "Milch_DE"
o = GenDifS_Map(f"../mm/{mm}.mm")
o.compile()
# export raw GenDifS turtle
with open(f"../ttl/{mm}_mm.ttl", "w") as file:
file.write(o.ttl_code)
#export rdflib graph: quality checked!
len(o.rdflib_graph.serialize(destination=f"../ttl/{mm}_rdflb.ttl"))
Inferencing mit OWLRL:
o.owlrl()
len(o.owlrl_graph.serialize(destination=f"../ttl/{mm}_owlrl.ttl"))
Erklärungen#
Anschauliche Erklärung: Offensichtlich sind in diesem Beispiel zwei parallele Teilmengen-Beziehungen enthalten. Die erste, in Fettdruck wiedergegebene Beziehung besteht zwischen den Hauptklassen Milch und Kuhmilch und spannt insgesamt den für Mindmaps typischen Primärbaum auf:
:Kuhmilch
rdfs:subClassOf :Milch .
Mit diesem Baum ist aber auch eine zweite, in der Abbildung in unterstrichenem Kursivdruck wiedergegebene Beziehung zwischen charakterisierenden Sekundärbaum eng verflochten:
:Kuh
rdfs:subClassOf :Tier .
In GenDifS werden zwei wie hier zusammengehörenden Bäume ineinander verflochten modelliert. Dieses Syntax-Detail von GenDifS entspringt der Beobachtung, dass wir oft einen Sekundärbaum verwenden, um einen Primärbaum zu modellieren.
In Protegé sieht man, dass hier (mindestens) die folgenden zwei Begriffsbäume enthalten sind:
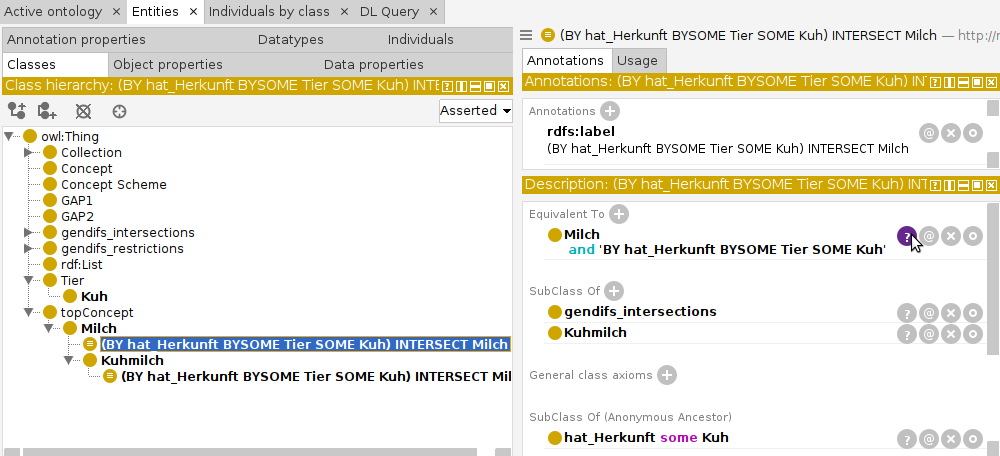
Fig. 13 Beispiel Milch in Protegé#
T-Box: OWL-Klassen und -Inferencing#
Wir betrachten den Satz:
Kuhmilch ist eine Milch, die von Rindern kommt.
In diesem Satz sind diese Informationen enthalten:
Kuhmilch: Darum geht es im folgenden; Subjektist: die Beziehung zum Oberbegriff ist (hier) eine Teilmengenbeziehungeine Milch ...: erste Chrakterisierung von Kuhmilch, hier durch Kennzeichnung als Teilmenge des OberbegriffsMilcheine Milch, die ...: Charakterisierung einer speziellen Teilklasse vonMilchdurch eine zusätzliche chrakterisierende Eigenschaftvon ... kommt.: chrakteristisches Attribut ist die Herkunft (und nicht z.B. der Fettgehalt)... Rindern ...: der Wert des chrakteristischen Attributs Herkunft sind Rinder.
An der Formalisierung beteiligte Mengen:
Menge 1: alle Dinge, die eine Milch sind
:Milch
a owl:Class ;
rdfs:subClassOf :topConcept .
Menge 2: alle Dinge, die als Herkunft “Kuh” haben
:SOME_166726759_restriction
a owl:Class ;
rdfs:label "BY hat_Herkunft BYSOME Tier SOME Kuh" ;
rdfs:subClassOf :gendifs_restrictions ;
owl:equivalentClass [ a owl:Restriction ;
owl:onProperty :hat_Herkunft ;
owl:someValuesFrom :Kuh ] .
Menge 3: alle Dinge, die eine Kuhmilch sind
:Kuhmilch
a owl:Class ;
Die Mengen 1-3 stehen bis jetzt völlig nebeneinander. Um Inferencing zu ermöglichen, beschreiben wir ihren Zusammenhang mit Axiomen.
Aufwärts-Inferencing#
Um ein relativ triviales Inferencing zu ermöglichen, fügen wir ein Subklassen-Axiom hinzu:
Menge 3 ist eine Teilmenge von Menge 1
:Kuhmilch
rdfs:subClassOf :Milch .
Aufgrund dieser Aussage wird ein Reasoner dann, wenn ein Ding X Element der Menge 3: Kuhmilch ist, dieses Ding auch als Element der Menge 1: Milch klassifizieren.
Weil hier von einer Teilmenge auf die übergeordnete Menge geschlossen wird, wollen wir dieses Inferencing “aufwärts” nennen.
Abwärts-Inferencing#
Um ein Ding anhand seiner Eigenschaften genauer klassifizieren zu können, benötigen wir erstens eine weitere Menge:
Menge 4 = Schnittmenge von Menge 1 und Menge 2: Alle Dinge, die eine Milch sind, UND die als Herkunft Kuh haben.
:SOME_166726759_intersection
a owl:Class ;
rdfs:label "(BY hat_Herkunft BYSOME Tier SOME Kuh) INTERSECT Milch" ;
owl:equivalentClass [ a owl:Class ;
owl:intersectionOf (
:SOME_166726759_restriction
:Milch ) ] .
Und um das Inferencing letztlich möglich zu machen, fügen wir zweitens noch eine weiteres Axiom hinzu, mit dem Menge 4 als Teilmenge von Menge 3 definiert wird:
Alle Dinge, die aus Menge 4 sind, sind automatisch auch enthalten in Menge 3
:SOME_166726759_intersection
rdfs:subClassOf :Kuhmilch .
Indem wir die Schnittmenge von Menge 1 und 2 als Teilmenge von Menge 3 definieren, wird jetzt das gesuchte Inferencing unterstützt, das uns die Klassifiation erlaubt: Gegeben sei ein Ding X, von dem wir wissen,
dass es eine Milch ist: X ist Element von Menge 1;
dass es von einer Kuh stammt: X ist gleichzeitig auch Element von Menge 2.
Aufgrund dieser Angaben wird der Reasoner X auch als Element der Menge 4 klassifizieren. Und da Menge 4 als eine Teilmenge von Menge 3 definiert wurde, wird der Reasoner dann X ebenfalls als Element der Menge 3 klassifizieren: Damit wäre der Klassifikationsschritt Milch + Herkunft Kuh = Kuhmilch durchgeführt!
Formalisierung des Abwärts-Inferencings in Mengenschreibweise:
Kuhmilch ⊇ {x | Milch(x) ∧ ∃y[hat_Herkunft(x,y) ∧ Kuh(y)] }
Formalisierung in First Order Logic (FOL):
∀x[Kuhmilch(x) ← Milch(x) ∧ ∃y[hat_Herkunft(x,y) ∧ Kuh(y)]
Formalisierung in Description Logic (DL):
Kuhmilch ⊇ X
X == Milch ∧ ∃ hat_Herkunft.Kuh
(Wir haben hier X als Abkürzung für :Milch_AND_:hat_Herkunft_SOME_:Kuh verwendet.)
A-Box#
In GenDifS wird eine Ontologie abstrakt in einer Mindmap-basierten Sprache dargestellt. Deshalb ist es nötig, die Mindmap in mindestens eine, und möglich, die Mindmap in mehr als eine Ontologiesprache zu übesetzen.
Tatsächlich übersetzen wir einen einzigen Knoten in 3 verschiedene Objekte, die wir per Namespace unterscheiden:
@prefix : <http://mm2ttl.net/namespace/default#> .
@prefix cpt: <http://mm2ttl.net/namespace/cpt#> .
@prefix ex: <http://mm2ttl.net/namespace/ex#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
Für Kuhmilch als OWL-Klasse verwenden wir den Namespace :. In ttl wird das Objekt :Kuhmilch also expandiert zu http://mm2ttl.net/namespace/default#Kuhmilch.
:Kuhmilch
a owl:Class ;
rdfs:subClassOf :Milch .
Für jede OWL-Klasse legen wir eine Test-Instanz an, im Beispiel :Kuhmilch das Objekt ex:Kuhmilch_ID_1640204723.
ex:Kuhmilch_ID_1640204723
a :Kuhmilch .
Die von GenDifS angelegten Beispiel-Instanzen erhalten das Präfix ex:. ACHTUNG: Protege untedrückt in der Anzeige das Präfix. Alle Beispiel-Instanzen erhalten deshalb zusätzlich eine gut sichtbare ID, um eine Verwechslung mit den Klassen auszuschließen.
A-Box Inferencing-Test#
Um zu prüfen, ob die Übersetzung von GenDifS nach OWL korrekt erfolgt und in Kombination mit dem vorgesehenen Reasoner - hier dem OWL-RL-Reasoner owlrl - funktioniert, fügen wir den automatisch angelegten Beispiel-Instanzen zusätzliche Features hinzu. Beispiel:
ex:Milch_166726759
a :Milch ;
:hat_Herkunft ex:Kuh_166726759 ;
ex:classifyLike ex:Kuhmilch_166726759 .
ex:Kuh_166726759
a :Kuh .
ex:Kuhmilch_166726759
a :Kuhmilch .
In diesem Fall ist ex:Milch_166726759 eine Instanz der Klasse :Milch, aber nicht der Subklasse :Kuhmilch. Aufgrund ihrer Herkunft soll ex:Milch_166726759 vom Reasoner jedoch gleich klassifiziert werden wie ex:Kuhmilch_166726759, also insbesondere als Instanz der Klasse :Kuhmilch.
Nach dem Inferencing durch owlrl sind für die Beispiel-Instanz ex:Milch_166726759 u.a. die folgenden Tripel in der ausmaterialisierten ttl-Datei enthalten:
ex:Milch_166726759 a
:Kuhmilch,
:Milch,
:topConcept,
owl:Thing ;
:hat_Herkunft ex:Kuh_166726759 ;
ex:classifyLike ex:Kuhmilch_166726759 .
SKOS#
Außerdem interpretieren wir die Mindmap als SKOS-Baum. Zur Klasse :Kuhmilch erzeugen wir ein Objekt cpt:Kuhmilch als Instanz der Klasse skos:Concept:
cpt:Kuhmilch
a skos:Concept ;
skos:broader cpt:Milch .
Die drei Objekte :Milch, ex:Milch_166726759 und cpt:Milch haben also unterschiedliche IRIS und bezeichnen unterschiedliche Dinge. Sie können in der selben ttl-Datei nebeneinaner auftreten und in Beziehung treten, ohne dass man mit Punning etc. arbeiten muss.