URI-Semiotik#
REDAKTION
… Uri als Zeichen einführen: Problemlos für Informationsressourcen, Probleme mit unbeschränktem Scope; Identitätskrise des Web, httpRange-14-Problem. … Verschiedene komplexe Lösungsmodelle: Halpin etc. … Eigener Lösungsversuch mit WEMI … Bedeutung für Gendifs
TBD: Dieses Kapitel nochmal komplett durchgehen und die entsprechenden Aussagen ‘raussuchen aus WEBARCH, https://www.w3.org/TR/webarch/. Siehe dazu auch ChatGPT.md > Relationship between RFC 3986 and WEBARCH
Semiotische Dreiecke#
REDAKTION
Anknüpfen an die Tradition semiotisches Dreieck … Die Struktur so sichtbar machen, dass sie wiedererkennbar ist, insbesondere in RDF to denote
Semiotik ist die Lehre der Entstehung, Verwendung, Bedeutung von Zeichen. Ein weit verbreitetes Denkmodell besteht darin, dass sich Zeichen auf Gedanken (Ideen, Begriffe) beziehen, die sich ihrerseits auf Dinge in der Welt beziehen; über diesen Umweg kann dann als Abkürzung auch eine direkte Beziehung zwischen Zeichen und dem Ding in der Welt hergestellt werden kann: Ein Zeichen „denotiert“ ein Ding in der Welt. Dieses Modell bildet einen Kern der Semiotik vor Erfindung des Computers, vor dem Internet, vor der Digitalisierung, und ist als „das“ semiotische Dreieck bekannt.
Semiotisches_Dreieck
https://de.wikipedia.org/wiki/Semiotisches_Dreieck
Das semiotische Dreieck ist ein in der Sprachwissenschaft und Semiotik verwendetes Modell. Es soll veranschaulichen, dass ein Zeichenträger (Graphem, Syntagma, Symbol) sich nicht direkt und unmittelbar auf einen außersprachlichen Gegenstand bezieht, sondern dieser Bezug nur mittelbar durch eine Vorstellung/einen Begriff erfolgt.
Diese konventionelle Semiotik stellt drei Elemente oft als Ecken in einem Dreieck dar, typischerweise so:
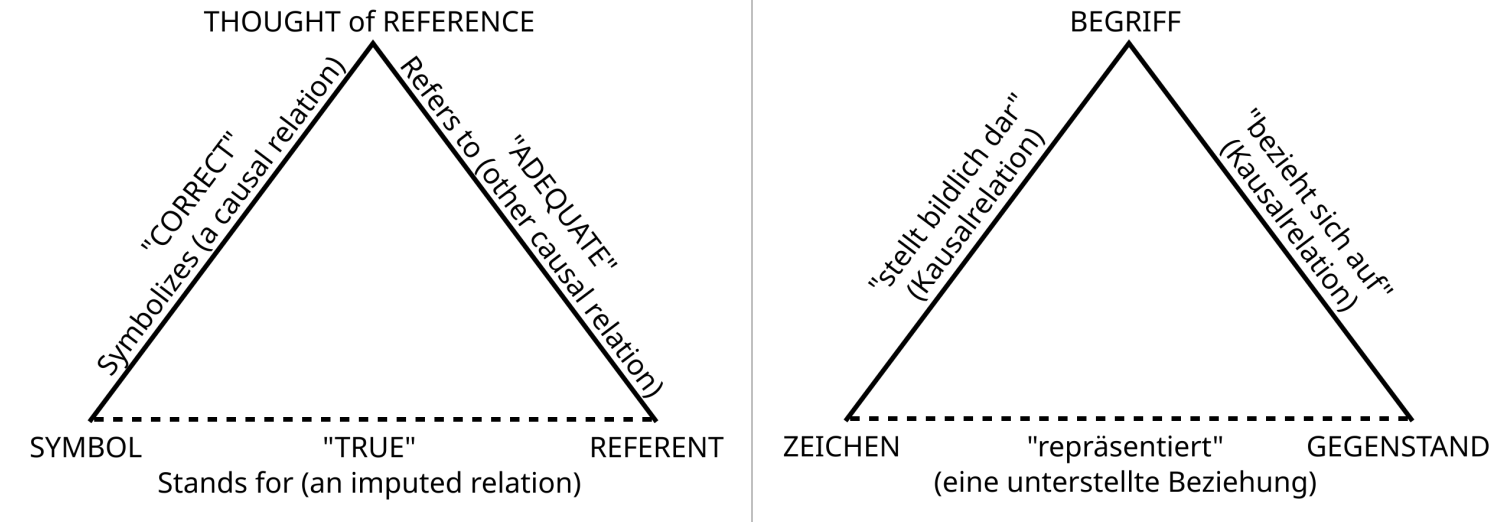
Fig. 9 Quelle: Ogden_semiotic_triangle_EN-DE_license#
Wenn man in die Literatur der Semiotik tiefer eintaucht stellt man fest, dass die Dreiecksform z.T. sehr verschiedene Interpretationen umfasst. „Das“ semiotische Dreieck gibt es so gar nicht, wir haben es mit einer Pluralität von Dreiecken zu tun. Umberto Eco stellt in seinem Werk XXXX (Quelle: U.Eco, Abbildung) einige Bezeichnungen zusammen:
Symbol, Zeichen: Symbol (Ogden-Richards) | Zeichen (Peirce) | Zeichenhaftes Vehikel (Morris) | Ausdruck (Hjelmslev) | Repräsentamen (Peirce) | Sem (Buyssens)
Reference, Begriff: Referenz (Odgen-Richards) | Interpretant (Peirce) | Sinn (Frege) | Intension (Carnap) | Designatum (Morris, 1938) | Significatum (Morris, 1946) | Begriff (Saussure) | Konnotation, Konnotatum (Stuart Mill) | Mentales Bild (Saussure, Peirce) | Inhalt (Hjelmslev) | Bewußtseinszustand (Buyssens)
Referent, Gegenstand: Gegenstand (Frege-Peirce) | Denotatum (Morris) | Signifikat (Frege) | Denotation (Russel) | Extension (Carnap)
Urvater: Gottlob Frege, Sinn und Bedeutung … ausführlich []

Die Vielfalt zeigt, dass „das“ semiotische Dreieck fundamental unterschiedliche Ideen bezeichnet. Die Idee des semiotischen Dreiecks wird auch in der RDF-Spezifikation aufgegriffen. Auch die RDF-Spezifikation verwendet den Begriff der Denotation - bemerkenswerterweise ohne ihn weiter zu erläutern oder zu klären.
#dfn-denote
https://www.w3.org/TR/rdf12-concepts/#dfn-denote
1.2 Resources and Statements: Any IRI or literal denotes something in the world (the “universe of discourse”). These things are called resources. Anything can be a resource, including physical things, documents, abstract concepts, numbers and strings; the term is synonymous with “entity” as it is used in the RDF Semantics specification [RDF11-MT].
1.3 The Referent of an IRI: The resource denoted by an IRI is also called its referent. […] Guidelines for determining the referent of an IRI are provided in other documents, like (Architecture of the World Wide Web, Volume One)[https://www.w3.org/TR/webarch/] [WEBARCH] and Cool URIs for the Semantic Web [COOLURIS].
URIs and IRIs: IRIs are a generalization of URIs [RFC3986] that permits a wider range of Unicode characters [UNICODE]. Every URI and URL is an IRI, but not every IRI is an URI.
Typische Zeichen im Sinne der konventionellen Semiotik sind URL, URI oder DOI, die wir in Kapitel XXX in Bezug auf die einschlägigen RFC im Detail beschreiben. Interessanterweise ist ein URI ein Zeichen, das eine innere Struktur besitzt und so gleichzeitig verschiedene Dinge der Welt „identifizieren“ kann – wobei man bei genauem Hinschauen feststellen wird, dass auch „identifizieren“ ganz unterschiedliche Bedeutungen haben kann. Diese Unklarheiten und Mehrdeutlichkeiten führen zu Problemen, die als Identitätskrise des Semantic Web unter dem Etikett httprange14 vor und 20 Jahren ausführlich diskutiert, aber nie abschließend geklärt wurden.
Wir verwenden im Folgenden das Wort denotieren um explizit anzuzeigen, dass wir an dieser Stelle eben nicht wissen, welcher Art die Beziehung zwischen einem Zeichen und einem Bezeichneten ist – sozusagen als eine Variable für eine bestimmte an dieser Stelle möglicherweise genauere Beziehung zwischen Zeichen und Gegenstand, die uns aber an diese Stelle leider nicht bekannt ist.
Im Kontext von Linked Data und dem Semantic Web ist ein IRI (Internationalized Resource Identifier als der Inbegriff eines digitalen Zeichens wiedererkennabr … (wir belieben in unserer Darstellung bei URI, also ein IRI mur mit ASCII-Zeichen)
Uniform_Resource_Identifier#Konzeption>
https://de.wikipedia.org/wiki/Uniform_Resource_Identifier#Konzeption
Zunächst verstand man unter „Ressource“ etwas wie Ressourcen im informationstechnischen Sinn, also im weitesten Sinne elektronische Dateien, die auch im Internet verfügbar gemacht werden könnten. Davon gingen 1994 die RFC 1630[2] und RFC 1738[3] aus. Dieses Konzept wurde jedoch erweitert. So war 1998 in der RFC 2396 (Abschnitt 1.1)[4] festgelegt worden: „A resource can be anything that has identity.“ Auch Personen, Organisationen und gedruckte Bücher könnten als Ressource betrachtet werden. Diese Betrachtung zielt auf die Kennzeichnung zuordnungsfähiger Entitäten.
Per Definition kann also alles mit einem URI bezeichnet werden. So können alle drei Ecken und die Kanten durch einen URI identifiziert werden, ebenso wie das Dreieck selbst, das Dokument (oder ein Abschnitt, ein Fragment eines Dokuments), das Text enthält, der die Ecken und Kanten beschreibt, etc.
In der konventionellen Semiotik sind es zunächst „Zeichen“ (einschließlich URIs), denen Sinn und Bedeutung zugeschrieben werden kann. In der digitalen Welt sind es zusätzlich auch ganze Dokumente, denen ebenfalls Sinn und Bedeutung zugeordnet werden kann.
#distinguishing>
CoolUrishttps://www.w3.org/TR/cooluris/#distinguishing
3.1 Distinguishing between Representations and Descriptions: It is important to understand that using URIs, it is possible to identify both a thing (which may exist outside of the Web) and a Web document describing the thing. […] According to W3C guidelines ([AWWW], section 2.2.), we have a Web document (there called information resource) if all its essential characteristics can be conveyed in a message. Examples are a Web page, an image or a product catalog. https://www.w3.org/TR/cooluris/#distinguishing
Das konventionelle semiotische Dreieck erweist sich also in der digitalisierten Welt als unterkomplex. Im digitalen Zeitalter muss eine Semiotik der verknüpften Vokabulare komplexer sein, sie muss insbesondere die relevanten technischen Rahmenbedingungen einbeziehen. Hier bieten sich drei Strategien an:
Man könnte „das“ semiotische Dreieck historisch verstehen und die Werke von Aristoteles (384-322 v. Chr.), Charles Sanders Peirce (1839-1914), Ferdinand de Saussure (1857-1913), Charles Ogden und Ivor Richards und natürlich Umberto Eco (1932-2016, Professor für Semiotik mit Lehrstuhl an der Universität Bologna 1975-2007) interpretieren. Man könnte z.B. auf das Methodenspektrum der hermeneutischen Textexegese zurückgreifen.
Man kann versuchen, „das“ semiotische Dreieck weiterzuentwickeln und an die digitale Welt anzupassen.
Man kann „das“ semiotische Dreieck ehrenvoll vom Tisch in die Vitrine stellen, den Tisch abräumen und ohne historischen Ballast mit zeitgemäßen Methoden ein neues Modell formulieren.
Im Folgenden soll ausgelotet werden, wie Strategie 3 aussehen könnte. Dazu versuchen wir, das „Wesen“ von Referenz, Begriff, Bedeutung etc. zu rekonstruieren. Als Akteure im Bereich des Semantic Web beschränken wir uns dabei zunächst auf eine Teilwelt, nämlich die Welt der Dokumente, Dateien, Wissensbausteine etc, also die Welt des Semantic Web selbst. Ziel ist nicht eine allgemeine, sondern eine spezielle Semiotik, die mit den Begriffen und Methoden des Semantic Web formuliert wird.
webarch#
REDAKTION
Zentrales Dokument! Übersicht über die Inhalte … Rückbezüge zu WEMI?
Zentrales Dokument:
WEBARCH: Architecture of the World Wide Web, Volume One W3C Recommendation 15 December 2004. https://www.w3.org/TR/webarch/ []
früher Kommentar: https://www.xml.com/pub/a/2005/01/19/review.html
persönlicher Blog von TBL: https://www.w3.org/DesignIssues/
Autoren:
Acknowledgments. This document was authored by the W3C Technical Architecture Group which included the following participants: Tim Berners-Lee (co-Chair, W3C), Tim Bray (Antarctica Systems), Dan Connolly (W3C), Paul Cotton (Microsoft Corporation), Roy Fielding (Day Software), Mario Jeckle (Daimler Chrysler), Chris Lilley (W3C), Noah Mendelsohn (IBM), David Orchard (BEA Systems), Norman Walsh (Sun Microsystems), and Stuart Williams (co-Chair, Hewlett-Packard). (https://www.w3.org/TR/webarch/#acks)
three architectural bases:
Identification
Interaction
Formats
Durchgängiges Beispiel: http://weather.example.com/oaxaca
Erste Abbildung im Text:
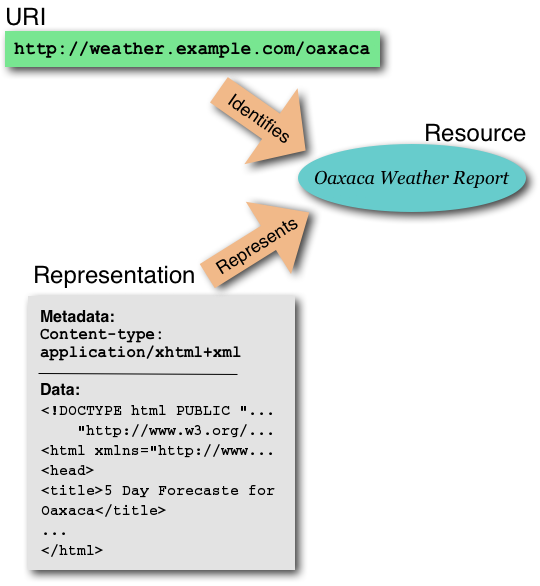
Note: Some URI schemes (such as the “ftp” URI scheme specification) use the term “designate” where this document uses “identify.” (https://www.w3.org/TR/webarch/#uri-benefits)
Terminologie:
Statt de:Ressource als Übersetzung für en:resource verwenden wir im folgenden das Wort Entität. EN:entity ist ein legitimes Synonym für en:resource:
1.2 Resources and Statements. Any IRI or literal denotes something in the world (the “universe of discourse”). These things are called resources. Anything can be a resource, including physical things, documents, abstract concepts, numbers and strings; the term is synonymous with “entity” as it is used in RDF 1.2 Semantics [RDF12-SEMANTICS]. The resource denoted by an IRI is called its referent […] (https://www.w3.org/TR/rdf12-concepts/#resources-and-statements)
Was ist eine resource?#
Dereferenzierung durch Interaktion#
viel technischer Text … knappe Zusammenfassung von https://www.w3.org/TR/webarch/#dereference-details:
Der folgende Interaktionsprozess wird Dereferenzierung oder retrieval eines URI genannt:
unser Browser interpretiert einen URI
insbesondere verwirft er den Fragment Identifier:
Interpretation of the fragment identifier is performed solely by the agent that dereferences a URI; the fragment identifier is not passed to other systems during the process of retrieval. (https://www.w3.org/TR/webarch/#internet-media-type)
unser Browser nimmt mit einem Server Kontakt auf, übergibt den URI
der Server konstruiert eine Repräsentation in einem bestimmt Format
der Server schickt die Repräsentation als Nachricht an unseren Browser zurück
unser Browser interpretiert die Repräsentation
je nachdem, in welchem Format die Repräsentation vorliegt, identifiziert unser Browser nun ggf. noch ein Fragment.
The semantics of a fragment identifier are defined by the set of representations that might result from a retrieval action on the primary resource. The fragment’s format and resolution are therefore dependent on the type of a potentially retrieved representation. (https://www.w3.org/TR/webarch/#internet-media-type)
Assuming that a representation has been successfully retrieved, the expressive power of the representation’s format will affect how precisely the representation provider communicates resource state. If the representation communicates the state of the resource inaccurately, this inaccuracy or ambiguity may lead to confusion among users about what the resource is. If different users reach different conclusions about what the resource is, they may interpret this as a URI collision (§2.2.1). Some communities, such as the ones developing the Semantic Web, seek to provide a framework for accurately communicating the semantics of a resource in a machine readable way. https://www.w3.org/TR/webarch/#dereference-details:
The IRI owner can establish the intended referent by means of a specification or other document that explains what is denoted. […] A good way of communicating the intended referent is to set up the IRI so that it dereferences [WEBARCH] to such a document. Such a document can, in fact, be an RDF document that describes the denoted resource by means of RDF statements. (<https […] Perhaps the most important characteristic of IRIs in web architecture is that they can be dereferenced, and hence serve as starting points for interactions with a remote server. ://www.w3.org/TR/rdf11-concepts/#referents>)
Wir halten fest: Ein URI ist ein Zeichen, der gleichzeitig mit zwei Entitäten verbunden ist:
Er “identifizier” ein beliebiges (digitales oder analoges, konkretes oder abstraktes, existierendes oder auch nur denkbares) Ding in der Welt;
er “dereferenziert” im Rahmen eines technischen Interaktionsprosses (hier das http-Protokoll) eine Repräsentation des identifizierten Dings.
Was ist eine Repräsentation?#
A representation is data that encodes information about resource state. Representations do not necessarily describe the resource, or portray a likeness of the resource, or represent the resource in other senses of the word “represent”. (https://www.w3.org/TR/webarch/#internet-media-type)
Klar ist: Eine Repräsentation ist eine digitale Entität, die insbesondere durch ihr Format angemessen beschrieben wird.
Offen ist: “Eine Repräsentation besteht aus Daten, die Information über einen bestimmten Zustand einer Entität encodieren”: Was mag damit gemeint sein?
URI: Die Quellen im Wortlaut#
REDAKTION
Aufzeigen und vorstellen der normativen Quellen, damit man sich nicht mit Zweit- und Drittklassiken-Informationen zufriedengeben muss. … insgesamt bekannt machen mit der normativen Terminologie.
Zunächst werden wir mit einer verwirrenden Vielfalt von Beziehungsbegriffen konfrontiert: identifizieren, benennen, bedeuten, beschreiben, referenzieren und dereferenzieren, Zugang zu und viele mehr. Wir werden die Originalnormen in ihrem Wortlaut betrachten müssen.
Maßgeblich für das Internet sind sogenannte RFC, Requests for Comments:
Ein RFC wie z.B. der RFC 8700 (“Fifty Years of RFCs”) sind an verschiedenen Stellen abrufbar:
Normativ gültig ist die Original-Website RFC-Editor (https://www.rfc-editor.org/about/), Beispiel: https://www.rfc-editor.org/info/rfc8700
Komfortabler nutzbar sind die RFC auf der Homepage der Internet Engineering Task Force (IETF), Beispiel: https://datatracker.ietf.org/doc/rfc8700/
Das sind die wichtigsten Quellen:
- RFC 1630#
Universal Resource Identifiers in WWW, June 1994 (https://www.rfc-editor.org/info/rfc1630)
- RFC 1738#
Uniform Resource Locators (URL), December 1994 (https://www.rfc-editor.org/info/rfc1738)
- RFC 3986#
Uniform Resource Identifier (URI): Generic Syntax, January 2005 (https://www.rfc-editor.org/info/rfc3986)
- RFC 3987#
RFC 3987 Internationalized Resource Identifiers (IRIs), January 2005 (https://www.rfc-editor.org/info/rfc3987)
- RFC 5147#
URI Fragment Identifiers for the text/plain Media Type, April 2008 (https://www.rfc-editor.org/info/rfc5147)
- RFC 7111#
URI Fragment Identifiers for the text/csv Media Type, January 2014 (https://www.rfc-editor.org/info/rfc7111)
Wir betrachten die wichtigsten Ausschnitte dieser RFC im Original und interpretieren sie; Formatierung und Hervorhebungen JB.
TERMINOLOGIE: EN resource ist ungleich DE Ressource, Fehlübersetzung! Aber im Dokument RDF 1.2 wird explizit Synonymie zu RDF 1.2. Semantik resource = entity hergestellt, auf DE also Entität … Wieder ein Begriff der gleichermaßen grundlegend wie undefinierbar ist. Wir folgen hier wieder der Strategie, Wikipedia nach einem unscharfen Konsens anzufragen:
Entität
https://de.wikipedia.org/wiki/Entität_(Informatik)
Als Entität (auch Informationsobjekt genannt, englisch entity) wird in der Datenmodellierung ein eindeutig zu bestimmendes Objekt bezeichnet, über das Informationen gespeichert oder verarbeitet werden sollen. Das Objekt kann materiell oder immateriell, konkret oder abstrakt sein. Beispiele: Ein Fahrzeug, ein Konto, eine Person, ein Zustand.
RFC 1630: URI, URL
https://www.rfc-editor.org/info/rfc1630 (June 1994)
Introduction: This document defines the syntax used by the World-Wide Web initiative to encode the names and addresses of objects on the Internet.
A Universal Resource Identifier (URI) is a member of this universal set of names in registered name spaces and addresses referring to registered protocols or name spaces. A Uniform Resource Locator (URL), defined elsewhere, is a form of URI which expresses an address which maps onto an access algorithm using network protocols. The Uniform Resource Name (URN) debate attempts to define a name space (and presumably resolution protocols) for persistent object names.
T. Berners-Lee, CERN
RFC 1630 ist lediglich ein Memo mit dem Status “RFC - Informational”, allerdings von historischer Bedeutung. Tim Berners-Lee (CERN Genf) definiert als einziger Autor die Syntax von URI und URL im World Wide Web. Als Zweck von URI und URL wird die Kodierung von Namen und Adressen von Objekten im Internet angegeben.
Noch ein Wort zur Verwendung von URL in der deutschen Sprache: IM RFC 1630 wird URL als Acronym für Uniform Resource Locator eingeführt. “URL” wird auf DE oft als “Internetadresse” gelesen (woraus in bestem Denglisch dann die URL folgt) – aber selbstverständlich ist diese Übersetzung nicht. Es handelt sich hier ganz offensichtlich um eine Interpretation, eine erklärende Metapher für etwas technisch Neues.
Der im selben Jahr folgende RFC 1738 hat den Status FRC - Proposed Standard.
RFC 1738: locate vs. access
https://www.rfc-editor.org/info/rfc1738 (December 1994)
Abstract: This document specifies a Uniform Resource Locator (URL), the syntax and semantics of formalized information for location and access of resources via the Internet. [STANDARDS-TRACK]
2. General URL Syntax
Just as there are many different methods of access to resources, there are several schemes for describing the location of such resources.
[…]
URLs are used to ‘locate’ resources, by providing an abstract identification of the resource location. Having located a resource, a system may perform a variety of operations on the resource, as might be characterized by such words as ‘access’, ‘update’, ‘replace’, ‘find attributes’. In general, only the ‘access’ method needs to be specified for any URL scheme.
Authors: T. Berners-Lee (CERN), L. Masinter (Xerox), M. McCahill (University of Minnesota)
RFC 1738 behandelt “Location and access of resources via the Internet”: URLs „lokalisieren“ eine Ressource, indem sie eine abstrakte Identifikation des Ortes der Ressource bereitstellen. Wenn der Ort einer Ressource bekannt ist, kann man verschiedene Operationen auf sie anwenden, insbesondere “access”, auf sie zugreifen. Die genaue Bedeutung von “access” bleibt in diesem Zusammenhang undefiniert. Technisches Wissen lässt es als selbstverständlich erscheinen, dass es darum geht, eine Datei oder eine Nachricht „in die Hand zu bekommen“ und sie mit Hilfe einer Software lesen und weiterverarbeiten zu können.
In den frühen Tagen des Internets bezeichnete resource eindeutig ein digitales Objekt aus dem Internet. Dies ändert sich mit RFC 2396:
RFC 2396, Resource
https://www.rfc-editor.org/info/rfc2396 (August 1998)
Abstract: A Uniform Resource Identifier (URI) is a compact string of characters for identifying an abstract or physical resource. […]
Resource: A resource can be anything that has identity. Familiar examples include an electronic document, an image, a service (e.g., “today’s weather report for Los Angeles”), and a collection of other resources. Not all resources are network “retrievable”; e.g., human beings, corporations, and bound books in a library can also be considered resources.
The resource is the conceptual mapping to an entity or set of entities, not necessarily the entity which corresponds to that mapping at any particular instance in time. Thus, a resource can remain constant even when its content – the entities to which it currently corresponds – changes over time, provided that the conceptual mapping is not changed in the process.
RFC 2396 erweitert den Begriff der Ressource radikal auf Dinge außerhalb des Internets. Als Beispiele werden unter anderem ein elektronisches Dokument und ein gebundenes Buch in einer Bibliothek genannt. Was konkret mit conceptual mapping, der begrifflichen Zuordnung einer resource zu einer Entität, gemeint ist, wird im RFC 2396 nicht ganz klar. Man könnte versucht sein, hier an „Begriff“ und „Gegenstand“ aus dem semiotischen Dreieck zu denken.
Wir kehren zur Eingangsdefinition zurück: “A resource can be anything that has identity.” Welche Auskunft gibt uns RFC 2396 zu den Begriffen Identität oder identifizieren?
Note: Some URI schemes (such as the “ftp” URI scheme specification) use the term “designate” where this document uses “identify.” (WEBARCH, https://www.w3.org/TR/webarch/#identification)
Der RFC 2396 bleibt hier zirkulär:
RFC 2396: Identifier
https://www.rfc-editor.org/info/rfc2396 (August 1998)
Identifier: An identifier is an object that can act as a reference to something that has identity. In the case of URI, the object is a sequence of characters with a restricted syntax.
Having identified a resource, a system may perform a variety of operations on the resource, as might be characterized by such words as ‘access’, ‘update’, ‘replace’, or ‘find attributes’.
Ein Identifier ist ein Objekt, das auf ein anderes Objekt (das eine „Identität“ hat) verweisen, es „referenzieren“ kann. Unklar ist hier, ob der URI selbst die Identität des referenzierten Objekts liefert, oder ob der URI und der Identifier selbst zwei Objekte sind, die wiederum referenziert werden können. Das Problem ergibt sich offensichtlich aus einer Mehrdeutigkeit oder Unklarheit der Begriffe referencing und identify. RFC 2396 ist sich dieser Schwierigkeit bewusst und unterscheidet wie folgt
RFC 2396: URI, URL, and URN
1.2. URI, URL, and URN
A URI can be further classified as a locator, a name, or both.
The term “Uniform Resource Locator” (URL) refers to the subset of URI that identify resources via a representation of their primary access mechanism (e.g., their network “location”), rather than identifying the resource by name or by some other attribute(s) of that resource.
The term “Uniform Resource Name” (URN) refers to the subset of URI that are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable. […]
A URN differs from a URL in that it’s primary purpose is persistent labeling of a resource with an identifier. […]
(Formatierung JB)
Eine ausführliche frühe Diskussion der schon im RFC 2396 sichtbar werdenden Schwierigkeiten diskutiert u.a. David Booth: Four Uses of a URL: Name, Concept, Web Location and Document Instance, https://www.w3.org/2002/11/dbooth-names/dbooth-names_clean.htm (2003).
Der RFC 3986 (January 2005) führt den RFC 2393 fort und hat den Status eines RFC - Internet Standard (STD 66).
RFC 3986: Resource, Identifier
https://www.rfc-editor.org/info/rfc3986
Resource: This specification does not limit the scope of what might be a resource; rather, the term “resource” is used in a general sense for whatever might be identified by a URI. Familiar examples include an electronic document, an image, a source of information with a consistent purpose (e.g., “today’s weather report for Los Angeles”), a service (e.g., an HTTP-to-SMS gateway), and a collection of other resources. A resource is not necessarily accessible via the Internet; e.g., human beings, corporations, and bound books in a library can also be resources. Likewise, abstract concepts can be resources, such as the operators and operands of a mathematical equation, the types of a relationship (e.g., “parent” or “employee”), or numeric values (e.g., zero, one, and infinity).
Identifier: An identifier embodies the information required to distinguish what is being identified from all other things within its scope of identification. Our use of the terms “identify” and “identifying” refer to this purpose of distinguishing one resource from all other resources, regardless of how that purpose is accomplished (e.g., by name, address, or context). These terms should not be mistaken as an assumption that an identifier defines or embodies the identity of what is referenced, though that may be the case for some identifiers. Nor should it be assumed that a system using URIs will access the resource identified: in many cases, URIs are used to denote resources without any intention that they be accessed. Likewise, the “one” resource identified might not be singular in nature (e.g., a resource might be a named set or a mapping that varies over time).
Der RFC 3968 liefert also detailliertere Definitionen zu resource und identifier, ohne allerdings grundlegende Klärung herbeizuführen.
Immerhin wird der Begriff to refer to weiter erklärt.
Vorsicht Terminologie: IM RFC 3986 wird in Abschnitt 4.1 der Begriff “URI reference” definiert: „A URI-reference is either a URI or a relative reference. If the URI-reference’s prefix does not match the syntax of a scheme followed by its colon separator, then the URI-reference is a relative reference.“
Ein relativer URI lässt sich also eindeutig zu einem absoluten URI erweitern. Diese Regeln sind komplex und hier nicht weiter von Bedeutung. Von Bedeutung für unsere Dikussion ist allerding, dass wir im Kontext einer Diskussion um den Begriff der Referenz ein Fachkonzept URI reference vor uns haben, das regelgeleitet einen URI referenziert, der dann andere resources referenziert – nicht unbedingt das, was wir uns von einer didaktisch klaren Darstellung erhoffen. Immerhin können wir die Begriffe URI ref und URI weitgehend synonym betrachten.
Ein erstes Missverständnis besteht gemäß RFC 3986 (Abschnitt 1.2.2) darin, dass URIs nur auf solche Entitäten verweisen können (“refer to”), auf die die Operation “Zugriff” (“access”) sinnvoll anwendbar ist (“accessible resources”). Der URI selbst kann nur identifizieren; aus der Existenz eines URI folgt nicht die Existenz der Entität. Welche Operationen – oft “access”, aber z.B. auch “find attributes” – mit einer Entität im Einzelfall möglich sind, hängt vom Zugriffsprotokoll (z.B. HTTP), vom Datenformat der Entität oder auch vom natürlichsprachlichen Kontext ab, in dem ein URI verwendet wird.
Interessant ist auch, dass neben dem Begriff des Referenzierens die gegensätzlichen Begriffe des Dereferenzierens (englisch für “zurückverfolgen”) und des retrieval (abfragen, abrufen, zurückholen) eingeführt werden:
RFC 3986: to dereference; to retrieve
https://www.rfc-editor.org/info/rfc3986 , Section 1.2.2
URI “resolution” is the process of determining an access mechanism and the appropriate parameters necessary to dereference a URI; this resolution may require several iterations. To use that access mechanism to perform an action on the URI’s resource is to “dereference” the URI. […]
When URIs are used within information retrieval systems to identify sources of information, the most common form of URI dereference is “retrieval”: making use of a URI in order to retrieve a representation of its associated resource. A “representation” is a sequence of octets, along with representation metadata describing those octets, that constitutes a record of the state of the resource at the time when the representation is generated.
Retrieval is achieved by a process that might include using the URI as a cache key to check for a locally cached representation, resolution of the URI to determine an appropriate access mechanism (if any), and dereference of the URI for the sake of applying a retrieval operation. Depending on the protocols used to perform the retrieval, additional information might be supplied about the resource (resource metadata) and its relation to other resources.
Wir widerholen aus dem RFC 2396 einen Teil der Definition von resource, der in dem RFC 2396 etwas rätselhaft schien:
The resource is the conceptual mapping to an entity or set of entities, not necessarily the entity which corresponds to that mapping at any particular instance in time. Thus, a resource can remain constant even when its content – the entities to which it currently corresponds – changes over time, provided that the conceptual mapping is not changed in the process. (RFC 2396)
Wo wird das relevant? Mindestens alle zeitabhängigen Datensätze, erweitert auch auf alle ortsabhängigen Datensätze, paradigmatisch Wetterdaten, im Bereich GovData aber auch SmartCity, Parkhausbelegung, Dauerzählstellen, Müllmengen – tatsächlich sehr viele Daten.
Wo wird es relevant? Mindestens alle zeitabhängigen Datensätze, erweitert auch auf alle ortsabhängigen Datensätze, paradigmatisch Wetterdaten, im Bereich GovData aber auch SmartCity, Parkhausbelegung, Dauerzählstellen, Müllmengen - eigentlich sehr viele Daten.
Der RFC 3986 definiert dazu explizit und eindeutig:
RFC 3986: Indentifikation vs. Interaktion
https://www.rfc-editor.org/info/rfc3986
When URIs are used within information retrieval systems to identify sources of information, the most common form of URI dereference is “retrieval”: making use of a URI in order to retrieve a representation of its associated resource. A “representation” is a sequence of octets, along with representation metadata describing those octets, that constitutes a record of the state of the resource at the time when the representation is generated.
URI references in information retrieval systems are designed to be late-binding: the result of an access is generally determined when it is accessed and may vary over time or due to other aspects of the interaction. These references are created in order to be used in the future: what is being identified is not some specific result that was obtained in the past, but rather some characteristic that is expected to be true for future results. In such cases, the resource referred to by the URI is actually a sameness of characteristics as observed over time, perhaps elucidated by additional comments or assertions made by the resource provider.
T. Berners-Lee (W3C/MIT), R. Fielding (Day Software), L. Masinter (Adobe Systems)
Fragment Identifier#
Fragment Identifiers in RDF
https://www.w3.org/TR/rdf12-concepts/#section-fragID
6. Fragment Identifiers: RDF uses IRIs, which may include fragment identifiers, as resource identifiers. The semantics of fragment identifiers is defined in RFC 3986 [RFC3986]: They identify a secondary resource that is usually a part of, a view of, defined in, or described in the primary resource, and the precise semantics depend on the set of representations that might result from a retrieval action on the primary resource.
In RDF-bearing representations of a primary resource, e.g., https://example.com/foo, the secondary resource identified by a fragment identifier, e.g., bar, is the resource denoted by the full IRI in the RDF graph, which would be https://example.com/foo#bar in this case. Since IRIs in RDF graphs can denote anything, this can be something external to the representation, or even external to the web.
In this way, the RDF-bearing representation acts as an intermediary between the web-accessible primary resource, and some set of possibly non-web or abstract entities that the RDF graph may describe.
RFC 2396, Fragment
https://www.rfc-editor.org/info/rfc2396 (August 1998)
4.1. Fragment Identifier: When a URI reference is used to perform a retrieval action on the identified resource, the optional fragment identifier, separated from the URI by a crosshatch (“#”) character, consists of additional reference information to be interpreted by the user agent after the retrieval action has been successfully completed. As such, it is not part of a URI, but is often used in conjunction with a URI.
In RFC 2396 war das Fragment nicht Teil des URI. Seit dem RFC 3986 gehört das Fragment zur Uri dazu:
RFC 3986 fragment identifier, syntay
https://www.rfc-editor.org/info/rfc3986
3. Syntax Components: The generic URI syntax consists of a hierarchical sequence of components referred to as the scheme, authority, path, query, and fragment.
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
| _____________________|__
/ \ / \
urn:example:animal:ferret:nose
hier-part = "//" authority path-abempty
/ path-absolute
/ path-rootless
/ path-empty
RFC 3986: fragment semantics
https://www.rfc-editor.org/info/rfc3986
3.5. Fragment:
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations.
The semantics of a fragment identifier are defined by the set of representations that might result from a retrieval action on the primary resource.
Individual media types may define their own restrictions on or structures within the fragment identifier syntax for specifying different types of subsets, views, or external references that are identifiable as secondary resources by that media type. If the primary resource has multiple representations, as is often the case for resources whose representation is selected based on attributes of the retrieval request (a.k.a., content negotiation), then whatever is identified by the fragment should be consistent across all of those representations. Each representation should either define the fragment so that it corresponds to the same secondary resource, regardless of how it is represented, or should leave the fragment undefined (i.e., not found).
Zwei URIs mit demselben primären Ressourcenteils (z. B. Schema, Host, Pfad, Query) und unterschiedlichen Fragment-Identifiers sind verschiedene URIs – denn das Fragment ist Teil der URI.
Die Semantik des Fragments wird durch den Mime-Type des Antwort-Dokuments bestimmt:
Bei einem html-Dokument wird das XML-Element mit der id=fragment identifiziert
betrachtet man ein XML-Dokument als Datei (Manifesttaion), ist das ein Datei-Abschnitt
betrachtet man ein XML-Dokument als DOM-Tree (Expression), ist das ein Teilbaum
Bei einem elektronisch als pdf vorliegenden print-Dokument wird XXXXX ausgwählt.
Bei einem CSV-Dokument wird ein Record ausgewählt, s.u. XXXXXXXXX.
Was wird bei einem RDF-Dokument ausgewählt? siehe unten, XXXXX
Begriff fragment ist nicht gut gewählt … Zitat TBL … kein Problem: wir verstehen “Teil” einfach sehr breit, metaphorisch … viel relevanter ist allerdings: Ist eine Teil einer Expression oder einer Manifestation gemeint?
Fragment.html
https://www.w3.org/DesignIssues/Fragment.html
Formally, the URI does include the fragment ID)
In practice, you can divide the processing which occurs when following a link using HTTP into three steps:
The client figures out which server to contact by parsing part of the URL, and sends the URL as a request to the server;
The server figures out which object is referred to by parsing the rest of the URL, and returns some rendition of it to the client;
The client presents all or part of the object to the user
The last part typically involves finding some software class which can handle the given MIME type, and passing it the data stream. At the same time, the fragment identifier is passed as a parameter to the created object.
Axiom: The significance of the fragment identifier is a function of the MIME type of the object. This means that the fragment id is opaque for the rest of the client code. The HTTP engine cannot make any assumptions about it. The server is not even given it.
cooluris, Sect. 4.1.: Hash URIs
https://www.w3.org/TR/cooluris/#hashuri
There are two solutions that meet our requirements for identifying real-world objects: 303 URIs and hash URIs. [….] The first solution is to use “hash URIs” for non-document resources. URIs can contain a fragment, a special part that is separated from the rest of the URI by a hash symbol (“#”).
When a client wants to retrieve a hash URI, then the HTTP protocol requires the fragment part to be stripped off before requesting the URI from the server. This means a URI that includes a hash cannot be retrieved directly, and therefore does not necessarily identify a Web document. But we can use them to identify other, non-document resources, without creating ambiguity.
#fragid
https://www.w3.org/TR/webarch/#fragid
Story. When browsing the XHTML document that Nadia receives as a representation of the resource identified by “http://weather.example.com/oaxaca”, she finds that the URI “http://weather.example.com/oaxaca#weekend” refers to the part of the representation that conveys information about the weekend outlook. This URI includes the fragment identifier “weekend” (the string after the “#”).
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations. The terms “primary resource” and “secondary resource” are defined in section 3.5 of [URI]. (sect-uri-fragment-rfc3986-fragment)
Übersicht über die Semantik von Fragment Identifier: https://en.wikipedia.org/wiki/URI_fragment, für die Mime-Types text/plain, text/html, XML, text/csv, RDF, JavaScript, JSON, application/pdf, SVG
RFC 1866: Fragment Identifiers
https://datatracker.ietf.org/doc/html/rfc1866#section-7.4 (1995)
The meaning of fragment identifiers depends on the media type of the representation of the anchor’s resource. For `text/html’ representations, it refers to the element with a NAME attribute whose value is the same as the fragment identifier. The matching is case sensitive. The document should have exactly one such element. The user agent should indicate the anchor element, for example by scrolling to and/or highlighting the phrase.
Aus den Frühzeiten des Internets: Eine Fragment in HTML 2 (Jahr 1995!) indentifizert ein Element; “Element” ist aber ein Begriff, der sich auf die logische Struktur (und nicht das konkrete Format) eines html-Dokuments bezieht – also Expressions-Ebene. … HTML 2 ist in SGML definiert (RFC 1866 Sect. 9.5. SGML Declaration for HTML), “HTML documents are SGML documents” (RFC 1866 Abstract) …
Terms. SGML document: A sequence of characters organized physically as a set of entities and logically into a hierarchy of elements. An SGML document consists of data characters and markup; the markup describes the structure of the information and an instance of that structure. ()
rfc7111 (January 2014)
RFC 7111 https://www.rfc-editor.org/info/rfc7111 (January 2014)
Abstract: This memo defines URI fragment identifiers for text/csv MIME entities. These fragment identifiers make it possible to refer to parts of a text/csv MIME entity identified by row, column, or cell. Fragment identification can use single items or ranges.
1.2. Why text/csv Fragment Identifiers?
URIs are the identification mechanism for resources on the Web. The URI syntax specified in RFC 3986 [RFC3986] optionally includes a socalled “fragment identifier”, separated by a number sign (“#”). The fragment identifier consists of additional reference information to be interpreted by the client after the retrieval action has been successfully completed.
The semantics of a fragment identifier is a property of the media type resulting from a retrieval action, regardless of the URI scheme used in the URI reference. Therefore, the format and interpretation of fragment identifiers is dependent on the media type of the retrieval result.
prefix, QName, CURIE, URI ref#
REDAKTION
Nur syntaktischer Zucker – oder mehr? Auflösen eines URI ref
In der XML-Welt gibt es den https://en.wikipedia.org/wiki/QName, Speziallfall von https://de.wikipedia.org/wiki/CURIE … insbesondere relevant für RDF/XML und allgemein XML-Manifestationen … die Serialisierung Turtle verwendet eine allgemeinere Form von qnames, mithin CURIS (TBD: prüfen!):
https://www.w3.org/TR/turtle/#relative-iri:
Prefixed names are a superset of XML QNames. They differ in that the local part of prefixed names may include:
leading digits, e.g. leg:3032571 or isbn13:9780136019701
non leading colons, e.g. og:video:height
reserved character escape sequences, e.g. wgs:lat-long
URI: A specific, complete identifier.
URI Reference: A more general term that could be either an absolute or a relative URI … https://datatracker.ietf.org/doc/html/rfc3986#section-5
httpRange-14#
REDAKTION
Hier eine möglichst knappe Zusammenfassung … ausführliche Diskussion siehe httpRange-14: Quellen:
HTTPRange-14
https://en.wikipedia.org/wiki/HTTPRange-14
httpRange-14 is a long-running logical conundrum or design problem in the semantic web. The problem arises because when HTTP is extended from referring only to documents to talking about real-world things (planets, flowers, emotions, Platonic forms, etc) the domain of HTTP GET becomes undefined
The HTTP protocol was originally designed to transfer information objects, specifically Hypertext such as HTML. The GET request was issued by a client to retrieve data at a particular URL. […] The semantic web […] used URLs to refer to real world things (planets, flowers, emotions, Platonic forms, etc) which could not be reduced to network streams. The question of what web servers should do when asked for one of these things arose.
The impact of the issue (more correctly the impact of confusion around the issue) is greatest in semantic web communities whose models involve large numbers of abstract concepts which cannot be serialised, such as the FRBR community.[8] ([])
Originalposts:
Problem: TAG Issues List (historisch), dort Issue Nr. 14, Benennung httpRange: https://www.w3.org/2001/tag/issues.html#httpRange-14
Lösung Originapost: https://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html
httpRange-14: What is the range of the HTTP dereference function?
https://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html
TBL’s argument the HTTP URIs (without “#”) should be understood as referring to documents, not cars.
httpRange-14 Resolved
https://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html
As everyone here knows, the TAG has spent a great deal of time discussing the httpRange-14 issue, as described at
I am happy to report that we came up with a reasonable compromise solution at the recent TAG f2f meeting at MIT.
<TAG type=”RESOLVED”>
That we provide advice to the community that they may mint “http” URIs for any resource provided that they follow this simple rule for the sake of removing ambiguity:
a) If an “http” resource responds to a GET request with a 2xx response, then the resource identified by that URI is an information resource;
b) If an “http” resource responds to a GET request with a 303 (See Other) response, then the resource identified by that URI could be any resource;
c) If an “http” resource responds to a GET request with a 4xx (error) response, then the nature of the resource is unknown.
</TAG>
I believe that this solution enables people to name arbitrary resources using the “http” namespace without any dependence on fragment vs non-fragment URIs, while at the same time providing a mechanism whereby information can be supplied via the 303 redirect without leading to ambiguous interpretation of such information as being a representation of the resource (rather, the redirection points to a different resource in the same way as an external link from one resource to the other).
Die normativ gültige Antwort issue-14-resolved lautet also: Wenn ein URI wie z.B. <https://de.wikipedia.org/wiki/ XXX Te Dedum> auf eine Anfrage beim entsprechenden Server (hier z.B. https://de.wikipedia.org/ ) eine Datei zurückgibt, dann “denotiert” der URI nicht etwa das Werk (hier: die Komposition) von XXXXX Werk (oder in unserem Beispiel ein gänzlich anderes Werk der Wikipedia-Community, das XXXX Werk genauer beschreibt), sondern genau die information resource … das ist eine Oktett-Folge, en: octet stream, die der Webserver zurückgibt. … Response 303 … Und wenn der Server die Datei nicht kennt und den Statuscode *HTTP 404: Not Found” zurückgibt, dann können wir nicht wissen, was denotiert wird.
Diese technische Lösung ist mit allerlei Schwierigkeiten behaftet, Diskussion siehe httpRange-14: Quellen … Essentials aus dieser Diskussion:
REDAKTION
hier viele Entities aufzeigen, die ein URI „denotieren“ kann … es wird klar werden, dass Begriffe und ihre Zusammenhänge nebulös sind, und eine allgemein befriedigendere Antwort nicht gefunden werden konnte … unser Thema: Metadaten; hier verfügen wir hier über eingeführte Terminologien und Ontologien, unter anderem Dublin Core, DCAT und auch FRBR WEMI … Aufgabe: Reduziere Mehrdeutigkeiten, schärfe Begriffe im speziellen Gegenstandsbereich Metadaten durch Bezugnahme auf solche Terminologien.
verschiedene, sich ergänzende Lösungen:
Unterscheidung Slash-URI vs. Hash-URI: Gute empfohlene Praxis, aber nicht alle halten sich daran – wir empfehlen, es zu tun, und tun es auch selbst; Typ von Hash-URIs ist weiterhin mehrdeutig, weil keine weitere Differenzierung von non information resources erlaubt; Lösungen:
explizite Typ-Deklaration aller Hash-Uris
Erschließung des Typs und ggf. auch semantische Desambiguierung von (hash- und slash-) URIs durch Duck-Typing, Typ-Klassifikation
httpRange-14: Quellen#
REDAKTION
Das folgende Kapitel stellt im Detail die damit verbundenen Probleme und mögliche Lösungsansätze vor.
mehr zum Problem:
https://www.w3.org/2002/11/dbooth-names/dbooth-names_clean.htm
http://www.jenitennison.com/2011/07/05/what-do-uris-mean-anyway.html
https://vos.openlinksw.com/owiki/wiki/VOS/VirtDeployingLinkedDataGuide_Introduction#AncmozTocId21938
https://www.w3.org/2001/tag/2008/02/RepresentationResources.html
- issue-14#
Issue-14: What is the range of the HTTP dereference function? W3C Technical Architecture Group, 2002-2005. (See http://www.w3.org/2001/tag/group/track/issues/14.)
- issue-14-resolved#
Roy Fielding. [httpRange-14] Resolved. Email to www-tag list, 2005. (See http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html.)
- HttpRedirections-57#
ISSUE-57: Mechanisms for obtaining information about the meaning of a given URI. Mechanisms for obtaining information about the meaning of a given URI. https://www.w3.org/2001/tag/group/track/issues/57
- Issue 62#
UniformAccessToMetadata-62, ISSUE-62: Uniform Access to Server-provided Metadata, https://www.w3.org/2001/tag/group/track/issues/62
- issue 63#
metadataArchitecture-63, ISSUE-63: Metadata Architecture for the Web, https://www.w3.org/2001/tag/group/track/issues/63
Dan Connolly#
Dan Conolly: A Pragmatic Theory of Reference for the Web (2006), [] 1. AN ANALYSIS OF HTTPRANGE-14
Berners-Lee also argued that properties are not documents: […] Berners-Lee was unable to persuade a critical mass of the TAG to accept this position. The utility of the dublin core vocabulary was apparent and the argument against its use of hashless HTTP URIs included few practical consequences. Plus, the constraint seems to encroach on the very important principle of opacity of URIs. Any general-purpose algorithm for finding out the nature of a resource starting from only its URI is a constraint on how URIs are minted.
Meanwhile, the DCMI showed some willingness to cooperate with those who hold that RDF Properties and web pages are disjoint; they arranged for HTTP redirections [11], rather than 200 OK repsonses, in reply to GET requests to http://purl.org/dc/elements/1.1/title.
It is stipulated by all parties in the httpRange-14 discussion that in this case, the
hello world.body of type text/plain is a representation of http://site.example/ path. []
Berners-Lee [ agreed] that the term document is misleading. The TAG coined the term Information Resource. The term is not completely defined, but the 15 Jun 2005 decision of the TAG to address httpRange-14 says …
Advice: Use Hash Uris for Properties and Classes. Some argue that “Using # [in this way] makes it impossible to make assertions about parts of documents (e.g. Person A authored Section #3).”[1]. Indeed, this is a concern. Let’s consider it formally, using FRBR[18], [19]. […] I suggest adopting
w:InformationResource rdfs:subClassOf frbr:Workas a practical constraint.
Hayes Ontologie#
Steve Pepper [34] expresses a similar difficulty about the use of URIs for identifying all kinds of entities. In particular, he proposes to associate a resource to a document, whose content describes the subject of the resource (i.e., a subject indicator). Nevertheless, this solution leaves the responsibility of interpreting the identity of a resource to a human agent, and there is no way to ensure that the subject indicator refers to a single subject. LESEN: presutti2008-IdentityResourcesEntitiesWeb
In essence, these assertions that I have provided give you a model that I have endorsed, to enable you to make use of my URI in applications, whether this model is expressed formally in RDF or informally in English. ([Boo06], http://dbooth.org/2006/identity/)
Kommentar TBL: https://www.w3.org/DesignIssues/Ambiguity.html
Identity of Resources and Entities (Gangemi)#
[]
[]
Presutti#
Valentina Presutti and Aldo Gangemi: Identity of Resources and Entities on the Web
presutti2008-IdentityResourcesEntitiesWeb: [] (https://www.researchgate.net/publication/220123871_Identity_of_Resources_and_Entities_on_the_Web)
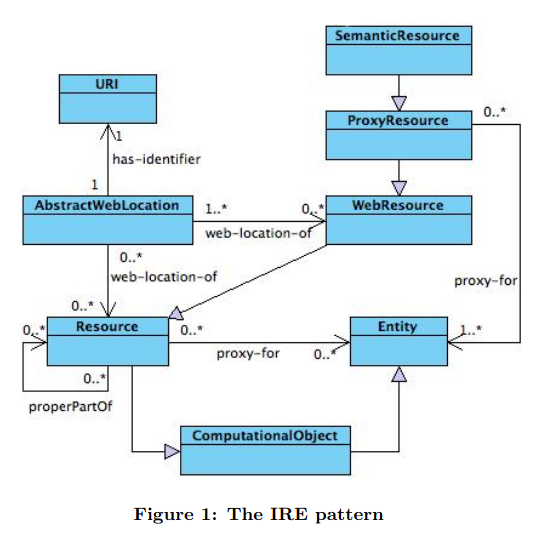
4 The IRE metamodel. Referencing is analyzed in the IRE design by assuming four layers. These layers distinguish the types of things in the domain of the web referencing problem: URI, web resource, information object, and entity, as shown in Figure 2. An example of layering is the following: the URI “http://www.w3.org” identifies a file (a web resource), stored on a W3C server that is accessed when the above URI is resolved; the file is made up of e.g. linguistic or XHTML information (a set of information objects); that information is about the actual W3C organization (a real world entity).
We say that a web resource realizes some information object. The realizes relation is the same that holds for example between a poem (an information object) and the printed book containing it (its realization). Consider also that same poem as realized by a web document: it would be a different occurrence of the realizes relation for that same information object.
Abbildungen:
presutti2008-IdentityResourcesEntitiesWeb_fig8.png
presutti2008-IdentityResourcesEntitiesWeb_fig9.png
Given the above, at least foour possible interpretations of the intended meaning of the term “resource” emerge. (p4)
computational object
conceptual mapping
proxy
entity
AbstractWebLocation
Resource
WebResource
ProxyResource
SemanticResource
the relation proxyFor can be of four types, and that each of them can be treated in a different way.
resolvable proxy for
approximate proxy for
informal exact proxy for
formal exact proxy for
2009halpin-SolvingIdentityCrisisWeb#
2009halpin-SolvingIdentityCrisisWeb: [HP09] (https://link.springer.com/content/pdf/10.1007/978-3-642-02121-3_39.pdf)
Hint
2.1 Two Viewpoints:
direct reference position […] a URI identifies whatever it was intended by the owner to identify […] the referent is generally considered to be some individual unambiguous single thing like the Eiffel Tower or the concept of unicorns […] This viewpoint is the one generally held by many Web architects, like Berners-Lee, who imagine it holds not just for the Semantic Web, but the entire Web
The second position, the logicist position, holds that for the Semantic Web, a URI refers to whatever model(s) – including actual things – that satisfy the formal semantics of the Semantic Web. Adherents of this position hold that the referent of a URI is almost always ambiguous, as many different models can satisfy an interpretation of a RDF graph. This position has been championed extensively against Berners-Lee by Hayes, as Hayes believed that the direct ref- erence position “doesn’t make sense, that it isn’t true, and that it could not possibly be true” as it contradicts the standard interpretation of Tarski-style formal semantics [16]. A URI has no identity in and of itself, but only in the context of its use in a graph or, in a minor variation argued for by Parsia and Patel-Schneider, the explicit use of owl:imports [23]. This position is generally held by those who claim that the Semantic Web is entirely distinct from the hypertext Web. (p. 524)
Hint
2.2 The TAG’s Resolution
The TAG officially resolved httpRange-14 by saying that the 303 See Other HTTP header can serve to disambiguate between information resources and possible non-information resources. The official resolution to Identity Crisis by the TAG is given below as [13] []:
If an HTTP resource responds to a GET request with a 2xx response, then the resource identified by that URI is an information resource;
If an HTTP resource responds to a GET request with a 303 (See Other) response, then the resource identified by that URI could be any
If an HTTP resource responds to a GET request with a 4xx response, then the nature of the resource is unknown.
Abbildung:
2009halpin-SolvingIdentityCrisisWeb_fig2.png
halpin2010-WhenOwlSameAsIsntTheSame#
[] https://link.springer.com/content/pdf/10.1007/978-3-642-17746-0_20.pdf
[] http://arxiv.org/abs/1907.10528 > http://arxiv.org/pdf/1907.10528
[] https://link.springer.com/chapter/10.1007/978-3-319-25591-0_4
Abbildung:
halpin2010-WhenOwlSameAsIsntTheSame_fig1.png
hayes2008-DefenseAmbiguity#
hayes2008-DefenseAmbiguity: [] (https://www.researchgate.net/profile/Patrick-Hayes-4/publication/220123887_In_Defense_of_Ambiguity/links/0c96052937ca9dce17000000/In-Defense-of-Ambiguity.pdf)
Kommentar von TBL: https://www.w3.org/DesignIssues/Ambiguity.html
RDF#
Warnung: w3c/EasierRDF
RDF im Detail#
Metadaten-Modell (z.B. DCAT) vs. Meta-Datenmodell (RDF); rekursive selbstreferentielle Definitionen von Meta-Datenmodellen: Die Spec von RDF hat “RDF im Kopf”
Material:
RDF 1.2 Spec auf Papier ausgedruckt, ersatzweise in einem pdf-Reader mit Annotationsmöglichkeit (lediglich ein Smartphone reicht nicht)
Wir lesen Teile des Textes im Detail, und verstehen ihm im Idealfall vollständig.
Ergebnissicherung:
mindestens eine Graph-Visualisierug
später dann ggf. auch eine GenDifS-Mindmap ähnlich http://jbusse.de/gendifs/x_denny_vrandecic_ontology_evaluation.html
Einzelne Unterrichts-Sitzungen, die idealerweise teilnehmeraktivierend als moderierte Gruppenarbeit durchgeführt werden könnten.
Grundlagen:
[], Chapter 3 RDF—The basis of the Semantic Web https://dl.acm.org/doi/10.1145/3382097.3382101
Abstrakter und konkreter RDF Graph#
Quelle: https://www.w3.org/TR/rdf11-concepts/
in der RDF 1.1 Spec haben wir die Definition eines (RDF-) Dokument:
1.8 RDF Documents and Syntaxes. An RDF document is a document that encodes an RDF graph or RDF dataset in a concrete RDF syntax, such as Turtle [TURTLE], RDFa [RDFA-PRIMER], JSON-LD [JSON-LD], or TriG [TRIG]. RDF documents enable the exchange of RDF graphs and RDF datasets between systems. (https://www.w3.org/TR/rdf11-concepts/#rdf-documents)
A concrete RDF syntax may offer many different ways to encode the same RDF graph or RDF dataset, for example through the use of namespace prefixes, relative IRIs, blank node identifiers, and different ordering of statements. While these aspects can have great effect on the convenience of working with the RDF document, they are not significant for its meaning.
Es liegt nahe, in dieser Spec auch nach so etwas wie einer abstrakten RDF-Syntax zu suchen. Wir werden fündig:
Abstract. The Resource Description Framework (RDF) is a framework for representing information in the Web. This document defines an abstract syntax (a data model) which serves to link all RDF-based languages and specifications. The abstract syntax has two key data structures: RDF graphs are […]. RDF datasets are […] (https://www.w3.org/TR/rdf11-concepts/#abstract)
The core structure of the abstract syntax is a set of triples, each consisting of a subject, a predicate and an object. A set of such triples is called an RDF graph. (https://www.w3.org/TR/rdf11-concepts/#data-model)
Wer FRBR kennt, erkennt hier die gesuchte Unterscheidung zwischen Expression und Manifestation wieder:
Ein RDF-Dokument wird im wesentlichen durch eine konkrete Syntax, durch ein Format beschrieben, und entspricht damit dem Manifestations-Aspekt einer webarch:representation
Ein RDF-Graph (resp. ein RDF-Dataset) wird in RDF als ein Datenmodell eingeführt, ist eine Menge von RDF-Tripeln (resp. RDF-Graphen), die einer abstrakten Syntax gehorchen, und entspricht damit dem Expressions-Aspekt einer webarch:representation
Wenn RDF ein Datenmodell ist: Dann kann man einen RDF-Graphen als ein Modell verstehen, und zwar hier eine frbr:Werkes. das ursprüngliche frbr:WEMI stellt sich uns nun so dar:
Werk – Werk
Expression – Modell als ein rdf:Datset von rdf:Graphs
Manifestation – eine Message, z.B. als ein rdf11:rdfDocument, Ergebnis einer SPARQL-Query etc.
Wer will, kann diese Gegenüberstellung auch nutzen, um die entsprechenden FRBR-Begriffe aus frbr:wemi neu zu fassen?
Nachtrag: Auch der Begriff Datenmmodell hat 2 Bedeutungen:
Overview. The term data model can refer to two distinct but closely related concepts. Sometimes it refers to an abstract formalization of the objects and relationships found in a particular application domain: for example the customers, products, and orders found in a manufacturing organization. At other times it refers to the set of concepts used in defining such formalizations: for example concepts such as entities, attributes, relations, or tables. So the “data model” of a banking application may be defined using the entity–relationship “data model”. This article uses the term in both senses. (https://en.wikipedia.org/wiki/Data_model#Overview)
Die RDF 1.1 Spec stellt ein Datenmodell im zweiten Sinn dar.
Named Graphs#
[] https://www.researchgate.net/publication/270897734_A_Methodology_for_Citing_Linked_Open_Data_Subsets
Neues Problem: mit WEMI geht davon aus, dass die Items, auf die wir zugreifen, Dateien sind … was aber, wenn wir auf Teile von Dateien zugreifen wollen? … denn über eine Admonitionertürt bekommt auch der Fragment-Identifier eine Bedeutung: kennzeichnet in html und XML einen Abschnitt eines Dokuments … davon abgeleitet auch in RDF/XML? … aber in RDF/Turtle etc?
Neues Problem: in RDF spielen Dateien eigentlich keine Rolle; unter der Hand werden der Begriff der Datei und des Knowledge Graphs in in RDF 1.0 (JB: prüfen!) einfach gleichgesetzt … das suggerieren auch die LOD-Regeln von TBL … in RDF 1.1 wurden named Graphs eingeführt; in RDF 1.2 können wir sogar einzelne Tripel annotieren … neues Semiotisches Problem: ein URI kann auch einen Named Graph denotieren – das ist sehr abstrakt, nur für „Tekkies“ verständlich, aber so weit müssen wir in dieser Darstellung schon gehen.
Request_for_Comments
https://de.wikipedia.org/wiki/Request_for_Comments
Die Requests for Comments (RFC; englisch für „Bitte um Kommentare“) sind eine Reihe technischer und organisatorischer Dokumente zum Internet (ursprünglich Arpanet), die seit dem 7. April 1969 vom RFC-Editor herausgegeben werden. Handelte es sich ursprünglich um im Wortsinne zur Diskussion gestellte Dokumente, so findet die Diskussion heute während der Erstellung der Entwürfe statt, sodass ein veröffentlichtes RFC in der Regel eine begutachtete technische Spezifikation darstellt.[https://datatracker.ietf.org/doc/html/rfc8700]