Offene Daten#
Das Denken des Menschen ist unergründlich. Manchmal können wir es beobachten, wenn der Mensch spricht. Vor ca. 4000 Jahren erfanden die Sumerer die Schrift; Schreiben war ein Alleinstellungsmerkmal des Menschen. 1941 baute Konrad Zuse mit der [Z3] (https://de.wikipedia.org/wiki/Zuse_Z3) den ersten funktionsfähigen binären Computer der Welt; seitdem können Computer auch rechnen. Im Jahr 2020 stellte OpenAI das Sprachmodell Generative Pre-trained Transformer 3 (GPT-3) der Öffentlichkeit zur Verfügung; seitdem gibt es Maschinen auf der Welt, die schreiben können, ohne zu denken. Die Digitalisierung erzeugt Myriaden digitaler schriftbasierter Artefakte in Form von Daten. Einige davon sind „offen“. Was bedeutet das genau?
Offene Daten im weitesten Sinne sind Daten, die erstens in geeigneten Formaten vorliegen und zweitens auch tatsächlich genutzt werden dürfen. Im Begriff der offenen Daten kommen also technische Standards und Lizenzfragen zusammen. Der Begriff geht zurück auf eine Publikation der gemeinnützigen Organisation [Open Knowledge Foundation (OKF)] (https://okfn.org/en/) aus dem Jahr 2016, in der aktuellen Fassung veröffentlicht unter https://opendefinition.org/:
Open Definition
https://opendefinition.org/od/2.1/en/
Knowledge is open if anyone is free to access, use, modify, and share it — subject, at most, to measures that preserve provenance and openness. […] This essential meaning matches that of “open” with respect to software as in the Open Source Definition and is synonymous with “free” or “libre” as in the Free Software Definition and Definition of Free Cultural Works.
Primärer Gegenstand dieses Büchleins sind Metadaten zu Offenen Daten: Metadaten zu Dokumenten; zu Messdatenreihen in Produktion, Umwelt, Smart City; zu Datenbanken in Wissenschaft und Verwaltung; etc. Vor der Digitalisierung kümmerte sich in wissenschaftlichen Bibliotheken die Abteilung Formale Erschließung um eine adäquate Metadatenhaltung, für analoge Bücher, Aufsätze, Zeitschriften sind die Metadatenstrukturen gut verstanden und geregelt. Für die Welt der digitalen Artefakte stellen sich neue Fragen: Wie beschreiben wir in den Metadaten, was in einem Dokument, einem Datensatz, einem Messdatenstrom beschrieben wird? In welchen abstrakten Datenmodellen und konkreten Formaten sind die Beschreibungen der Daten und der Metadaten organisiert? In welchem Verhältnis stehen verschiedene Beschreibungen zueinander: Wie (un)vollständig sind sie? Wo ergänzen sich Teilmodelle, wo konkurrieren sie? Wie werden Widersprüche aufgelöst? Welche Arten der Identifikation, Benennung, Bezeichnung, Adressierung, Beschreibung von digitalen und analogen Objekten kommen in den Daten vor und was bedeuten sie?
Gegeben seien z.B. die folgenden Aussagen:
https://wetter.etwi.haw-landshut.de/ zeigt heute gutes Badewetter an (Worum geht es, Thema, “Subject”)
https://wetter.etwi.haw-landshut.de/ zeigt den Wind in der Einheit m/sec an (Eigenschaft des Wetter-Modells)
https://wetter.etwi.haw-landshut.de/ ist eine html-Datei (Eigenschaft der Datei)
Aussage 1 bezieht sich auf den Inhalt der Seite; Aussage 2 beschreibt Eigenschaften des symbolischen Modells, das von der Datenquelle geliefert wird; und Aussage 3 schließlich bezieht sich auf die technische Kodierung des Modells in einer Antwort auf eine http-Anfrage. Für den “Endnutzer” eines Wetterdienstes sind solche Unterscheidungen irrelevant, vielleicht sogar störend. Für eine Datenbibliothek, die Quellen von Wetterdaten professionell erschließt, sind solche Unterscheidungen lebenswichtig.
Metadaten zu digitalen Objekten werden heute überwiegend im abstrakten Datenmodell [Resource Description Framework (RDF)] (https://de.wikipedia.org/wiki/Resource_Description_Framework) ausgetauscht. Im RDF wird ein Objekt der analogen und digitalen Welt durch einen Uniform Resource Identifier (URI) “denotiert”. Die Datenschemata und Vokabulare werden in RDFS und OWL modelliert. Alles wird durch die Technik und Logik des Semantic Web zusammengehalten.
Wer sich mit Metadatenverwaltung beschäftigt, muss als Grundlage verstehen, wie RDF, RDFS, das Semantic Web und die zugehörigen Modelle funktionieren. Die syntaktischen und technischen Aspekte wie abstraktes Datenmodell, Formate, Abfragen mit SPARQL gehören zum Standardwissen der Informatik. Aspekte der formalen Semantik von Ontologiesprachen wie insbesondere OWL sind nur noch spezialisierten Mathematikern zugänglich. Die Bedeutung der in RDF verwendeten Zeichen und Symbole, insbesondere der URIs, ist bis heute nur unzureichend geklärt: Was ist gemeint, wenn die Spezifikation von RDF 1.2 in den einleitenden Absätzen schreibt: “Any IRI or literal denotes something in the world”, aber den auch im Original hervorgehobenen Begriff der Denotation nicht weiter erläutert?
Politische Rahmenbedingungen: z.B. GovData#
Portal:
Doku:
Verantwortliche Institution:
Für uns interessant auch: “Vollständig”
naiv: es sind alle verfügbaren Messwerte, Records etc. dabei (wurden erhoben, nicht entfernt etc.)
auch: auch das Datenschema ist dabei … und das ist i.A. nicht der Fall, wenn man nur eine CSV-Datei hat.
LOGD
mehrere Sitzungen zu Gesetzesgrundlagen, politischen Rahmenbedigungen etc., incl. Präsentationen der Studierenden
Wikipedia und Derivate#
Wikipedia, die vielleicht größte Enzyklopädie der Welt, ist ein hervorragendes und prominentes Beispiel für Open Data. Wie in der Einleitung beschrieben, dient sie in unserer Theoriebildung als erster Einstiegspunkt und zur Dokumentation von (ggf. zu korrigierendem) Konsens, gerade und vor allem auch bei problematischen Begriffen. Hier steht der Inhalt – in der WEMI-Terminologie die Werkebene – ausgewählter Wikipedia-Artikel im Vordergrund.
Wir verwenden Wikipedia in diesem Text immer dann, wenn wir schwierige Begriffe verwenden, die wir selbst nicht auf andere Begriffe zurückführen können, die wir selbst schon ausreichend geklärt haben. Warum sollten wir uns die Mühe machen, selbst eine “eigene” Erklärung für einen komplexen Begriff zu finden, wenn Wikipedia diesen Begriff bereits gut definiert und zusätzlich mit anderen Begriffen vernetzt? Ein zustimmendes Zitat aus der Wikipedia dient auch dazu, das eigene Netz von Begriffen und Schnittpunkten in der Argumentation quasi an einigen Textbezugspunkten zu „verankern“, die man sich eben nicht selbst ausgedacht hat.
Natürlich darf man Konsens nicht mit Wahrheit verwechseln, oft genug ist das Gegenteil der Fall. Manche Begriffe, die wir in unserer Argumentation zunächst als Wikipedia-Konsens betrachten, werden wir fachlich schärfen müssen. Andere Ausgangspunkte der Wikipedia werden sich als irreführend erweisen, wir werden sie korrigieren müssen. Gerade in solchen Fällen ist es erlaubt, ja geboten, von Wikipedia auszugehen: Erst in der Differenz zwischen – ungenauem, manchmal irreführendem – Konsens und neuem, geschärftem Begriffsverständnis wird der Unterschied zwischen einer bestimmten neuen und einer zu korrigierenden alten Position sichtbar. Und bei einer dritten Klasse von Begriffen – etwa dem Begriff des Zeichens oder auch der Semiotik – bleiben wir beim ungenauen Konsens. Mit dem Zitat aus der im wissenschaftlichen Kontext eigentlich als “nicht zitierfähig” gebrandmarkten Wikipedia geben wir zu erkennen, dass wir uns bei diesem Begriff auf ein in Wikipedia dokumentiertes Begriffsverständnis stützen, ohne dieses vertieft zu problematisieren.
Im Kontext von Linked Open Data ist Wikipedia nicht nur für Menschen, sondern auch für Maschinen als Datenlieferant interessant: Die schiere Menge an Text kann maschinell gelesen, verarbeitet, ausgewertet und zu neuem Text zusammengesetzt werden. Wikipedia liefert uns offene Textdaten vom Feinsten. Natürlich ist Wikipedia auch eine primäre Quelle für Large Language Models (LLM). Bei dieser Verwendung interessiert nicht der intellektuelle Inhalt der Seiten (der ohnehin nur von Menschen verstanden werden kann, Werkebene), sondern der Text, die Wörter, das Netz von Verknüpfungen etc.
Ein bekanntes Verfahren, um einen Text mit einigen Schlagworten zu versehen, die möglicherweise gar nicht im Text selbst enthalten sind, geht so: Gegeben seien unser eigener Text und eine einzelne Wikipedia-Seite. Die Ähnlichkeit der beiden Texte ergibt sich aus der Anzahl der gemeinsamen Wörter geteilt durch die Anzahl aller Wörter in beiden Texten. Je mehr Wörter beide Texte gemeinsam haben, desto höher ist die Ähnlichkeit. (Technisch gesehen werden wir die Texte vorher normalisieren, Stammformen bilden, Stoppwörter entfernen usw., aber das Prinzip ändert sich nicht). Nehmen wir nun unseren eigenen Text und die 100.000 wichtigsten Wikipedia-Artikel. Es gibt effiziente Algorithmen, um die Textähnlichkeit unseres eigenen Textes mit jedem (!) einzelnen Wikipedia-Artikel zu berechnen.
Wikipedia ist mehr als ein Wiki. Wikipedia ist vielleicht die bekannteste, aber bei weitem nicht die einzige interessante Quelle offener Daten, die uns die gemeinnützige Organisation Wikimedia Foundation zur Verfügung stellt. Ebenfalls als Wiki angelegt ist z.B. die Plattform Wikimedia Commons, auf der audiovisuelle Medien – vor allem Bilder – als Wiki mit Metadaten und beschreibendem Text so abgelegt sind, dass sie leicht in Wikipedia eingefügt werden können.
Für die maschinelle Wissensverarbeitung noch interessanter sind Plattformen wie die Wikimedia-Plattform [Wikidata] (https://www.wikidata.org/), ein Wiki, in dem Benutzer Daten bereitstellen können. Einen Überblick über alle Wikis der Wikimedia Foundation bietet das Meta-Wiki https://meta.wikimedia.org/wiki/Main_Page. Wie bei allen Projekten der Wikimedia Foundation können die Daten nicht nur in verschiedenen Formaten heruntergeladen werden, sondern mit einem SPARQL-Endpoint auch als RDF abgefragt werden.
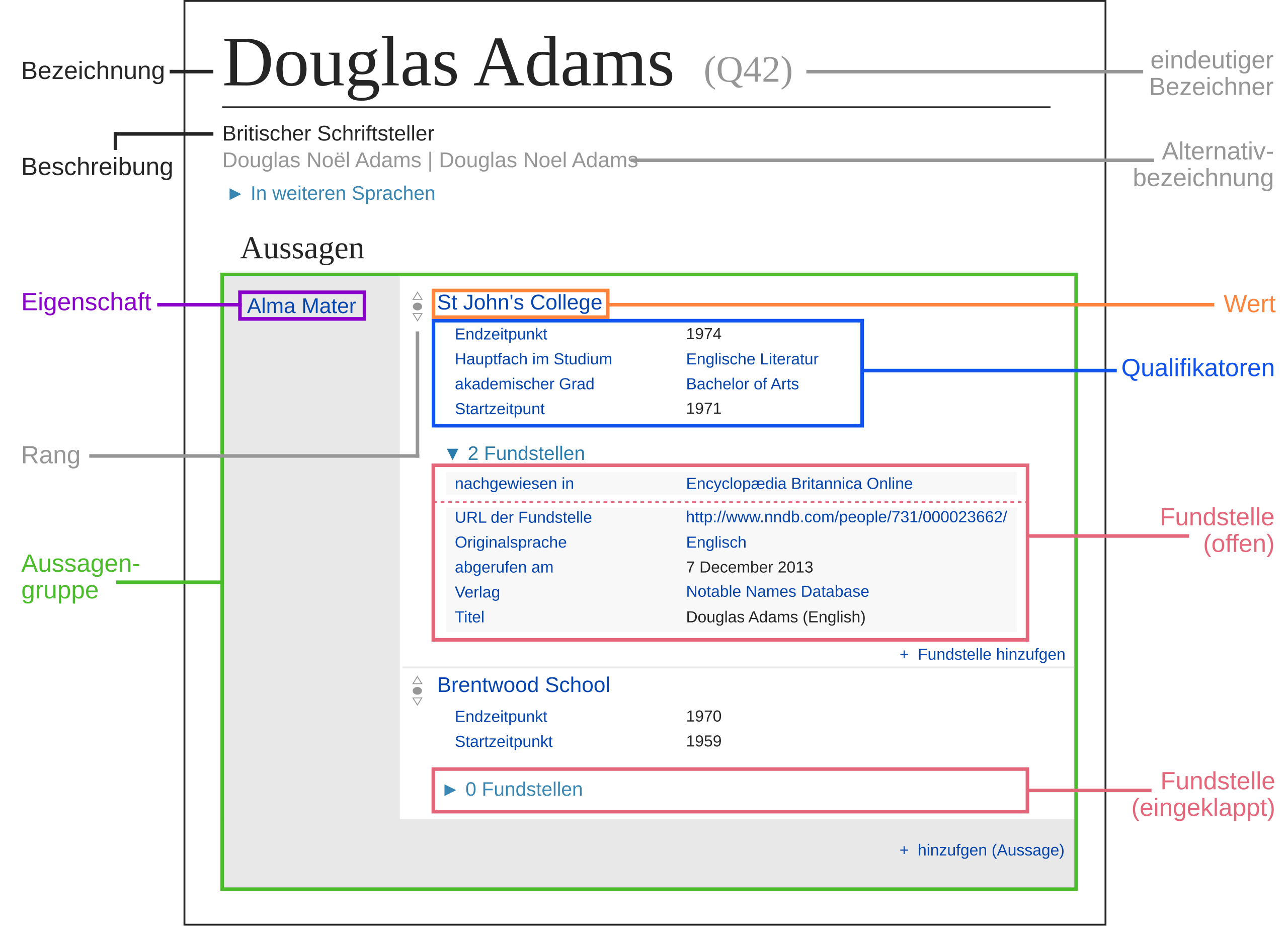
Fig. 1 Quelle: https://de.wikipedia.org/wiki/Wikidata#
Viele weitere Akteure arbeiten freundschaftlich mit der Wikimedia Foundation zusammen. Im Zusammenhang mit LOD ist das Projekt DBPedia ([]) des Instituts für Angewandte Informatik (InfAI) der Universität Leipzig.
DBpedia
https://de.wikipedia.org/wiki/DBpedia
DBpedia ist ein Gemeinschaftsprojekt, das Wikipedia-Artikel gemäß der Konzepte von Linked Open Data für das Semantic Web transformiert. […] Die DBpedia-Entwickler extrahieren regelmäßig strukturierte Informationen aus Wikipedia und machen sie als Webanwendung, als Datenbankdump, und als SPARQL-Endpunkt zugänglich. DBpedia ermöglicht somit, die Wikipedia-Datenbasis anhand verschiedener Mechanismen auf standardisierte und trotzdem flexible Weise mit anderen Informationssystemen zu verbinden.
Wikidata und DBPedia sind ein Traumpaar, da sie sich beide dem zugrundeliegenden abstrakten Datenmodell RDF verschrieben haben. DBPedia stellt sogar eine Ontologie zur Verfügung, siehe https://www.dbpedia.org/resources/ontology/, https://dbpedia.org/ontology/.
Für weitere Informationen zum Kontext siehe z.B. https://doi.org/10.1007/978-3-319-74497-1_14 Abián, D., Guerra, F., Martínez-Romanos, J., Trillo-Lado, R. (2018). Wikidata and DBpedia: Eine vergleichende Studie. https://www.researchgate.net/publication/322999234_Wikidata_and_DBpedia_A_Comparative_Study
GND#
Orchid:
Wordnet, Babelnet etc.#
REDAKTION
Vorwiegend hierarchisch organisierte Sammlung von Lexemen und ihren Bedeutungen. Ein wohlvernetztes Bedeutungswörterbuch. Begriff Synset. Synonyme zwischen Senses, Hierarchische Relationen ( Hyponym, Hypernym) zwischen Synsets
Das Princeton-WordNet ist eine seit 40 Jahren weitgehend manuell aufgebaute Datenbank von semantischen und lexikalischen Beziehungen zwischen Wörtern, ihren Bedeutungen und Kontexten und damit ein wichtiges Beispiel für ein offenes Vokabular. Das Datenmodell von WordNet ist auch ein Beispiel für eine kleine Ontologie, d.h. eine Art, die Beziehungen zwischen Wörtern und Begriffen zu sehen.
WordNet existiert in einer allgemeineren Form in vielen Sprachen. Es bildet die Grundlage für weitergehende Wortverzeichnisse, Tesauri oder andere Datenbanken, die zum Teil wiederum auf Wikipedia oder andere erstklassige Informationsquellen verweisen. Das Princeton WordNet ist nur in Englisch verfügbar, andere WordNets in anderen Sprachen.
Die zentrale Idee, das zentrale Konzept des Princeton WordNet ist die Idee des Synsets. Am Beispiel des englischen Wortes car soll diese zentrale Datenstruktur des englischsprachigen Princeton WordNet kurz vorgestellt werden. Auto ist ein “syntaktisch normalisiertes” Wort (d.h. die nicht flektierte Grundform des Lexems), das ein Bedeutungswörterbuch mit senses wie Auto, Eisenbahnwaggon, Gondel usw. erklären würde. Umgekehrt sind auch andere Wörter denkbar, die mit ähnlichen Bedeutungen assoziiert werden. Wir erhalten insgesamt eine n-zu-m-Beziehung: Wörter haben im Normalfall mehrere Senses; und oft gibt es zu einem Sense mehrere Wörter.
In Wordnet werden Synonymbeziehungen nicht zwischen Wörtern, sondern zwischen Senses hergestellt: Ein Synset ist eine Menge von Senses, die in einem Satz ausgetauscht werden können, ohne dass der Satz seine Bedeutung ändert. “Bedeutung” hat nicht ein Wort, sondern ein Synset; wenn wir ein Synset mit einer gedanklichen Einheit, einem Begriff, gleichsetzen, sehen wir, dass ein Begriff in der Regel mehreren Senses und damit auch mehreren Wörtern zugeordnet ist. Wenn wir die Terminologie genau betrachten, sehen wir, dass nicht die Lemmata selbst Elemente eines Synsets sind, sondern die senses, die jeweils unterschiedlichen Bedeutungen der beteiligten Lemmata.
Die beschriebene Struktur des Princeton Wordnet ist in der Weboberfläche gut sichtbar. Wir suchen im Princeton Wordnet nach dem Lemma “Auto”. Die Antwort zeigt wn-search-car.

Dieses Beispiel live (und zugleich Quelle der Abbildung): WordNet > Search > “car”:
Text:
{02961779} S: (n) car#1, auto#1, automobile#1, machine#6, motorcar#1 (a motor vehicle with four wheels; usually propelled by an internal combustion engine) “he needs a car to get to work”
{02963378} S: (n) car#2, railcar#1, railway car#1, railroad car#1 (a wheeled vehicle adapted to the rails of railroad) “three cars had jumped the rails”
{02963937} S: (n) car#3, gondola#3 (the compartment that is suspended from an airship and that carries personnel and the cargo and the power plant)
{02963788} S: (n) car#4, elevator car#1 (where passengers ride up and down) “the car was on the top floor”
Das Lemma “car” hat verschiedene Bedeutungen (Wordnet: senses), die durch eine laufende Nummer unterschieden werden (hier car#1, car#2 etc.).
Eine bisweilen in der technischen Dokumentation propagierte Idealvorstellung, dergemäße jeder Begriff idealerweise genau eine Vorzugsbenennung, jedes Ding genau eine Bezeichnung, jeder Bezeichner genau einen bezeichneten Gegenstand hat entspricht nicht der durch Wordnet dokumentierten Realität der Normalsprache.
Für anspruchsvolle Wissensmanagementprojekte liegt es nahe, WordNet und auch seine internationalen Formen mit Wikipedia und vielen anderen offenen Quellen zusammenzuführen. Genau dies ist der Ansatz des mehr lexikalisch-semantisch orientierten Wissensgraphen https://babelnet.org/ und des mehr enzyklopädisch orientierten Wissensgraphen https://yago-knowledge.org/ (TBT ZITAT https://www.researchgate.net/publication/308584782_YAGO_A_Multilingual_Knowledge_Base_from_Wikipedia_Wordnet_and_Geonames).
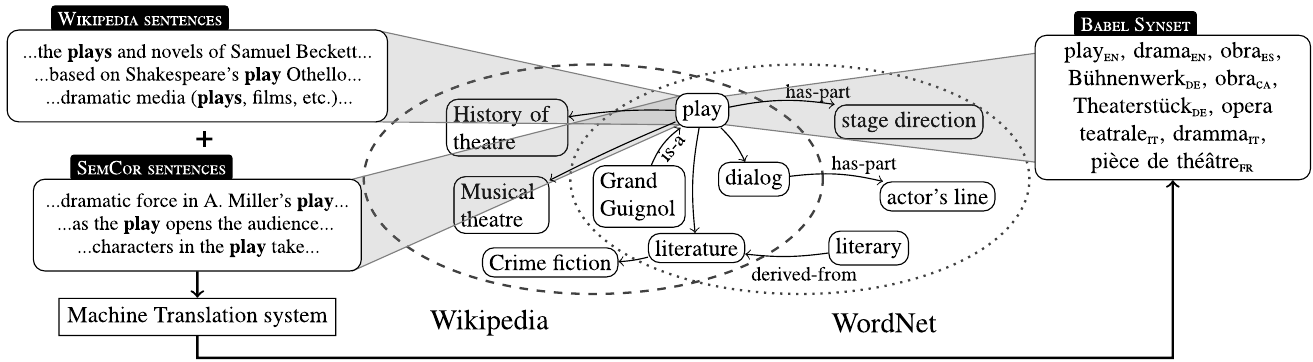
Fig. 2 Quelle: https://en.wikipedia.org/wiki/BabelNet#
Version 5.3 also associates around 61 million images with Babel synsets and provides a Lemon RDF encoding of the resource,[3] available via a SPARQL endpoint. 2.67 million synsets are assigned domain labels. (https://en.wikipedia.org/wiki/BabelNet)
LD, LOD, LLOD#
REDAKTION
Warum Linked Data? Verknüpfung! … Viele Daten bleiben “locked”; die Metadaten dazu sind vergleichsweise offene … ggf. auch “nur” im Unternehmen oder Konzern: auch das ist schon eine beschränkte Öffentlichkeit … oder maximal offen: weltweiter unbeschränkter Zugriff jedenfalls auf die Metadaten, oft auch auf die Daten selbst … Spezialfall dann LOGD, hier Einführung
W3C Linked Data Glossary:
Der Begriff Linked Data wurde 2006 von Tim Berners-Lee (im Folgenden TBL) geprägt. Der Wortlaut findet sich auf einer Seite persönlicher Notizen von Tim Berners-Lee, die unter dem Titel Design Issues: Architectural and philosophical points (https://www.w3.org/DesignIssues/) an sehr prominenter Stelle im W3C veröffentlicht ist. Das Glaubensbekenntnis von Linked Data lautet wie folgt:
W3C Linked Data Glossary
https://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data
☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.

Es hat sich gezeigt, dass diese einfache Idee erhebliche theoretische und praktische Probleme aufwirft. In den Kapiteln XXX und XXX werden diese Probleme aufgezeigt und bekannte Lösungsansätze diskutiert. In diesem Kapitel soll zunächst das Feld betrachtet werden. Was sind verknüpfte Daten (Linked Data, LD)? Verlinkte offene Daten (Linked Open Data, LOD)? Vernetzte offene Verwaltungsdaten (Linked Open Government Data, LOGD)? Vernetzte offene Vokabulare (LOV), und so weiter?
Linked Data
https://www.w3.org/DesignIssues/LinkedData.html, []
The Semantic Web isn’t just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.
Like the web of hypertext, the web of data is constructed with documents on the web. However, unlike the web of hypertext, where links are relationships anchors in hypertext documents written in HTML, for data they links between arbitrary things described by RDF,. The URIs identify any kind of object or concept. But for HTML or RDF, the same expectations apply to make the web grow:
Use URIs as names for things
Use HTTP URIs so that people can look up those names.
When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL)
Include links to other URIs. so that they can discover more things.
Weitere Literatur:
zum Einlesen ggf. Kapitel [SWWO: Linked data] in Allemang https://doi.org/ > 10.1145/3382097.3382103; auch [],
lod-cloud.net, lov.linkeddata.es, linguistic-lod.org
1a-Quellen für Suche und Dokumentation von LOD Ontologien und Vokabularen:
LOD:
Abbildung:
lod-cloud.net_versions_2024-10-25_lod-cloudAbbildung: lod-cloud.net_versions_2024-10-25_lod-cloud
LOV:
Abbildung: lov.linkeddata.es_dataset_lov
Klären:
Wie kommen diese Abbildungen technisch zustande, was bedeuten die Kanten?
Wie können wir diese Quellen nutzen?
Datenbank über LOD Schemata:
Sonderfall Linguistic Linked Open Data, LLOD:
[CParejaLora20] https://www.researchgate.net/publication/340549953_Open_Data-Linked_Data-Linked_Open_Data-Linguistic_Linked_Open_Data_LLOD_A_General_Introduction
cimiano2020: [CCMG20b] bzgl. Linguistik tiefgehend, für viele andere Themen eine kurze Einführung aus Vogelperspektive
swwo2020: []: bzgl RDF + semantischer Modellierung tiefgehend
cimiano2020, Chapter 9: Converting Language Resources into Linked Data. [CCMG20a]
Metadaten#
Das Problem beim Metadaten-Begriff ist der Begriff der Daten.
Daten#Informatik>
https://de.wikipedia.org/wiki/Daten#Informatik
In verschiedenen Fachgebieten [ … ] sind unterschiedliche – meist ähnliche – Definitionen gebräuchlich. Eine einheitliche Definition gibt es bisher nicht. […] Gemäß […] ISO/IEC 2382-1 […] sind Daten – Data: „a reinterpretable representation of information in a formalized manner, suitable for communication, interpretation, or processing“ […] In der Informatik und Datenverarbeitung versteht man Daten gemeinhin als (maschinen-)lesbare und -bearbeitbare, in der Regel digitale Repräsentation von Information.
Was sind Daten? Im weitesten Sinne jeder Strom von Nullen und Einsen, oder auf einer höheren Ebene alles, was von Menschen oder Computern gelesen werden kann; oder alles, was etwas beschreibt, bezeichnet, identifiziert, lokalisiert, repräsentiert und so weiter. Die Struktur von Daten ist so vielfältig wie die Welt, die durch Daten repräsentiert wird. Dieser Text erhebt nicht den Anspruch, diese Vielfalt auch nur annähernd zu erfassen. Zudem sind die meisten Daten nicht offen und können, wollen, dürfen es zurecht nicht sein.
Anders verhält es sich mit Metadaten. Um in einer digitalen Gesellschaft aus Daten Nutzen ziehen zu können benötigen wir Verzeichnisse, welche Daten mit welcher Bedeutung, Herkunft, Verwendungsmöglichkeiten, Nutzungstrechten etc. wo und wie verfügbar sind. Solche Verzeichnisse werden heute zurecht als LOD auf Basis der Technologien des Semantic Web angelegt. Um vernetzte offene Metadaten geht es auch in diesem Text am Beispiel von vernetzten offenen Verwaltungsdaten (LOGD).
Wenn Metadaten Daten über Daten sind, der Datenbegriff selbst aber konturlos bleibt: Was ist dann noch interessant an der Definition „Daten über Daten“? Wir werden weiter unten sehen, dass die harmlos klingende Charakterisierung „Daten über Daten“ in diesem Kontext auf eine grundlegende Kategorie verweist, nämlich auf das bibliothekswissenschaftliche Konzept der {term} Aboutness.
Aboutness>
https://en.wikipedia.org/wiki/Aboutness
Aboutness: In library and information science (LIS), it is often considered synonymous with a document’s subject. […] In the philosophy of logic and language, it is understood as the way a piece of text relates to a subject matter or topic. […] Fairthorne (1969) is credited with coining the exact term “aboutness” […] Birger Hjørland (1992, 1997) argued, however, that […] “aboutness” and “subject” should be considered synonymous.
Aboutness:
im Bibliothekskatalog das Stichwort, die Verschlagwortung; Synonym mit Thematik, “Subject”
auch in emails das Metadatenfeld “Subject”
IFLA FRSAD Final Report: Appendix A: Modeling Aboutness: https://www.ifla.org/wp-content/uploads/2019/05/assets/classification-and-indexing/functional-requirements-for-subject-authority-data/frsad-appendix-a.pdf
in govdata / DCAT-AP was? Das Metadaten-Portal govdata.de zeigt nicht direkt auf Daten, sondern auf (teilweise Metadaten von) Metadaten von Daten … z.T. ein vielfaches Meta … Vertiefung:
sect-linked-open-govdata, Ein konkreter Standard: z.B. DCATNicht zu verwechseln mit Ofness, Darstellungsinhalt
Weitere Metadaten-Standards: Eine gute Übersicht über Metadaten-Standards hat DSSC zusammengestellt:
https://dssc.eu/space/SE1/185794608/Data+Interoperability+standards+and+technologies+landscape:
https://dssc.eu/space/SE1/185794711/Data+Sovereignty+and+Trust+standards+and+technologies+landscape:
Data Value Creation standards and technologies landscape: https://dssc.eu/space/SE1/185794822/Data+Value+Creation+standards+and+technologies+landscape (häufige Erwähnung von DCAT)
TBD:
Ein konkreter Standard: z.B. DCAT#
Ein wichtiger Standard zur Strukturierung von Metadaten ist die W3C Recommendation Data Catalog Vocabulary (DCAT), die seit August 2024 in einer neuen Version 3 vorliegt.
Wir führen in die Struktur von DCAT ein und werden dabei feststellen, dass der für DCAT grundlegende Begriff des Datensatzes nicht nur problematisch, sondern tatsächlich undefiniert ist. Das ist schade, denn je nach Interpretation von “Datensatz” sind eigentlich unterschiedliche Metadatenstrukturen sinnvoll. Wenn man die enge Identifikation “Datei = Datensatz” aufgibt, braucht man eine Metadatenlogik, die sich vom Dateibegriff löst und sich stattdessen mehr an abstrakteren LOD-Technologien orientiert.
Was ist ein Datensatz?#
DCAT Dataset, Data_Service
https://www.w3.org/TR/vocab-dcat-3/#Class:Dataset
dcat:Dataset: A collection of data, published or curated by a single agent, and available for access or download in one or more representations.
https://www.w3.org/TR/vocab-dcat-3/#Class:Data_Service dcat:DataService: A collection of operations that provides access to one or more datasets or data processing functions.
Wir sind bei der Kernfrage angelangt: Was beschreiben wir eigentlich, wenn wir Daten beschreiben? Den Inhalt? Das Modell des Inhalts? Die Kodierung des Modells? Den Zugang zu einer Datei, zu einer Datenbank? Wir werden das im WEMI-Kapitel ausführlicher behandeln. Zunächst aber wollen wir uns den Begriff “Datensatz” genauer ansehen.
Datensatz bei Dublin Core#
Datensatz bei GovData#
Portale wie govdata.de und andere geben die Anzahl der Datensätze prominent an. Manchmal entsteht der Eindruck, dass die Anzahl der Datensätze als Bewertungsinstrument eines Portals verstanden werden kann. Dies ist nicht unproblematisch:
Man kann eine CSV-Datei (gleich Datensatz?) immer in mehrere CSV-Dateien aufteilen: Entstehen so mehrere Datensätze?
Handelt es sich bei Daten, die jedes Jahr in einer eigenen (hier CSV-) Datei mit identischem Schema veröffentlicht werden, nicht eigentlich um einen einzigen Datensatz, der aus technischen oder logistischen Gründen aufgeteilt wird?
Datensatz
https://de.wikipedia.org/wiki/Datensatz
Ein Datensatz ist eine Gruppe von inhaltlich zusammenhängenden (zu einem Objekt gehörenden) Datenfeldern, z. B. Artikelnummer und Artikelname. Datensätze entsprechen einer logischen Struktur, die bei der Softwareentwicklung (z. B. im konzeptionellen Schema der Datenmodellierung) festgelegt wurde.
Zusammenfassend bezeichnet der Datensatz in der Informatik […] eine eindimensionale, strukturierte Folge von Attributen eines Elements einer übergeordneten Menge (z. B. eine Karteikarte einer Kartei, eine Bestellung einer Datenbank für Bestellungen, eine Zeile einer Adressliste).
Dagegen bezeichnet der Datensatz in der Statistik die Gesamtheit von Daten in einem bestimmten Zusammenhang. Hier ist er also gleichbedeutend mit Datenbestand […]
Wie viele andere Begriffe ist “Record” ein Polysem, d.h. ein Wort mit mehreren Bedeutungen:
Datensatz_1: in der guten alten Datenverarbeitung ein https://de.wikipedia.org/wiki/Verbund_(Datentyp); in Pascal ein Record; in OO eine Instanz einer Klasse
Datensatz_2: ein Datensatz als Menge von vielen Datensatz_1; eine Datei; Ergebnis einer Abfrage auf einem SPARQL-Endpoint; eine
dcat:Distribution(https://www.w3.org/TR/vocab-dcat-3/#Class:Distribution)
Zusätzlich
Datensatz_3: eine DACAT-Spezialisierung von Datensatz_1, die einen Datensatz_2 in einem DCAT-Metadatenkatalog beschreibt;
dcat:CatalogRecord(https://www.w3.org/TR/vocab-dcat-3/#Class:Catalog_Record)
Wenn also govdata.de auf seiner Landingpage “99136 Datensätze” angibt, dann bedeutet dies genau genommen:
die govdata-Datenbank (selbst ein Datensatz_2) enthielt am 2024-05-05T1200 genau 99136 Datensatz_3 (Instanzen von dcat:CatalogRecord);
Jeder dieser Datensätze_3 beschreibt typischerweise einige externe Datensätze_2 (Instanzen von dcat:Distribution);
jeder dieser externen Datensätze_2 enthält typischerweise viele Datensätze_1 (Pascal Record).
Datensatz in DCAT#
5.1 DCAT scope
dcat:Catalog represents a catalog, which is a dataset in which each individual item is a metadata record describing some resource; (https://www.w3.org/TR/vocab-dcat-3/#dcat-scope)
dcat:Dataset represents a collection of data, […] (https://www.w3.org/TR/vocab-dcat-3/#dcat-scope)
dcat:Distribution represents an accessible form of a dataset such as a downloadable file.
DCAT-AP.de 4.3 Klasse: Datensatz:
Beschreibung: Eine logische Entität, welche die veröffentlichten Informationen repräsentiert.
[JB: keine eigene hilfreiche Beschreibung des Begriffs über Scope; statt dessen nur Verweis auf DCAT ]
URI der Klasse
dcat:Dataset(Link target https://www.w3.org/ns/dcat#Dataset existiert nicht; aber weiterführende Informationen” zeigt auf DCAT2: https://www.w3.org/TR/vocab-dcat-2/#Class:Dataset)
DCAT 3: RDF Class dcat:Dataset (https://www.w3.org/TR/vocab-dcat-3/#Class:Dataset):
Definition: A collection of data, published or curated by a single agent, and available for access or download in one or more representations.
Usage note: This class describes the actual dataset as published by the dataset provider. In cases where a distinction between the actual dataset and its entry in the catalog is necessary (because metadata such as modification date might differ), the dcat:CatalogRecord class can be used for the latter.
Usage note: This class describes the conceptual dataset. One or more representations might be available, with differing schematic layouts and formats or serializations. (https://www.w3.org/TR/vocab-dcat-3/#Class:Dataset)
Usage note: The notion of dataset in DCAT is broad and inclusive, with the intention of accommodating resource types arising from all communities. Data comes in many forms including numbers, text, pixels, imagery, sound and other multi-media, and potentially other types, any of which might be collected into a dataset.
DCAT3: RDF Class dcat:CatalogRecord (https://www.w3.org/TR/vocab-dcat-3/#Class:Catalog_Record):
Definition: A record in a catalog, describing the registration of a single dcat:Resource. Usage note This class is optional and not all catalogs will use it. It exists for catalogs where a distinction is made between metadata about a dataset or service and metadata about the entry in the catalog about the dataset or service. For example, the publication date property of the dataset reflects the date when the information was originally made available by the publishing agency, while the publication date of the catalog record is the date when the dataset was added to the catalog.
Datensatz in RDA#
Wie wird “Datensatz” in der RDA-Community verwendet, die ja im Kern das FRBR WEMI-Modell verwendet? Im Vergleich zu DCAT haben wir hier eine differenzierte Struktur von Dokumentbeschreibungen.
Im Zettelkatalog musste für jede Eintragung eine eigene Katalogkarte produziert werden (vgl. Kap. 1.4.1). Bei EDV-Katalogisierung entstehen die Eintragungen einfach dadurch, dass die dafür vorgesehenen Felder belegt werden. […] Auch für jede Verweisungsform musste im Zettelkatalog eine eigene Verweisungskarte geschrieben werden. Bei EDV-Katalogisierung wird stattdessen für jede Person oder Körperschaft ein Datensatz angelegt, in dem die Ansetzungsform und alle Verweisungsformen sozusagen ‘gesammelt’ werden – ein sogenannter Normdatensatz. […] Viele Informationen werden in Form einer Verknüpfung mit einem anderen GND-Datensatz angegeben, sodass ein Netz von Beziehungen entsteht (S.13ff)
Eine Volltextsuche in Heidrun Wiesenmüller: Basiswissen RDA ([]) nach “Datensatz” und Analyse der Ergebnisse zeigt, dass “Datensatz” im Wesentlichen wie “Record” verstanden wird.
Heidrun Wiesenmüller: Basiswissen RDA
([])
Um die Entitäten der Gruppe 1 FRBR optimal abzubilden, müsste man eigene Datensätze für Werke, Expressionen und Manifestationen erstellen und diese miteinander verknüpfen. Eine solche Umsetzung wäre jedoch sehr aufwendig und ist in technischer Hinsicht nicht zwingend. Denn man kann auch vorhandene ‘gemischte’ Datensätze auswerten und die FRBR-Ebenen daraus für die Nutzeranzeige erzeugen. (S. 22)
5.1.3 Erfassung in Titel- und Normdatensätzen. Es gibt in RDA keine Vorgabe, an welcher Stelle im Datenmodell man die Merkmale von Werken und Expressionen erfassen soll. Im deutschsprachigen Raum werden sie üblicherweise in denselben Datensatz eingetragen wie die Merkmale der Manifestation, also in den Titeldatensatz. Man spricht in diesem Fall von einer „zusammengesetzten Beschreibung“: Die Merkmale der Manifestation machen den Hauptteil der erfassten Informationen aus, werden aber ergänzt durch Merkmale (und auch Beziehungen), die sich auf der Ebene der Expression und des Werks befinden (vgl. Kap. 8.2.2). (S.79)
[…] Im deutschsprachigen Raum wurden Normdatensätze früher nur angelegt, wenn es sich um ein Werk der Musik handelte oder wenn das Werk in der Sacherschließung als Schlagwort benötigt wurde. Seit der Einführung von RDA wird diese Praxis ausgeweitet. Künftig sollen Normdatensätze für Werke auch mit Hilfe von automatischen Verfahren erstellt werden. Normdatensätze für Expressionen werden im Rahmen der Formalerschließung bis auf Weiteres grundsätzlich nicht erstellt. (S.79, Kasten)
Ist ein unterscheidendes Merkmal im Titeldatensatz anzugeben, so wird auch der Werktitel erfasst (auch wenn dieser mit dem Titel der Manifestation übereinstimmt). […] Wenn es für das Werk einen Normdatensatz gibt, werden die genannten Merkmale auch dort erfasst, […] Die Erfassung von Form, Datum und Ursprungsort des Werks in einem eigenen Feld ist fakultativ auch dann möglich, wenn diese Merkmale nicht zur Unterscheidung benötigt werden. Überdies können im Normdatensatz für ein Werk Angaben zur Geschichte des Werks abgelegt werden (RDA 6.7). Die Identnummer des Normdatensatzes ist zugleich der Identifikator für das Werk (RDA 6.8). (S.86)
8.2.1 Identifikator und normierter Sucheinstieg. Als erste Möglichkeit zur Abbildung von Primärbeziehungen kann man einen Identifikator für die in Beziehung stehende Entität erfassen (RDA 17.4.2.1). Naheliegend ist diese Technik insbesondere dann, wenn das FRBR-Modell in Reinform verwirklicht ist. In einem solchen Datenmodell sind die Entitäten der Gruppe 1 streng voneinander getrennt; für jede von ihnen gibt es einen eigenen Datensatz. (S.130f)
8.2.2 Zusammengesetzte Beschreibung. Die dritte Möglichkeit zur Abbildung der Primärbeziehungen ist die sogenannte zusammengesetzte Beschreibung (RDA 17.4.2.3). Dabei wird eine gemischte Beschreibung angelegt, die Informationen aus den drei Ebenen Werk, Expression und Manifestation miteinander kombiniert. Ein Beispiel dafür zeigt Abb. 24 (S. 132). Hier gibt es nur einen einzigen Datensatz für die drei Entitäten Werk, Expression und Manifestation. (132)
8.2.3 Datenmodell der Deutschen Nationalbibliothek. Sobald mindestens zwei Manifestationen desselben Werks vorliegen, soll ein Normdatensatz für das Werk (vgl. Kap. 5.1.3) erstellt werden (132)
8.3.3 In der Manifestation verkörperte Expression. Die Beziehung zur in der Manifestation verkörperten Expression muss nur dann als Kernelement erfasst werden, wenn es mehrere Expressionen des Werks gibt (RDA 17.10). Im deutschsprachigen Raum wird die Expression ausschließlich im Rahmen der zusammengesetzten Beschreibung abgebildet; Normdatensätze für Expressionen werden im Rahmen der Formalerschließung grundsätzlich nicht angelegt (vgl. Kap. 5.1.3).
JB: Solch ein zusammengesetzter Datensatz ist ein Beispiel für ein Phänomen, das unter semantische-dekomposition-konglomerat genauer beschrieben ist.
Datensätze in relationalen Datenbanken#
In der Datenbankwelt bedeutet “Datensatz” in der Regel “Record”. In den Standardkursen “Datenbanken” lernt man, dass oft mehrere Operationen in verschiedenen Tabellen notwendig sind, um einen komplexen “Datensatz” zu erzeugen. Diese werden zu genau einer Transaktion zusammengefasst.
Transaktionen müssen dem ACID-Prinzip gehorchen, d.h. atomar, konsistent, isoliert, persistent sein. “Datensatz” könnte hier stehen: Alle Informationen, die notwendig (minimaler Datensatz) oder möglich (maximaler Datensatz) sind, um mit Hilfe einer ACID-Transaktion von einem konsistenten Zustand in einen anderen konsistenten Zustand zu gelangen.
Datensatz in RDF#
Definition: RDF Dataset. An RDF dataset is a set:
{ G, (<u1>, G1), (<u2>, G2), . . . (<un>, Gn) }where G and each Gi are graphs, and each<ui>is an IRI. Each<ui>is distinct. (https://www.w3.org/TR/sparql11-query/#sparqlDataset)
Wie erhält man solch einen Graphen? Anlegen from scratch: einfach. Oder über eine SPARQL-Anfrage an einen großen Graphen … über CONSTRUCT erhält man wieder einen RDF-Graphen … der allerdings mehrere “Datensätze” enthalten kann …
Was macht in einem RDF-Graphen einen Datensatz (Record) als eine Einheit erkennbar? Was grenzt nun zwei “unterschiedliche” Datensätze voneinander ab? … Idee hier: Im obigen Beispiel haben wir so etwas wie “Hauptklassen” … in RDF wäre ein Datensatz dann ein minimaler RDF-Teilgraph zu einer Instanz einer Hauptklasse, der (a) für sich alleine stehen kann und (b) hinreichend vollständig und konsistent ist.
Einen Datensatz “anlegen” heißt dann:
lege eine neue Entity vom gewünschten Typ an
reichere die Entity mit allen minimal erforderlichen Attributen an
kontrolliere Vollständigkeit und Konsistenz
lege Metadaten zum Datensatz an (in SKOS ist das z.B. vorgesehen; auch in https://www.w3.org/TR/vocab-dcat-3/#Class:Catalog_Record)
DCAT #Class:Catalog_Record
https://www.w3.org/TR/vocab-dcat-3/#Class:Catalog_Record
If a [JB DCAT-] catalog is represented as an [JB RDF 1.1, s.u.] RDF Dataset with named graphs (as defined in SPARQL11-QUERY), then it is appropriate to place the description of each [JB DCAT-] dataset (consisting of all RDF triples that mention the dcat:Dataset, dcat:CatalogRecord, and any of its dcat:Distributions) into a separate named graph. The name of that graph SHOULD be the IRI of the catalog record.
Obacht: Unter “RDF Dataset with named graphs” ist über das Zitat von SPARQL11-QUERY technisch explizit nicht ein einziger RDF-Graph, sondern eine Menge von RDF-Graphen gemeint:
An RDF dataset is a collection of RDF graphs, and comprises:
Exactly one default graph, being an RDF graph. The default graph does not have a name and MAY be empty.
Zero or more named graphs. Each named graph is a pair consisting of an IRI or a blank node (the graph name), and an RDF graph. Graph names are unique within an RDF dataset. (https://www.w3.org/TR/rdf11-concepts/#section-dataset)
Ergebnis zu “Was ist ein Datensatz”: In DCAT wird das Konzept “Datensatz” auf das Konzept Named Graph in einem RDF Dataset reduziert.
Damit stellt sich ein neues Problem: Technisch gesehen ist ein Named Graph einfach eine Menge von RDF-Tripeln. Aber nach welcher Systematik entscheiden wir, welche Tripel wir zu einem Named Graph zusammenfassen? Hier gibt es zwei Modellierungsmuster:
Graph per domain
Graph per business entity
Respekt vor dem sehr schönen Blog-Beitrag von Pavel Klinov:
Blog: Pavel Klinov
Graph per domain: By domain here we mean some part of the graph which is structurally different from other parts of the graph.
a table or a collection of tables esp. if the graph has roots in a relational database(s). […]
a data source, i.e. the named graph identifies where a particular part of the data came from, such as an upstream database, a connector, a data stream, etc. The graph IRI is then convenient to record provenance information.
a dataset. It’s not uncommon for Stardog customers to maintain different datasets in a single database in different named graphs esp. if they need to be queried together.
Graph per business entity:
The other, substantially different pattern of using named graphs is when each graph keeps together data about a single object, like a product, a customer, or any other business entity. This pattern usually results in millions of small graphs. In contrast to the above use case, these graphs tend to be independent and structurally similar. Continuing the analogy with relational models, such graphs often correspond to a single table row or a small set of linked rows from several tables (i.e. if the relational schema is normalised to a high form).
Quelle: https://www.stardog.com/labs/blog/from-vs-from-named-in-sparql/#graph-per-domain, https://www.stardog.com/labs/blog/from-vs-from-named-in-sparql/#graph-per-business-entity
Bezug zu “CSV vs. Excel”:
Eine CSV-Datei ist identisch mit einer einzigen Tabelle;
eine Excel-Datei kann mehrere, komplett unterschiedlich strukturierte Tabellen enthalten.
Wenn wir eine Excel-Datei mit mehreren Tabellen vor uns haben:
Gemäß dem Graph per Domain-Pattern würde man diese in ein RDF Dataset überführen, in dem jede einzelne in der Excel-Datei enthaltene Excel-Tabelle als ein einzeler Named Graph angelegt wird.
Wenn wir eine CSV-Datei vor uns haben:
Überführung trivialerweise in einen einzigen RDF Graphen … oft der default graph, aber das ist problematisch
Überführung in ein RDF Dataset, bei dem jede Zeile als ein eigener RDF Graph angelegt wird?
Zusammenfassung: Tupel, Record, Datensatz, Datenbank#
atomar, Datenatom, Tupel
Eine Sinneinheit, ein Objekt
eine einzelne Entity in einem ER-Diagramm, typischerweise mit eigener ID
eine Reihe in einer Tabelle in einer Relationalen Datenbank
ein flacher https://en.wikipedia.org/wiki/Record_(computer_science)
eine einzene RDF-Entity mit zugehörigen Attribut-Wert-Paaren
molekular, Datenmolekül, Record
eine Sammlung von eng zusammengehörigen Sinneinheiten
mehrere zusammengehörige, mit Relationen aufeinander bezogene Datenatome
eine Sammlung meherer zusammengehörender Entities in einem ER-Diagramm, die zusammen eine konsistente Einheit bilden, incl. Fremdschlüssel-Integriät
ein nested record (insbesondere dann, wenn unsere Datenbank resp. unser ER-Diagramm nach einem https://de.wikipedia.org/wiki/Sternschema aufgebaut ist)
in RDF ein Named Graph
Record Set
eine Sammlung von Datenmolekülen
Datensatz
ein Datensatz im Sinne der Statistik
eine Sammlung von Record Sets
eine CSV-Datei (eine Tabelle), in der viele gleich strukturierte Moleküle vorliegen
Datenbank:
relationale Datenbank: Eine Sammlung von Tabellen, die über Fremdschlüssel miteinander in Beziehung stehen
andere: NoSQL, XML etc.
RDF Dataset: Eine Sammlung von RDF graphs; das Wunsch-Datenmodell von TBL, siehe LOD, 5star etc. ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������tenmodell von TBL, siehe LOD, 5star etc.
Diskussion JB#
DCAT ist ein Vokabular zur Beschreibung von Datenbeständen, die meist vergleichsweise “harmlose” Dinge aus der analogen Welt oder digitalen Verwaltung beschreiben.
Ich meine, dass man solche Datenbestände besser auf Grund des FRBR WEMI Denkmodells beschreiben sollte, da nur dieses Denkmodell die verschiedenen komplexen Zusammenhänge professionell beschreiben kann. (Dass es dazu ausgebildeter Digital-Daten-Bibliothekare bedarf ist zutreffend, aber kein Gegenargument.) Damit WEMI auf digitale Entitäten angewandt werden kann, benötigen wir ein Verständis von WEMI, das die analogen Attribute nicht mehr benötigt, und ggf. um Attribute aus der digitalen Welt erweitert wird, sozusagen wemi digital, alias WEMI-D.
WEMI-D1 beziehe sich auf Dateien (Items), zu denen wir in einem FRBR-kompatiblen Katalog Datensätze für W, E und M anlegen können. Dieses anhand von Dateien entwicklete Modell lässt sich problemlos erweitern auf URIs, die man mit einer Datenbank-Anfragesprache abfragen kann, und man z.B. konventionell Tabellendaten erhält. Damit ist schon viel gewonnen.
WEMI-D2*: Trickreich wird es, wenn wir mit WEMI-digital bestimmte “bösartige” Entitäten beschreiben und dafür Metadatensätze anlegen wollen. Beispiele für bösartige Entitäten sind
RDF Graph
RDF Dataset, RDF named graph
Fragen: Was ist an einem einem Item vom Typ RDF named graph das Item, die Manifestation, die Expression, das Werk?
Ein Beispiel für bestimmte Argumentationsfiguren:
In Carroll et al. [CARROLL-05], a named graph is defined as a pair comprising an IRI and an RDF graph. The notion of RDF interpretation is extended to named graphs by saying that the graph IRI in the pair must denote the pair itself. This non-ambiguously answers the question of what the graph IRI denotes. This can then be used to define proper dataset semantics, as shown in Section 3.3. Note that it is deliberate that the graph IRI is forced to denote the pair rather than the RDF graph. This is done in order to differentiate two occurrences of the same RDF graph that could have been published at different times, or authored by different people. A simple reference to the RDF graph would simply identify a mathematical set, which is the same wherever it occurs. (https://www.w3.org/TR/rdf11-datasets/#sec-named-graph-paper)
CARROLL-05: [CBHS05] https://www.researchgate.net/publication/234804495_Named_Graphs_Provenance_and_Trust
Wir diskutieren im folgenden WEMI genauer.