WEMI#
Important
Worum geht es in diesem Kapitel? Eigentlich um Metadaten über - ja was genau: Dokumente? Dateien? Datensätze? Datenbanken? Datenlieferanten, Datenherkunft? Genau das wird durch WEMI weiter differenziert. FRBR-WEMI kommt aus der Welt der Bibliotheken, Bücher, Zeitschriften (auch digital). Die Übertragung bzw. Konkretisierung von WEMI auf digitale Objekte ist nicht trivial.
Stand dieses Kapitels: Noch sehr skizzenhaft, nicht ausgearbeitet, insgesamt noch unzufriedenstellend. Dennoch sei es öffentliche gestellt, um mit ein paar interessierten Kollegen zu diskutieren.
Jeder gut ausgebildete Bibliothekar kennt die Unterscheidung zwischen Werk, Ausdruck, Manifestation und Exemplar, kurz: WEMI. Diese grundlegende Klassifikation entstand Ende der 1990er Jahre als Ergebnis einer Anforderungsanalyse für die Aufgabenstellung: Entwerfe für die Domäne „Bücher in einer Bibliothek“ ein Datenmodell, das es Benutzern ermöglicht, Bücher in einer Bibliothek zu finden. Kurzfassung:
Wer ist der Autor, was ist das Thema eines Buches? Das ist das Werk.
In welcher Sprache wird das Werk beschrieben, ausgedrückt? Das ist der Ausdruck.
In welchem Format, auf welchem Datenträger wird der Ausdruck transportiert; wie viele Seiten hat das Buch; bei welchem Verlag ist es erhältlich; welches Format hat eine Datei, mit welchem Programm können wir sie bearbeiten? Das ist die Manifestation.
Wo steht das Buch, wo können wir die Datei herunterladen? Das ist das Item.
Genau genommen ist WEMI eine Theorie mit dem beabsichtigten Anwendungsbereich der analogen Dokumente. WEMI lässt sich aber auch auf die digitale Welt übertragen. Überall dort, wo Metadaten zu einer Entität geschrieben werden, eignet sich WEMI als Theorie, d.h. der intendierte Anwendungsbereich von WEMI lässt sich elegant auf die digitale Welt erweitern, jedenfalls überall dort, wo etwas beschrieben werden soll. Wann immer wir über Beschreibungen sprechen, eignet sich WEMI als zugehörige Theorie Unabhängig davon, was wir beschreiben: Sobald wir etwas beschreiben, haben wir es mit WEMI zu tun.
FRBR WEMI#
Important
JB: Ziel: Hier konventionelles FRBR WEMI einführen; Gruppe 1, auch FRBR Gruppe 2 und Gruppe 3 … Ziel: Grundlage schaffen für Transfer … auch hier Bezug auf Te Deum
[IFLASGotFRfBRecordsInternationalFoLAaInstitutions98], [IFLAStudyGroup06]
ursprünglich ER, Barbara Tillet … Abb. ER-Diagramm … “Funktional”, d.h. was will man … zeitähnlich wie Dublin Core … Relationship: https://chatgpt.com/c/6721be58-5830-8010-b312-ec46c394c824 …
Vorgehen: Die WEMI-Theorie zunächst anhand von Beispielen, die im Zentrum des intendierten Anwendungsbereichs von FRBR liegen, erklären. Dann diese Beispiele verändern, indem wir Schritt für Schritt dieses Zentrum verlassen und andere Anwendungsbereiche aufsuchen … Vorgehen dabei anhand von praktischen Tätigkeiten … Wiederholung der Frühphase von FRBR, funktionale Requirements, jetzt eben digital … auch Metaphern analysieren, insbesondere RFC 3986: „dereference“ wird hier metaphorisch mit „access“ erklärt: wer eine Adresse aufruft, sollte (ggf. auch erst nach einigen Weiterleitungen) „Zugriff“ auf eine Datei erhalten, die Datei „öffnen“, die Darin enthaltenen Daten lesen, ggf. verändern können etc. … das entspricht dem Umgang mit einem Buch im Aspekt Item: Nur das konkrete Item kann man wirklich lesen.
Relationen zwischen W, E, M und I: Für Werk, Expression, Manifestation ist jeweils die Relation has_part definiert … eine Expression kann mehrere und verschiedene Werke und Teilwerke ausdrücken (Hauptteil, Anhang, Glossar, Index usw.), und auch selbst verschiedene Teile haben: Werk - Expression ist eine n:m Relation … oft sind Expressionen komplexer und bestehen aus (has_part) weiteren Expressionen, z.B. Text, Bitmap-Bildern, Vektorgrafiken etc. … jeder dieser Teile kann wiederum in verschiedene Manifestationen (png, jpg, svg, markdown, xml uvm.) vorliegen: auch Expression - Manifestation ist eine n:m Relation
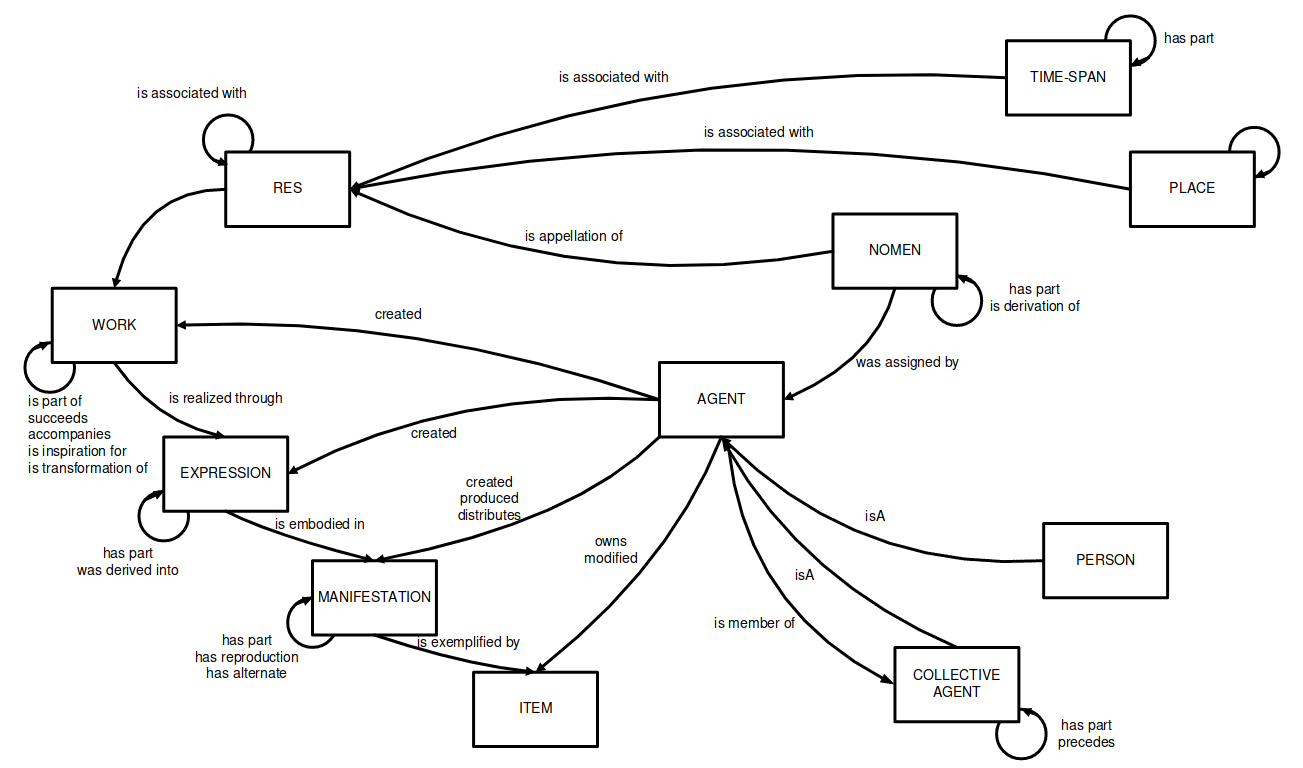
Fig. 4 FRBR-LRM-draft-2016-fig5.6-overview-of-relationships.png#
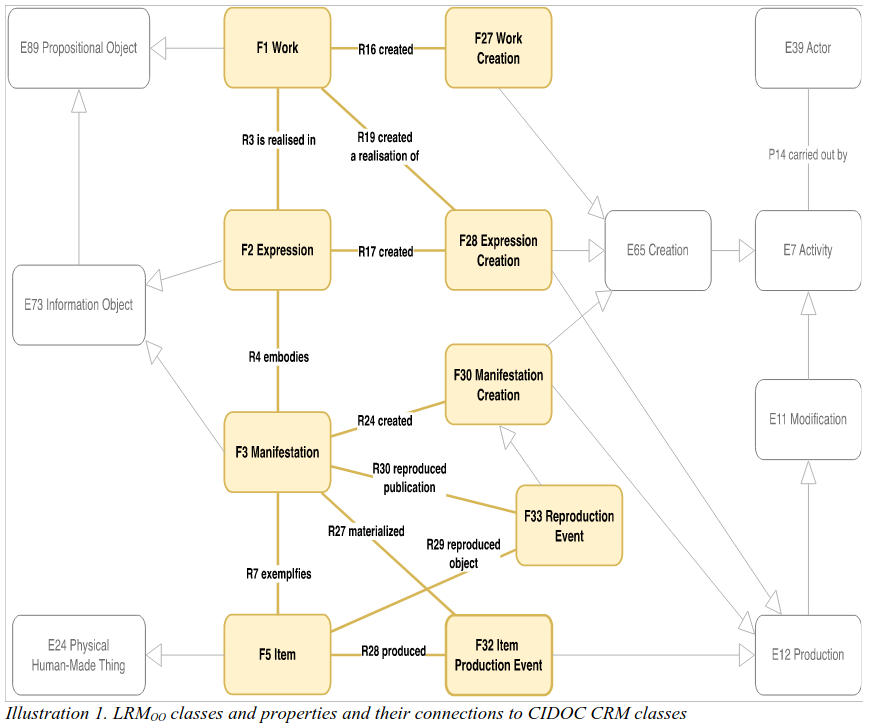
Fig. 5 LRMoo_V1.0_illustration1.png#
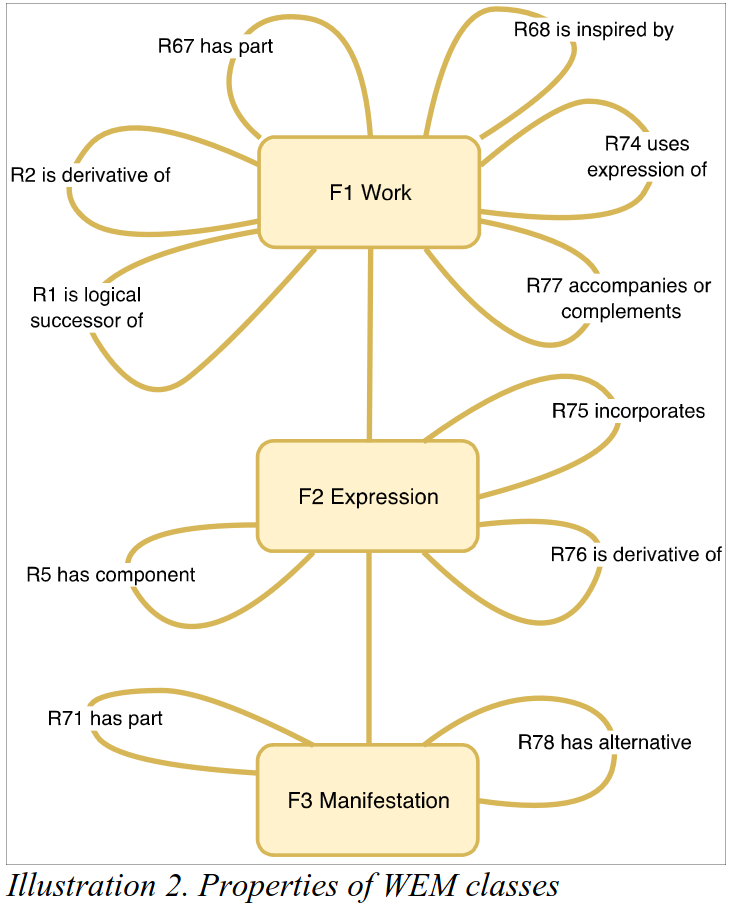
Fig. 6 LRMoo_V1.0_illustration2.png#
\cite{aalberg2024-LRMoo1.0}
Rezeptionsgeschichte, Versionen: kurze Einführung von IFL-LRM, LRMoo, andere?
Literaturübersicht: WEMI in FRBR, FRIR (SIEHE UNTEN), LRMoo, RDA (SIEHE UNTEN), CIDOC … Quellen in wemi-overview.md (nicht hochladen)
Ausführlich siehe Karen Coyle: Buch (!), neuer Aufsatz, aktuelle Entwicklung OpenWEMI
inbesondere auch RDA … baut auf FRBR auf, für Bibliothekare … FRBR und nachfolgend RDA ist das differenziertere Modell, u.E. geeigneter für professionelle Metadatenhaltung
Für uns interessant: Ähnlich wie mit DCAT kann man auch mit WEMI Daten beschreiben, also WEMI-Metadatensätze erzeugen …
Important
TBD: Ontologien rund um FRBR https://lov.linkeddata.es/dataset/lov/vocabs?tag=FRBR
FRIR#
Important
FRIR ist eine Übertragung von FRBR auf digitale Ressourcen … hat eine bestimmte Richtung: FRIR interpretiert http-Interaktionen, indem es FRBR als gegeben voraussetzt … message digests, content digest
Hint
Aufsatz: [MLG+12]
Quelle: James P. McCusker, Timothy Lebo, Alvaro Graves, Dominic Difranzo, Paulo Pinheiro, and Deborah L. McGuinness: Functional Requirements for Information Resource Provenance on the Web. https://www.researchgate.net/publication/262369023_Functional_Requirements_for_Information_Resource_Provenance_on_the_Web June 2012, DOI:10.1007/978-3-642-34222-6_5, Conference: Proceedings of the 4th international conference on Provenance and Annotation of Data and Processes
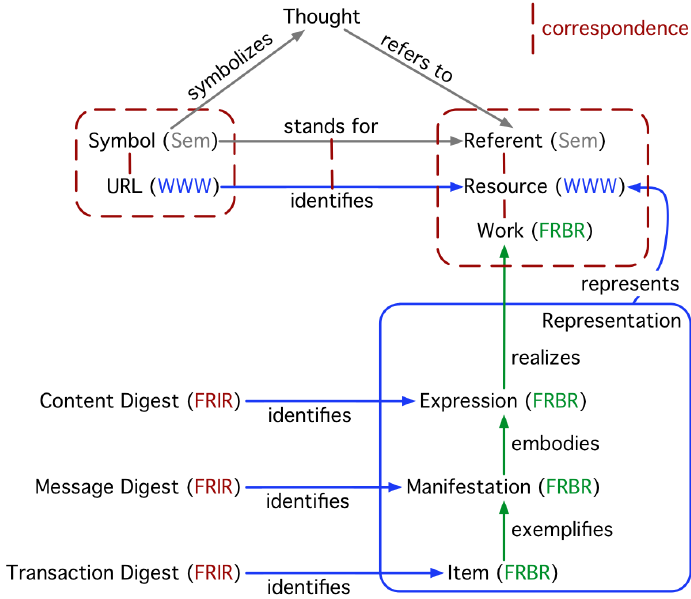
Functional Requirements for Information Resources [ Fußnote 5: <http://purl.org/twc/pub/mccusker2012parallel ] (FRIR) extends the use of frbr:Work, frbr:Expression, frbr:Manifestation, and frbr:Item to electronic resources, and therefore any information resource. Within electronic resources, a frbr:Work remains a distinct intellectual or artistic creation. A frbr:Work corresponds to the Resource or Referent in the semiotic framework discussed above, and is identified by a URL, as was shown in Figure 2. Taken together, frbr:Expression, frbr:Manifestation, and frbr:Item are all aspects of the Representation, and are each Referents in their own rights. Inasmuch as they can be identified or symbolized, they have symbols that identify them. frbr:Expression corresponds to a specific set of content regardless of its serialization. For instance, two files would have the same frbr:Expression if they are the same picture stored in two different formats (e.g., JPG and PNG). Similarly, a spreadsheet stored in both CSV and Excel would still have the same frbr:Expression. frbr:Manifestations correspond to a specific bit pattern. If a file is an exact copy of another file, they have the same frbr:Manifestation. An frbr:Item is a specific copy of information stored somewhere or transmitted through a communication link. If a copy of the frbr:Item is made, it results in a new frbr:Item. (p. 56f)
[…]
Conventional message digests such as MD5 or SHA-1 produce identifiers where the probability of creating the same identifier using different data is vanishingly small. This corresponds very closely to our definition of frbr:Manifestation for electronic resources, so we make it possible to identify frbr:Manifestations using message digests. (p. 57)
Similarly, a number of content digests have been developed for RDF graphs, spreadsheets, images, and XML documents that provide the same digest hash regardless of any particular serialization. We use this to computationally identify frbr:Expressions. (p. 57)
Ontologie: http://purl.org/twc/ontology/frir.owl | https://raw.githubusercontent.com/timrdf/csv2rdf4lod-automation/master/doc/ontology/frir.owl
Anwendung auf das Beispiel https://www.windfinder.com/forecast/st_leon_lake:
Werk: eine komplexe Sammlung von Informationen
z.B. eine spezifisch auf die Bedürfnisse von Wassersportlern zugeschnittene Wettervorhersage, hier z.B. für den See bei St. Leon-Rot
Expression: eine sprachlich-typografische Darstellungen eines Werks, z.B. eine Wettervorhersage als Dashboard in DE oder EN
Übersetzungen in DE und EN, Angaben in Knoten oder km/h erzeugen verschiedene Expressionen desselben Werks.
Manifestation: eine Datei, die man als Ergebnis einer http Content Negotion als Message Payload erhält.
Verschiedene Formate (pdf, html, Markdown, csv, xls etc.) erzeugen unterschiedliche Manifestationen derselben Expression.
Item
Die Datei, die ein Webserver für mich gebaut, auf seiner Festplatte zwischengespeichert und mir dann zugeschickt hat, sowie die Datei, die ich dann erhalten und in meinem Literaturverwaltungsprogramm abgelegt habe, sind zwei unterschiedliche Items derselben Manifestation.
Wir halten fest:
In Webarch repräsentiert eine Repräsentation eine Entity, gibt aber keinen Hinweis auf einen Unterschied zwischen Expression, Manifestation und Item.
FRIR interpretiert webarch:Repräsentationen aus Sicht von FRBR
The representation of that resource is the content that comes from dereferencing the URL, and is composed of an frbr:Expression, frbr:Manifestation, and frbr:Item. (p. 59)
Problem: Die Übertragung von FRBR auf FRIR ist plausibel, aber noch nicht ganz wasserdicht. Insbesondere haben wir mit obiger FRIR-Korrespondenz zwar ein praktikables Verständnis von frir:Manifestation, aber noch kein positives Verständnis von frir:Expression.
frbr:Expression corresponds to a specific set of content regardless of its serialization. For instance, two files would have the same frbr:Expression if they are the same picture stored in two different formats (e.g., JPG and PNG). [MLG+12], (p. 56)
Ein “set of content regardless of its serialization” – was könnte das sein? Wir suchen also nach einer positiven Beschreibung, Charakterisierung, Definition einer digitalen Expression (für die man dann, wie von FRIR vorgeschlagen, einen Content Digest erstellen kann). Die gesuchte Unterscheidung liefert die RDF Spec.
RDA#
Important
RDA ist die moderne Adaption von FRBR, normativ gültig für das Bibliothekwesen in Europa … RDA kann auch Datensätze beschreiben (!), über den Begriff integrierende Ressource.
Normativ:
LRM
[FRB16]
Klären:
Ontologie:
Lehrbuch:
Heidrun Wiesenmüller, Basiswissen RDA, ISBN 978-3-11-053868-7
Website zum Buch von Heidrun Wiesenmüller: https://www.basiswissen-rda.de/
Zusammenhang IFLA LRM und RDA: https://www.basiswissen-rda.de/2016/03/08/neues-konsolidiertes-frbr-modell-frbr-lrm-teil-3/ | https://www.basiswissen-rda.de/app/download/13199645422/FRBR-LRM_20160225.pdf?t=1512835231
RDA: Thema
Das Thema eines Werks kann mit drei unterschiedlichen Methoden angegeben werden - als Identifikator, als normierter Sucheinstieg oder als Beschreibung (unter letzteres fällt z.B. eine Inhaltsangabe in Satzform oder die Vergabe freier Schlagwörter). (https://www.basiswissen-rda.de/2015/06/21/rda-und-sacherschließung-zugleich-toolkit-release-april-2015-teil-3/)
Zum anderen ist die Erfassung von beschreibenden Beziehungen zwischen zwei Entitäten der Gruppe 1 (z.B. “Kommentar zu: …”), die bisher in Abschnitt 8 zu finden war (s.o.) nun ebenfalls in Kap. 23 gelandet, weil sie von der Logik her zur Sacherschließung gehört. Diese Art der inhaltlichen Erschließung, die vermutlich primär von Formalerschließern betrieben werden wird (die mit denselben Methoden auch andere, nicht sacherschließungsrelevante Beziehungen erfassen), sehe ich - zumindest bis auf weiteres - als etwas an, das neben der normalen verbalen oder klassifikatorischen Sacherschließung steht. (https://www.basiswissen-rda.de/2015/06/21/rda-und-sacherschließung-zugleich-toolkit-release-april-2015-teil-3/)
CIDOC#
(Hinweis zur Aussprache: CIDOC ist kein EN-Begriff, also nicht “saidok”, sondern einfach auf DE “sidok”.)
Warum CIDUC? LRMoo wurde in CIDOC eingegliedert
Einstieg: https://de.wikipedia.org/wiki/CIDOC_Conceptual_Reference_Model
Homepage: https://www.cidoc-crm.org/
Aktuelle Version: Definition of the CIDOC Conceptual Reference Model, Version 7.1.3, February 2024
[BBC+24]
Kerndokument: CIDOC CRM Special Interest Group, Version 7.1.3, February 2024: https://cidoc-crm.org/Version/version-7.1.3, Status: Official (ISO Correspondence)
Lizenz: CC BY 4.0
Zeigen: Ausschnitte aus der Klassenhierarchie: CIDOC CRM Class Hierarchy Table 3: CIDOC CRM Class Hierarchy, p.48ff … mit Fokus auf E73 Information Object … Mehrfachvererbung! …
konkrete Fragestellung, noch weiter recherchieren: Wie reagiert DC auf die Entwicklungen in FRBR und RDA, hier CIDOC?
WEMI für digitale Zwillinge#
Important
Prototypisches Beispiel Wetter … weltweit, Geokoordinatenzeit, unterschiedliches Wetter, unterschiedliche Datenmodelle, unterschiedliche Schemata, gleiches Schema, gleiches Wetter, große Manifestation, die nie vollständig vorliegt, verteilte Datenhaltung … Strukturgleich: Belegung von Parkhäusern in Deutschland, Fahrraddauerzählstellen, Verkehrsdichte, Energienetze, Abfallmengen, allgemein: Smart City … Letztlich ein großer Bereich, den auch GovData abdecken will. … Strukturgleich: Digitaler Zwilling einer MAschine, z.B. Kopierer, Industrie-Kaffemaschine, Automobil.
technisch: SPARQL Endpoint nicht als Datensatz, nicht als Manifestation, sondern strukturähnlich ähnlich einem Verlag mit Herausgeber.
WEMI hat sich für Bibliotheken durchgesetzt; ist auch mehr oder weniger gut übertragbar auf digitale Dokumente – jedenfalls Dokumente, die Sachen beschreiben, die sich statisch beschreiben lassen.
Frage hier:
Wie beschreiben wir mit WEMI “fluide” Dinge wie z.B. das Wetter?
Wie beschreiben wir in IFLA RDA Wetterbeschreibungen?
An jedem Ort der Welt, zu jedem Zeitpunkt haben wir ein anderes Wetter, ergo auch andere Wetterdaten, eine andere Beschreibung.
Wir versuchen das Problem aus verschiedenen Richtungen besser zu verstehen..
Ausgangspunkt 1: Unklarheit im Begriff der Manifestation#
Konventionelles WEMI hat es vorwiegend mit Dingen zu tun, die man in einer Bibliothek vorfindet, insbeondere Bücher und Zeitschriften, seit längerer Zeit auch in digialen Formaten wie inbes. pdf, ebook … das sind alles Endurants … hier ist eine statische Beschreibung angemessen … Manifestation Buch, Vervielfältigung, Produktion …
WEMI Digital: Fast alles, was für die Beschreibung (und die Unterscheidungen) von Manifestationen relevant ist, spielt in der digitalen Welt eine höchstens nachgeordnete Rolle … Verlag, Herausgeber,, ISBN etc. haben digital keine zentrale Bedeutung mehr … zwar noch bei Druckwerken, die auch als pdf-Dateien verfügbar sind … aber nicht mehr bei Datenbanken … unser Kontext ist Five Star Linked Open Data (LOD): A-Box und T-Box, Daten und zugehöriges Datenschema wohldefiniert … auch der Unterschied von Manifestationen und Items ist unklar.
Ausgangspunkt 2: Dinge vs. Geschehnisse#
In der philosophischen Ontologie wird grundlegender zwischen Endurant und Perdurant unterschieden:
Ein Endurant ist ein Ding, von dem man eine Momentaufnahme machen kann und das noch als solches erkennbar ist: ein Kind, ein Schnitzel, ein zerstörtes Dorf.
Ein Perdurant ist eine Entwicklung, ein Ereignis, ein Prozess, der erst im Laufe der Zeit als solcher erkennbar wird: Das Heranwachsen eines Kindes, die Zubereitung eines Schnitzels, der Verlauf einer “Spezialoperation”. …
RDF ist nicht “zeitbehaftet”, hat Zeit nicht eingebaut (RECHERCHIEREN) … verschiedene Lösungsansätze, unbefriedigend (RECHERCHIEREN) … grundsätzlicher Fehler: man denkt, man modelliert ein Endurant; oder man denkt, man kann ein Perdurant durch eine Serie von Snapshots “abbilden”. …
Ausgangspunkt 3: Das Allgemeine und das Besondere#
Das Allgemeine (auch: das Viele, das Generische, der Begriff) und das Einzelne (auch: das Besondere, die Instanz); Begriffe als Konzeptualisierung eines Allgemeinen, im Ggs. zur Beschreibung eines einzelnen Besonderen … Wenn wir das Verhältnis von Allgemeinem und Besonderem thematisieren, haben wir es mit einer Variante des https://de.wikipedia.org/wiki/Universalienproblem zu tun, also mit einem Grundproblem der Philosophie.
Die Philosophie des Mittelalters beschäftigt sich im Universalienstreit dann fast ausschließlich mit der Frage, welche existentielle Bedeutung dem Allgemeinen und dem Einzelnen zukommt. Porphyrios (232/233 bis 304) untersucht in der Isagoge, seinem Aristoteles-Kommentar, die drei Fragen, ob das Allgemeine substantiell (Realismus), losgelöst von den Dingen oder in den Dingen existiert oder ob es sich nur um eine Begriffsbildung im Intellekt handelt (Nominalismus). Eine häufige Lösung lautete, dass das Allgemeine in den Dingen liege, aber nur durch Begriffe existiere (Konzeptualismus). (https://de.wikipedia.org/wiki/Allgemeines_und_Einzelnes)
Mathematisch gesehen axiomatisieren wir in RDFS und OWL-Ontologien Mengen, indem wir eine sog. Intension formalisieren. Wir reden von “Instanzen”, die mathematisch gesehen aber nicht mehr als Elemente dieser Mengen sind … allgemeiner das gleiche in FOL … These: Wer in OWL eine eine Ontologie entwickelt hat den Blick primär auf Universalien gerichtet … in OWL haben wir den Begriff der T-Box, terminology box … es geht um Begriffe … oft wird eine Ontologie als Begriffs-System bezeichnet … Gruber spricht in einem der meistzitierten frühen Aufsätzen (1995?) von “Konzeptualisierung”.
Moderner Begriff: Digitaler Zwilling … etwa einer Industrie-Kaffeemaschine, eines Passagierflugzeugs etc. … da haben wir die detaillierte Beschreibung eines Einzelnen … Laufzeit, tatsächliche Reinigungsintervalle, Warn- und Störungsmeldungen, Austausch von Einzelteilen bei Wartung und Reperatur, Fehlerbilder … und natürlich Messdaten der Sensoren als Zeitreihe … diese Beschreibung nutzt die “Begriffe” einer Ontologie … es entsteht eine A-Box, “assertions” … T-Box und A-Box bilden eine Einheit (und in LOD ganz explizit: Daten ohne Bezug auf eine T-Box sind hier wertlos) … ein Digitaler Zwilling ist das Modell eines Einzelnen, also A-Box und T-Box
Ausgangspunkt 4: parametrisiertes Publishing on demand#
Bibliotheken fühlen sich konventionell an Dinge zwischen zwei Pappdeckeln zuständig, ggf. auch noch für e-Books und pdf-Dokumente … neue Erscheinungsformen “integrierende Ressourcen”, z.B. Webseiten, Datenbanken … auch hier ein Produktionsprozess … aber das Ergebnis einer Datenbankanfrage ist fast jedesmal ein anderes; dass man bei einer Anfrage auf eine integrierende Datenbank zweimal das selbe Ergebnis erhält ist der Ausnahmefall … Erweiterung des Begriffs des Items: Im Buchdruck wird eine Charge von weitgehend identischen Dingen erzeugt, die weitestgehend austauschbar sind; bei einer Datenbankanfrage wird praktisch jedes mal ein anderer Zeichstrom erzeugt: Unterschiedliche Manifestationen
The resource is the conceptual mapping to an entity or set of entities, not necessarily the entity which corresponds to that mapping at any particular instance in time. Thus, a resource can remain constant even when its content—the entities to which it currently corresponds—changes over time, provided that the conceptual mapping is not changed in the process. (http://rfc.net/rfc2396.html (1998), zitiert nach []
QUELLE auch:
Cataloging Online Integrating Resources, https://web.library.yale.edu/book/export/html/570
Hier könnte es helfen, eine Manifestation in Sinne von RDA als Zugriff auf einen Produktionsprozess zu verstehe: Manifestation beschreibt dann den Prozess, der on demand ein Item herstellen kann … die Metadaten der Manifestation wären dann Anfragsprache, verfügbare Parameter etc. … ein Item kann man als Ergebnis eines Prozessdurchlaufs mit ganz bestimmten Parameter-Bindungen verstehen; diese Parameter sollte man natürlich im Metadatensatz festhalten – und zwar auf Ebene eines Items …
Diskutieren: führen 2 unterschiedliche Parameter-Konfigurationen zu unterschiedlichen Manifestationen? Konventionell: JA. Besser aber: Nein. Denn z.B. Wetter-Websites liefern sogar zu identischen Anfragen (z.B. “Wetter in Berlin”) zu jedem Zeitpunkt unterschiedliches Items, gleiche Parameter garantieren also nicht gleiche Items; und tatsächlich sind nie 2 Anfragen gleich, so dass wir eine 1:1 Beziehung zwischen Manifestation und Item hätten, jede Datenbank-Abfrage also eine neue Manifestation generiert – das kann in einem Datenbibliotheks-Katalog nicht gewünscht sein.
Ähnliches gilt für digitale Zwillinge einer Maschine.
Ausgangspunkt 5: Überabzählbarkeit in vielen Dimensionen#
Wir nehmen an, dass wir für eine jede einzelne Kaffemaschine, jedes einzelne Verkehrsflugzeug, jede einzelne Person einen digitalen Zwilling pflegen … dann können die Daten in Dateien abgelegt werden, die im Gerät selbst vorgehalten werden (“Flugschreiber”) … und/oder die Daten werden in einer Datenbank vorgehalten, die beim Hersteller oder Betreiber liegen … jedes Gerät, jde Person hat eine eindeutige ID … mathematisch gesehen ist die Menge der hier dokumentierten Partikularien eine abzählbare Menge.
Wie stehen die Dinge bei nicht abzählbaren Dingen wie z.B. Wetter-Daten? … das Wetter in COACOXA; auf meinem Weg zur Arbeit; in Süddeutschland … die digitalen Zwillinge des Begriffs “Wetter” sind nicht nur in Bezug auf den Index Zeit, sondern auch in Bezug auf Geo-Koordinaten überabzählbar – jedenfalls dann, wenn man Wetter als Endurant verstehen würde und meinen würde, dass man hier Schnappschnüsse machen könnte … man könnte Wetter auch als ein Perdurant verstehen, ähnlich wie die Entwicklung eines Kindes, eines Krieges oder der Verstopfung einer Kaffemaschine … ein Perdurant, der nicht nur durch eindimensionle Zeit-Intervalle, sondern auch durch geographische Gebietsangaben (in der Praxis durch Polygonzüge), Höhenangaben (Agrarwetter, Flugwetter) etc. beschrieben werden.
Unsere Fragen:
Wie modelliert man heute technisch Perdurants, wie sieht die Datenhaltung aus?
Wie beschreibt man mit WEMI “fluide Dokumente” (Straßenverkehrsdaten, Wetter, digitaler Zwilling einer Industrie-Kaffemaschine?)
Was ist ein “fluides Dokument” im Ggs. zu einem statischen Dokument?
existiernde Lösungen:
RDA, siehe integrierende-ressourcen
Lösungsidee#
Kernidee: Wir wollen eine Expression als ein Modell verstehen … zunächst denkt man hauptsächlich an Schema … Gedanke: eine Kaffeemaschiene allgemein … E: verschiedene technische Modelle (CAD, Leitungen, Venile), auch ein Begiffsmodell (T-Box); auch ein Betriebsmodell etc. … bei Modellen eines Einzelnen kommen die Parameter und Messdaten der bestimmten konkreten Maschine hinzu … modeliert wird eine Instanz, mithin auch ein verfeinerter Gedanke an eine konkrete Maschine
digitaler Zwilling … allgemein eine technische Simulation einer einzenen Maschine, ggf. auch Überwachung, Regelungs- oder Steuerungs-Schleifen von und zur Hardware … ein Computer mit vielen laufenden Systemen … das ist für unsere Betrachtung zu komplex … Wir betrachten den Spezialfall, der für unseren Kontext Linked Open Data (LOD) zental und einschlägig ist: eine A-Box aller relevanten Zustands-Daten eines Gegenstands im Zeitverlauf (also eine Zeitreihe) incl. die T-Box dieser A-Box … alles zum Ausdruck gebracht im abstrakten Datenmodel RDF … technisch verarbeitbar in verschiedenen Formaten wir z.B. Turtle, RDF/XML … digitaler Zwilling hier also technisch gesehen als eine RDF-Datenbank mit SPARQL-Endpoint … in hohem Maß “fluide”
“to render”#
Was ist im Rahmen dieser Theorie der Unterschied zwischen einer “schön gesetzten” mathematischen Formel und ihrem Quellcode in LaTeX? … Kernbegriff “to render”; Auskunft ChatGPT: Ursprung lateinisch “reddere”, aus “re-” (zurück) und “dare” (geben); Bedeutungen und Interpretationen auf Deutsch u.A.:
Darstellen / Wiedergabe: In modernen Kontexten, vor allem in der Kunst, Computerwissenschaft und Architektur, wird “render” oft verwendet, um die Darstellung oder Visualisierung von Informationen oder Bildern zu beschreiben (z. B. “to render a scene” = “eine Szene darstellen”).
Umsetzen / Verwandeln: In technischen oder kreativen Bereichen kann “rendern” auch bedeuten, ein Produkt oder ein Ergebnis durch einen Prozess zu erzeugen oder zu transformieren, wie z. B. in der Computergrafik. (ChatGPT)
Rendern ist also eine Transformation einer R-Maschine von R_Bytes in andere R_Bytes mit dem Ziel, ein R-Objekt zu schaffen, das der Mensch anschauen (anhören, …) kann … R-Maschine steuert LEDs eines “Bildschirms”, schaltet sie an- und aus … all das sind Veränderungen in der Realität … Tastatur zur Zeichen-“Eingabe” … auch gestenbasierte Eingabe … “Schnittstelle” Mensch-Maschine
Technisch liegen Bits und Bytes vor; die werden gerendert … unterschiedliche Renderer erzeugen unterschiedliche Pixel-Bilder, visuelle Eindrücke.
Ein Beispiel:
Formel
Quellcode
s = \int_0^t w(t') \, dt'
Zunächst zur Gemeinsamkeit. Die Kästen “Formel” und “Quellcode” sind Expressionen eines Zusammenhangs zwischen der Eulerzahl e und der Kreiszahl π: Gleiche Expression!
Im Kasten “Formel” erkennt ein Mathematiker zweidimensional arrangierte graphische Repräsentation (Glyphen) von Symbolen wie z.B. das Integral-Symbol
Im Kasten “Quellcode” erkennen wir eine eindimensionale “ZeichenKette” von Glyphen. Nicht wenige Mathematiker nutzen diese oder ähnliche Repräsentation von Symbolen, wenn sie sich per E-Mail zu einem mathematischen Problem austauschen.
Unterschiedlich sind allerdings die verschiedenen Manifestationen: die Zeichenketten \(s = \int_0^t w(t') \, dt'\) und s = \int_0^t w(t') \, dt' nutzen unterschiedliche Zeichen und Zeichenfolgen zur Codierung der selben Ausdrucksform. In beiden Fällen generiert uns die Satz-Software dieses Büchleins ein Mosaik aus Punkten. In der Markdown-Datei spiegelt sich das wieder in den unterschiedlichen Kästen, auf Manifestations-Ebene also unterschiedliche Fragmente. Die Markdown-Quelle dieses Abschnittes sieht so aus:
Markdown-Datei
````{admonition} Formel
$$s = \int_0^t w(t') \, dt'$$
````
````{admonition} Quellcode
s = \int_0^t w(t') \, dt'
````
Im Kasten {admonition} Formel wird der Quellcode durch je zwei Dollarzeichen begonnen und beendet, wohingegen sie im Kasten {admonition} Quellcode durch vier Leerzeichen eingerückt wird. Die Satz-Software https://jupyterbook.org/en/stable/intro.html übergibt durch $$ ... $$ “eingezäunte” (en: fencing) Zeichenketten an die JavaScript “display engine” MathJax, die LaTeX, MathML und AsciiMath Notation im Browser “rendert”. Die selbe Zeichenkatte um vier Leerzeichen eingerückt wird hingegen von Jupyterbook selbst verarbeitet und im Font Courier uninterpretiert dargestellt.
WEMI als Upper Level Ontologie#
Die Welt lässt sich grob in zwei große Bereiche einteilen:
Die Realität besteht aus allen physikalischen Dinge, die auch ohne uns bestehen. Die Realität ist Gegenstand der Naturwissenschaften.
Die Wirklichkeit besteht aus unseren geistigen Vorstellungen, Konstruktionen, Ideen, wie sie in unserer Auseinandersetzung der Realität entstehen. Die Wirklichkeit ist Gegenstand der Sozial-, Geistes- und Humanwissenschaften, der Künste, der Theologie und natürlich der Philosophie.
Manche Teile der Realität kann unser Geist wahrnehmen, andere nicht. Unser Geist kann sich auch Dinge vorstellen, die es in der Realität so nicht gibt. So gibt es in der Realität z.B. keine Einhörner. Interessanterweise gibt es in der Realität auch keinen Eiffelturm. Was es in der Realität gibt, ist ein Haufen Metall im Zentrum von Paris. Aber “Eiffelturm” ist eine Idee, eine Erfindung des Geistes, ein Teil der Realität und nicht der Wirklichkeit. In der Realität gibt es auch keine Bücher, nur Stapel von Papier und Pappe, auf die stellenweise Druckerschwärze aufgebracht wurde. Es ist unser Geist, der solche Objekte der Realität als “Buch” wahrnimmt.
Im Folgenden interessiert uns vor allem der Bereich der Wirklichkeit, also der Bereich der geistigen Vorstellung. Wir wollen “Wirklichkeit” nun ergänzend weiter differenzieren.
Die Domäne der Ideen bildet die Grundlage für alles. Sie umfasst die geistigen Vorstellungen, alles, was im Geist entsteht: Gedanken, Konzepte, Theorien, Fantasien, Gefühle und Intuitionen. Eigenschaften: Sie sind immateriell und existieren nur im Geist eines Subjekts. Sie sind flüchtig und privat, solange sie nicht ausgedrückt werden. Sie können sich ändern, entwickeln oder vergessen werden. Ideen gehören eindeutig zur Wirklichkeit, da sie Produkte unseres Geistes sind und keine physische Existenz haben. Sie stehen oft in einem Spannungsverhältnis zur Realität, da sie sowohl Dinge widerspiegeln können, die in der Realität existieren (ein Baum; viele Bäume; Idee eines Baumes), als auch reine Konstrukte sein können (z.B. das Einhorn), die Idee der Gerechtigkeit.
Geistige Vorstellungen, Ideen sind unsichtbar. Aber der Mensch kann kommunizieren, geistige Vorstellungen zum Ausdruck bringen: Durch Blicke, durch Gesten, durch Handlungen, durch Artefakte. Insbesondere kann der Mensch seine geistigen Vorstellungen, seine Gedanken in Worte fassen - mündlich und schriftlich.
Im Folgenden geht es um schriftliche Ausdrucksformen. Ein schriftbasiertes Artefakt wird immer durch drei Aspekte beschrieben:
symbolische Ausdrucksform
verkörperte Kodierung
individuelles Exemplar
Die Unterscheidung zwischen symbolischem Ausdruck und verkörperter Kodierung beruht auf dem Unterschied zwischen (a) der Ebene der abstrakten Symbole (Zeichen im weiteren Sinne), mit denen wir unsere geistigen Vorstellungen ausdrücken, und (b) der Ebene der Zeichen im engeren Sinne (Buchstaben, Ziffern usw.), mit denen wir unsere Zeichensymbole auf einem bestimmten physischen Träger (Papier, Computerspeicher) verkörpern. Die Metapher des Mosaiks ist hier hilfreich.
Beispiel 1:

Fig. 7 Quelle: https://commons.wikimedia.org/wiki/File:MosaicEpiphany-of-Dionysus.jpg, Lizenz: Public Domain; Backlink: https://de.wikipedia.org/wiki/Dionysosmosaik_(Dion)#
{kind=link}
Auf dem Bild sehen wir einen von Panthern gezogenen Wagen, Kentauren, die Gefäße tragen, eine heroische menschliche Figur: das sind die Symbole. Das Bild ist aus einzelnen Steinen zusammengesetzt. Das sind die Buchstabenzeichen. In diesem Fall repräsentiert das Arrangement der Buchstabenzeichen, also die wechselseitige Position zueinander die Symbole. (Wir können uns aber auch ganz andere Art und Weisen denken, die Symbole zu repräsentieren.)
Die Metapher des Mosaiks kann auch auf der Ebene der symbolischen Ausdrucksformen angewendet werden: Auf dem Bild sehen wir Panther, Streitwagen, Kentauren, ein Weingefäß. Aber nicht diese Symbole selbst, nicht die bloße Ansammlung dieser Symbole, sondern erst die Wechselwirkung dieser Symbole untereinander lässt so etwas wie “Bedeutung” entstehen. Wir wollen hier von einem Mosaik von Symbolen sprechen, von einem Symbolmosaik. Bedeutung erhält das Symbolmosaik erst in der Interpretation durch einen Menschen - und auch nur durch einen Menschen, der bereits in eine spezifische Symbolwelt eingeführt, “enkulturiert” ist.
Im Folgenden geht es nicht um bildliche Darstellungen, sondern um schriftliche Ausdrucksformen. Auch hier trägt die Metapher des Symbolmosaiks. Mathematische Formeln, musikalische Partituren sind Mosaike von Symbolen, die ein Kundiger als Ausdruck einer geistigen Vorstellung lesen kann.

Fig. 8 Die Ciaccona aus Johann Sebastian Bachs Partita für Violine No. 2. Abbildung gemeinfrei, Backlink: https://de.wikipedia.org/wiki/Chaconne#
Der Aspekt der symbolischen Ausdrucksformen von Ideen umfasst alles, was in Schrift, Text, Formel, Zeichnung, Diagramm, Schaubild, formaler Notation usw. abstrakt-symbolisch mitgeteilt werden kann. Symbolische Ausdrucksformen sind kulturell geprägt und basieren auf einem gemeinsamen Verstehenssystem (z.B. Sprache, Mathematik, Kunst). Sie sind persistent (insofern sie aufgezeichnet sind) und ermöglichen Kommunikation über Zeit und Raum hinweg. Sie können interpretiert, missverstanden oder neu gedeutet werden. Wie in einem Mosaik aus Figuren erhält auch in der schriftbasierten Kommunikation erst die Anordnung der abstrakten Symbole zueinander, das Symbolmosaik, Bedeutung. Ihre Bedeutung und Interpretation ist Teil der Wirklichkeit, da sie erst durch menschliche Konstruktion und Verständnis existieren.
Der Aspekt der verkörperten Codierung einer schriftbasierten Ausdrucksform umfasst die Folgen (Ströme, Arrays, Ketten) von Schriftzeichen (Buchstaben, Ziffern, Satzzeichen etc.), festgehalten in einem Medium. In der digitalen Welt der Bits und Bytes sind zwei digitale Zeichenfolgen (en: octet stream) gleich, wenn ihre sha265 Checksummen identisch sind. Zeichenketten manifestieren symbolische Ausdrucksformen, lassen sie in einer medialen Repräsentation “gerinnen”. In einem Buch sind es die Buchstaben auf dem Papier, die einzelnen Seiten, die Gliederung in Absätze. In der digitalen Welt werden symbolische Ausdrucksformen in sogenannten Dateiformaten kodiert: txt, doc, html, xml, png, jpg, mp3 etc. Beispiele: Ein digitales Bild eines Einhorns, eine PDF-Datei über Brückenbau, eine Datenbank mit Symbolen und ihren Bedeutungen.
Der Unterschied zwischen symbolischem Ausdruck und verkörperter Kodierung wird in zwei verschiedenen Situationen deutlich. Situation 1: Wir nehmen ein Buch zur Hand und versuchen, seinen Inhalt zu verstehen. Wir suchen darin nach neuen Ideen, studieren die Diagramme, kritisieren die Schlüssigkeit der Argumentation: Dann nehmen wir das Buch als Text wahr, interpretieren es als eine Sammlung symbolischer Ausdrücke. Natürlich ist der Text eine Aneinanderreihung von Buchstaben, aber es würde unserem Verständnis des Textes nicht dienen, wenn wir die Größe der Buchstaben, ihre Form, ihre Farbe usw. in Betracht ziehen würden. Oder eine html-Datei: Der Text wird durch Tags in Überschriften und Absätze unterteilt. Die Tags kodieren, strukturieren den Text, nicht die Ideen, über die der Text Auskunft gibt. – Situation 2: Wir erhalten ein Buch zur Rezension, schlagen es auf: Das Layout gefällt, das Inhaltsverzeichnis ist übersichtlich, Textboxen geben Beispiele, die Schrift ist nicht zu groß und nicht zu klein, die Fadenheftung gibt Stabilität. Das Buch gefällt uns, wir sind positiv gestimmt, freuen uns auf den Inhalt. Bei diesen Überlegungen nehmen wir das Buch nicht als Ausdrucksform von Ideen wahr, sondern als Verkörperung solcher Ausdrucksformen in einem bestimmten Medium (analog: Tontafel, Papier, Schallplatte etc.; digital: XML, pdf, CSV, JSON etc. ). Auch wenn wir mit dem Inhalt des Buches, seinen Ideen, seiner Argumentation nicht einverstanden sind, können wir das Buch als verkörperte Codierung schätzen.
Die Domäne der einzelnen Exemplare. Situation 3: Wir wollen die Lektüre unseres Buches fortsetzen – aber wo haben wir es hingelegt? Aha, da liegt es; aber was ist das: Unser Partner benutzt das Buch als Unterlage für sein Rotweinglas – nicht gut, denn so haben wir keinen Zugriff mehr auf das Buch. Und noch ärgerlicher: Der Einband hat einen Rotweinfleck abbekommen!
Erst die aktive Wahrnehmungsleistung des Geistes macht aus einem Stapel Papier, Pappe und roten Farbpartikeln ein Buch mit Rotweinfleck. Immerhin entspricht ein einzelnes Buchexemplar einem mehr oder weniger genau identifizierbaren und individuell adressierbaren Objekt in der Realität. Auch in der Möglichkeit des Zugriffs unterscheidet sich der Bereich der einzelnen Exemplare von dem der verkörperten Codierungen.
Der Unterschied zwischen verkörperter Codierung und einzelnen Exemplaren lässt sich auch so beschreiben: Einzelne Exemplare entstehen konventionell im Buchdruck durch einen Produktionsprozess, der viele identische Einzelobjekte hervorbringt. Die geistige Idee einer verkörperten Codierung ist das Ergebnis einer Abstraktionsleistung. Beschreibungen symbolischer Ausdrucksformen fassen Eigenschaften zusammen, die allen Objekten dieses Produktionsprozesses gleichermaßen zukommen. Beschreibungen eines einzelnen Exemplars beziehen sich auf Eigenschaften, die nur diesem Exemplar zukommen und es von anderen Objekten unterscheiden.
**Der Mensch erkennt (interpretiert, gestaltet etc.) die Wirklichkeit, es entstehen geistige Vorstellungen, Ideen. (Wie Ideen entstehen, wissen wir nicht; ob sie von den Eindrücken der Wirklichkeit abhängen, ob sie von Gott eingegeben werden, oder ob der Mensch sie in einem schöpferischen Akt selbst hervorbringt, ist unbekannt). Geistige Ideen können kommuniziert werden, wir können Kommunikation als Austausch von Teilen geistiger Ideen durch Mosaike von Symbolen verstehen. Uns interessiert die schriftbasierte Kommunikation, also der Austausch schriftbasierter symbolischer Ausdrucksformen. Um eine geistige Idee als schriftbasiertes Symbol ausdrücken zu können, müssen wir diese Symbole in einem physischen Medium festhalten, kodieren. Die Ägypter drückten Keile in Tontafeln, die Phönizier hatten spätestens im 11. Jahrhundert v. Chr. eine Schrift aus 22 Zeichen entwickelt, auf der auch unsere heutige lateinische Schrift basiert (https://de.wikipedia.org/wiki/Geschichte_des_Alphabets). Schriftzeichen sind nicht identisch mit Symbolen; Zeichenfolgen verschlüsseln Mosaike aus Symbolen.
In “dem” semiotischen Dreieck wird suggeriert, dass es sich um ein einzelnes Zeichen handelt, das eine Bedeutung hat. In wenigen ausgewählten Kontexten ist dies tatsächlich der Fall: Der kursiv gedruckte griechische Buchstabe π ist in mathematischen Kontexten ein Zeichen oder Symbol für die Kreiszahl Pi; in den sozialen Medien definiert das Hash-Zeichen # Hashtags, ein einzelnes vorgezeichnetes b in einer Partitur einen bestimmten Tonraum.
Viel häufiger aber wird nicht mit einem einzelnen Zeichen (Symbol, Wort) kommuniziert, sondern mit einem Mosaik aus Zeichen, Symbolen, ganzen Sätzen, umfangreicheren Beschreibungen. Die Semiotik irrt, wenn sie das einzelne Zeichen oder Symbol als die wichtigste bedeutungstragende Einheit betrachtet. Natürlich haben π, # oder b in der Mathematik, in den sozialen Medien, in der Musik eine “Bedeutung”. Aber nicht die einzelnen Zeichen, sondern erst das gesamte Mosaik von Symbolen drückt einen geistigen Inhalt aus.