Vokabular, Taxonomie, Ontologie, Theorie#
Wortlisten, Schlagwortverzeichnisse, Glossare, Terminologien, Taxonomien, eine Ontologie können in einer Reihe zunehmender Komplexität angeordnet werden. In dieser Reihung verhält es sich wie beim Gehen lernen, die ersten Schritte sind die schwierigsten. Bei uns liegt die Schwierigkeit im Übergang vom Wort zum Begriff. Die Bedeutung von Begriffen wie „Bedeutung“ oder „Begriff“ wird in der Philosophie notorisch kontrovers diskutiert. auch wir werden selbstverständlich keine abschließende Klärung herbeiführen können. Anstelle einer Begriffsklärung soll eine phänomenologische Erkundung des Gegenstandsbereichs sichtbar machen, wo Bezeichnungsprozesse in diesem Übergang eine Rolle spielen.
Vom Wort zum Begriff#
Ausgangspunkt: Formeln in der Schulmathematik werden oft zuerst anschaulich, dann formal eingeführt, zum Beispiel so:
“Geschwindigkeit ist der Weg, den man in einer bestimmten Zeit zurücklegt”
also
v = s / t.
Was passiert, wenn man auf diese Weise “formalisiert”?
Im engeren Sinn bedeutet Formalisierung die Beschreibung eines Phänomens oder die Formulierung einer Theorie in einer formalen Sprache, deren Axiomatisierung und – als letzte Stufe – die Kalkülisierung (siehe Formalisierte Theorie). [ … ] So ist die mathematische Logik durch Formalisierung gekennzeichnet. Man formalisiert ein System der Logik, indem man von der vorgegebenen Intension der in ihm vorkommenden Ausdrücke absieht und diese Ausdrücke in genau dem Sinn verwendet, den die Axiome bzw. die Regeln dieses Systems diesem vorschreiben. „Die Aussagenlogik und die Prädikatenlogik lassen sich als Formalisierungen des alltäglichen logischen Schließens ansehen.“ https://de.wikipedia.org/wiki/Formalisierung
Problem: Die Sprache der Mathematik selbst bietet uns keine geeignete Meta- oder Hintergrundsprache für die Formalisierung von Konzepten. Gründe:
Die Mathematik selbst hält sich für umso exakter, eleganter, mathematischer, schöner, reiner, je weniger sie auf Anschauung oder Welt zurückgreift und je abstrakter sie ist. Mathematik ist nicht angewandt, sondern weltabgewandt.
Mathematik wird axiomatisch entwickelt. Die ersten Axiome sind reine Setzungen, sie beanspruchen keine Begründung in der Welt. Maßgeblich ist hier das Bourbaki-Programm.
Ein großer Teil unseres mathematischen und wissenschaftstheoretischen Diskurses verwendet Argumentationen, die sich nur in höherstufigen Prädikatenlogiken formalisieren lassen und damit ohnehin unvollständig und unentscheidbar sind.
Die wissenschaftstheoretische Position des logischen Empirismus hat sich nicht bewährt. Mit formalen Systemen lässt sich die Welt nicht so umfassend abbilden, wie die Mitglieder des Wiener Kreises glaubten (sic!). (Wenn die heutige KI in die Fußstapfen des logischen Empirismus tritt, muss sie scheitern. Wenn sie scheinbar erfolgreich ist, dann deshalb, weil wichtige Protagonisten dieses Scheitern nicht sehen wollen oder ihr Denken so eingeengt haben, dass sie es nicht sehen können). (Zitat: Ralf Kese)
Das eigentliche Erkenntnisinteresse der Mathematiker liegt in den Beziehungen abstrakter Strukturen untereinander. Die reale Welt ist dabei kaum von Interesse. Wenn wir aber Ontologien konstruieren, dann gibt es ein Primat der Realität.
Wir wollen die Modellbildung durch den Aufbau logisch begründeter Begriffssysteme unterstützen. Die Konstruktion von Begriffen und ihren Beziehungen ist eine anspruchsvolle Aufgabe, die grundlegend für jede strukturwissenschaftliche Tätigkeit ist.
Dabei stellt sich die Frage: Wie kommen wir von der in Worte gefassten Idee zum formalisierten, durch Symbole referenzierten Begriffssystem?
Entwicklung eines Begriffs: vom Wort zum Begriff#
Wir stellen uns vor, ein philosophisch interessierter Autor schreibt in seinem privaten Forschungsjournal folgenden Text:
Wir gehen spazieren, ein Problem im Gepäck, und sind nun auf die Lösung gekommen … die wollen wir aufschreiben … dazu formulieren wir Text mündlich im Kopf … keine wohlformulierten Vortragssequenzen im Hörsaal, sondern informelle Selbstgespräche, Gedankensplitter … die wir auch aufschreiben, in der Form z.B. wie hier ein Punkt-Punkt-Text … sozusagen ein mündlicher Text, der aufgeschrieben wird, kein grammatikalisch korrekter schriftlicher Text …
Dies ist offensichtlich ein natürlichsprachlicher, noch nicht formalisierter Text. Bei der Textproduktion laufen komplexe Prozesse ab:
(a) Zuvor komplex kreisende Gedanken werden serialisiert.
(b) In den meist unreflektierten, im besten Sinne naiven, unmittelbaren Sprachfluss werden einzelne reflektiert verwendete Wörter (hier z.B. “mündlich aufgeschrieben”, “schriftlich”) eingebettet.
Wir können im obigen Textabschnitt beobachten, wie Fachsprache entsteht … natürliche Sprache, Reflexionen, komplexe Gedanken … von denen einige explizit mit genauer definierten Zeichen versehen, bezeichnet und auch von anderen komplexen Gedanken unterschieden werden … Der Autor hat offensichtlich das Bedürfnis, zwischen “mündlich aufgeschrieben” und “schriftlich” zu unterscheiden … eine Unterscheidung, die es in der deutschen Umgangssprache so nicht gibt … Im obigen Absatz findet also eine Begriffsbildung statt … Übergang vom Wort zum Begriff, von der Umgangssprache zur Fachsprache.
Nächster Schritt: Verschriftlichung, Explizierung der Fachsprache, z.B. in einem Glossar:
mündliche Sprache: Wenn sich Menschen zwanglos unterhalten; oft nur Gedankenfetzen, keine “ganzen” Sätze; laut Duden “falsche” Grammatik - aber über Jahrtausende entstanden, hoch funktional; “naiv” im positiven Sinne: unmittelbar, natürlich, unverbildet, echt und damit in eigentümlicher Weise “wahr”.
Schriftsprache: wohlgeformte Grammatik; in der Regel “ganze Sätze”, in Gedichten auch einzelne Phrasen, die aber in sich grammatikalisch korrekt sind.
**geschriebene Sprache: entsteht z.B. bei der Niederschrift (Transkription) einer Tonbandaufnahme mündlicher Sprache; aber auch getippte mündliche Sprache, heute oft in sozialen Medien, vor allem bei Kurznachrichten.
Was hier passiert ist: Drei Begriffe werden eingeführt und durch Erläuterungen voneinander unterschieden … worin die Unterschiede bestehen, ist noch nicht ganz klar, und auch die Erläuterungen sind etwas verwirrend, aber das macht nichts: Wir hören wohlwollend zu; akzeptieren, dass der Autor drei Dinge unterscheiden und benennen will. Wir treten in einen realen oder fiktiven Dialog mit dem Autor, um ihn besser zu verstehen.
Wir wollen den Autor wohlwollend verstehen: Wir versuchen, den Kern der Unterscheidung zu verstehen, sie durch zusätzliche Beispiele zu veranschaulichen, vielleicht zusätzliche Merkmale zu finden, mit denen sich die Begriffe noch besser unterscheiden lassen. Dabei werden wir auch Beispiele finden, die sich nicht eindeutig einem der Begriffe zuordnen lassen: Die sind noch sehr wertvoll, die behalten wir, die schreiben wir auf ein Flipchart mit der Überschrift “Grenzfälle”, aber das machen wir nicht: Wir benutzen sie nicht böswillig als Waffe, um zu zeigen, wie brüchig oder gar unsinnig die noch in den Kinderschuhen steckenden Unterscheidungen sind.
Unser Ziel ist es, selbst gut zu verstehen, was mit den neuen Begriffen gemeint ist. Man nennt das auch einen Begriff entwickeln (hier: einen Begriff von “mündlich”, “aufgeschrieben” und “schriftlich”).
Man wird sich dabei auch überlegen, welche unserer Begriffe sich teilweise ausschließen, oder sich auch vereinbaren lassen: Wenn der Autor betont, dass sich mündliche Sprache auch “aufgeschrieben” (z.B. über die Tastatur des Smartphones) tansportieren lässt, dann sollten wir auch einen Begriff für den Normalfall haben, z.B. “akustisch”. Und wenn in der Erläuterung von schriftlicher Sprache auf “ganze Sätze” oder “wohlgeformte Grammatik” so großer Wert gelegt wird, sollten wir vielleicht “grammatisch” versus “ungrammatisch” als charakteristisches Unterscheidungsmerkmal zwischen mündlich - egal ob akustisch oder aufgeschrieben - und schriftlich in Betracht ziehen?

Wenn man nun versucht wäre, in einem Fachwörterbuch nach den “richtigen” Begriffen zu suchen, käme das einer sofortigen wissenschaftlichen Kapitulation gleich - denn wir sind ja gerade dabei, eine Terminologie aus unserer eigenen Sicht zu entwickeln, sei es, weil es sie noch nicht gibt, sei es, weil wir selbst Experten sind, die ein solches Fachwörterbuch selbst erstellen und dafür ein konsistentes, als Ontologie formalisiertes Begriffssystem generieren wollen; weil es natürlich einen etablierten Sprachgebrauch für “mündlich” und “schriftlich” gibt, den der Autor des obigen Absatzes natürlich kennt, den er aber im Hinblick auf die Neuen Medien und neuere Formen des Terminologiemanagements stellenweise für inadäquat hält und zu dem er einen alternativen Entwurf vorlegen möchte.
Sehr geehrte Leserin, sehr geehrter Leser, fällt Ihnen an dem vorstehenden Absatz etwas auf? Richtig: Der Absatz besteht aus einem einzigen Satz. Kann diese geschriebene Sprache auch akustisch transportiert werden? Nach der bisher entwickelten Terminologie ist das kein Widerspruch. Der Satz kann z.B. in einem Vortrag vorgelesen werden, auch wenn dieser akustische Transport die Rezipienten noch mehr verwirren dürfte als die schriftliche Form. Wir fügen also die grammatische Komplexität als ein - hier durchgängiges - Unterscheidungsmerkmal zwischen “mündlich” und “schriftlich” hinzu.
Übergänge#
Ü1: Übergang von der synchronen, an einen Zeitablauf gebundenen Kommunikation zur asynchronen, nicht mehr an einen Zeitablauf gebundenen Kommunikation; charakteristische Merkmale:
synchron
gleiche Geschwindigkeit für Sender und Empfänger
online, stream, rein sequentiell
gleichzeitige Vollduplex-Kommunikation
asynchron
“index-sequentiell”, man kann alle Stellen praktisch gleichzeitig sehen
Mediale Repräsentation ist bei asynchroner Kommunikation sachlich unumgänglich, aber kein Definitionsmerkmal. Auch synchrone Kommunikation kann dargestellt werden, z.B. die Aufzeichnung eines Gesprächs auf Tonband, einer Vorlesung auf Video. Aber auch ein aufgezeichnetes Video bleibt im Wesentlichen ein Stream.
Ü2: Übergang von der Mund-Ohr-Kommunikation zur zeichenhaften Hand-Auge-Kommunikation: geschriebener Text, Visualisierung, Bild, Grafik etc:
Einführung des Zeichenhaften bei gleichzeitiger Komposition von Zeichen zu einem Satz, einem Bild, einer Informationsgrafik, einem UML-Diagramm etc.
fast immer medial repräsentiert (Ausnahme: Gebärdensprache)
da medial repräsentiert auch asynchron; Grenzfall: nahezu synchrone Kommunikation über Whatsapp
Es geht hier nicht um die Einführung einzelner Gebärden, sondern um die “Darstellung” von gesprochenem Text in geschriebenen Sätzen oder zeichenhaft zusammengesetzten Diagrammen.
Ü3: Übergang vom Wort (Term, Bezeichnung, Name, Label) zum Begriff. Beispiel: *Unsere Tankstelle an der Ecke hat sieben Tage die Woche, Tag und Nacht geöffnet. Das Wort “Tag” hat an der ersten Stelle die Bedeutung “24-Stunden-Zeitraum”, an der zweiten Stelle die Bedeutung “Zeit zwischen Sonnenaufgang und Sonnenuntergang”. Charakteristischer Unterschied:
viel weniger Polysemie
Umgangssprache vs. Fachsprache
Ü4: Übergang von der natürlichsprachlichen Ebene (Mündlichkeit, Schriftlichkeit) zur formalsprachlichen Ebene (die sich in den Strukturwissenschaften eigentlich nur schriftlich entwickelt hat); charakteristischer Unterschied:
formalisierte Zeichen - was immer das heißen mag
kontextfreie Grammatik (Typ-2-Grammatik in der Chomsky-Hierarchie)
ausschließlich (Fach-) Begriffe werden formalisiert
Wenn wir eine Ontologie aufbauen, beginnen wir meist mit Wissensrepräsentationen, die meist schon zeichenhaft medial repräsentiert sind und vorwiegend natürlichsprachlich kommuniziert werden, und versuchen Glasperlenspiele zu bauen (siehe sect-theorie-stegmueller). Das Problem dabei ist, dass viele anspruchsvolle Übergänge gleichzeitig stattfinden müssen. Das funktioniert selten!
Im Idealfall suchen wir also nach Methoden, diese verschiedenen Übergänge
einzeln zu unterstützen
gleichzeitig und nebeneinander stattfinden zu lassen
nachvollziehbar und transparent zu gestalten
TBD#
Zwiebelschalen-Modell aus Babelsberg; Rückbezug auf Einführung, nochmal die Rolle von Wikipedia
M%C3%BCnchhausen-Trilemma
https://de.wikipedia.org/wiki/Münchhausen-Trilemma
Als Münchhausen-Trilemma wird ein von Hans Albert formuliertes philosophisches Problem bezeichnet. Es geht um die Frage, ob es möglich sei, einen „letzten Grund“ (im Sinne einer letzten Ursache bzw. eines unhintergehbaren ersten Anfangs) zu finden bzw. wissenschaftlich zu beweisen.
Das Münchhausen-Trilemma bedeutet, dass jeder Versuch des Beweises eines letzten Grundes zu einem von drei möglichen Ergebnissen führt:
zu einem Zirkelschluss (die Conclusio soll die Prämisse beweisen, benötigt diese aber, um die Conclusio zu formulieren)
zu einem infiniten Regress (es wird immer wieder eine neue Hypothese über die Begründbarkeit eines letzten Grundes formuliert, die sich jedoch wiederum als unzureichend erweist oder wieder in einen Zirkel führt)
zum Abbruch des Verfahrens an einer Stelle und der Dogmatisierung der dortigen Begründung.
Um Begriffe zu beschreiben, verwenden wir zunächst die natürliche Sprache. Es wäre ein Zirkelschluss, in der Beschreibung eines Begriffes diesen Begriff selbst wieder zu verwenden. Daraus folgt eine Absage an das axiomatische Verfahren der Mathematik. Wir haben keine Grundbegriffe, aus denen wir alles andere ableiten können. Stattdessen gehen wir davon aus, dass insbesondere Grundbegriffe am besten mit den Mitteln der natürlichen Sprache eingeführt werden können. Besonders hilfreich sind dabei lebensweltlich unmittelbar verständliche Einsichten, Erfahrungen, Metaphern, Geschichten; abzulehnen ist alles, was an Fachsprache, Logik, Deduktion erinnert.
Beispiel: Die Seite https://www.w3.org/TR/rdf12-concepts/ führt IRI unter Rückgriff auf das nicht weiter definierte Wort denotieren ein:
Any IRI or literal denotes something in the world (the “universe of discourse”). Diese Dinge werden Ressourcen genannt.
Wer an dieser Stelle auf die Idee kommt, über das Wort “denotieren” nachzudenken, vielleicht sogar einen Fachbegriff vermutet, gar sein Vorwissen aktiviert und an „das“ semiotische Dreieck denkt - der hat schon verloren. Richtig ist, dass der Zusammenhang von Name, Zeichen, Begriff, Bedeutung, Denken eines der großen Probleme der Philosophie ist. Falsch ist, dass das Verständnis solcher Theorien an dieser Stelle notwendig oder auch nur möglich ist. Tatsächlich geht es in vielen dieser Theorien darum, Begriffe wie “denotieren” überhaupt erst als Ergebnis einer langen Theorieentwicklung zu konstruieren.
Als Konseque verzichten wir auf einen axiomatischen Ansatz und setzen stattdessen auf eine natürliche Sprache mit einem hohen Grad an Unbestimmtheit und Offenheit, auf eine reiche Metaphorik, auf den Bezug zur unmittelbaren Lebenswelt. Wir setzen keine Fachbegriffe voraus, weder real existierende, noch undefinierte Pseudo-Fachbegriffe. Stattdessen versuchen wir zunächst, in natürlicher Sprache ein Begriffsverständnis aufzubauen, erst dann solche Begriffe auch zu benennen und ggf. auch zu axiomatisieren. Wo wir doch an definierte Begriffe anknüpfen, versuchen wir an Wikipedia anschlussfähig zu sein.
Vom Begriff zur Theorie#
REDAKTION
Wortverzeichnis (Rechtschreib-Wörterbuch), Begriffswörterbuch, Gazetteer, Glossar, Wiki, Thesaurus, Terminologie, Taxonomie, Ontologie – Modell, Glasperlenspiel, Theorie (Stegmüller)?
Zusammenfassung von https://www.isko.org/cyclo/ontologies
Abbildung:
Guarino_2006_Figure_4_The_ontological_precision.jpg
Wörter-, Namens-, Ortsverzeichnisse#
auch Rechtschreib-Wörterbuch, Ortslexikon (Gazetteer)
Archäologie:
Städte, Gemeinden etc. in DCAT-AP:
https://www.xrepository.de/details/urn:de:bund:destatis:bevoelkerungsstatistik:schluessel:kreis
https://www.xrepository.de/details/urn:de:bund:destatis:bevoelkerungsstatistik:schluessel:bezirk
https://www.xrepository.de/details/urn:de:bund:destatis:bevoelkerungsstatistik:schluessel:ags
https://www.xrepository.de/details/urn:de:bund:destatis:bevoelkerungsstatistik:schluessel:rs
https://www.xrepository.de/details/urn:de:bund:destatis:bevoelkerungsstatistik:schluessel:bundesland
Glossar#
strukturähnlich: Bedeutungswörterbuch
Beispiel für ein Glossar: Linked Data Glossary W3C Working Group Note 27 June 2013, https://dvcs.w3.org/hg/gld/raw-file/default/glossary/index.html
Wiki#
Ein Glossar, bei dem die Erklärungen durch Links miteinander vernetzt sind … Semantik der Links ist nicht definiert, nämlich http-Protokoll, also Dateien und Datei-Fragmente … dennoch werden in der Praxis die einzelnen Wikipedia-Seiten auch als Proxy für die jeweils beschriebene Entität verwendet.
Thesaurus#
Terminologie#
dict.leo.org > terminology übersetzt terminology naturgemäß uneinheitlich mit Fachvokabular, Ausdrucksweise, Bezeichnungsweise, Fachsprache, Fachwortschatz, Begriffsbestimmung, Begriffsdefinition, Begriffswörterbuch oder Fachsprache.
Im Beitrag “Terminus” im Historischen Wörterbuch der Philosophie werden Terme als Resultate anspruchsvoller intellektuer Tätigkeit beschrieben:
T. kann damit sowohl das Produkt oder Endergebnis eines Erkenntnisvorgangs als auch das sein, worauf die Erkenntnis sich als ihr Ziel richtet, das Objekt. [ … ] Thomas von Aquin sagt vom inneren Wort («verbum interius»), dem fertigen Begriff, es sei die erkannte Intention und damit der Endpunkt («terminus») des intellektiven Vorgangs […] DOI: 10.24894/HWPh.4253
Unter Fachleuten der Technischen Kommunikation wird der Begriff (oder Term?) Term nicht im Sinne von “Begriff”, sondern als Benennung eines Begriffs verwendet. Die Nähe von Term zu Nomen entspricht ISO 1087-1:
[…] definiert ISO 1087-1 (2000:6) term als: „verbal designation of a general concept in a specific subject field.“ Hier entspricht term der deutschen „Benennung“ und designation der „Bezeichnung“. https://de.wikipedia.org/wiki/Terminus
In der DIN 2342 werden Term und Begriff als ein “zusammenhängendes Paar” aus sprachlichem Ausdruck und Begriff behandelt:
Die DIN 2342 (1992:3) Begriffe der Terminologielehre definiert: „Terminus (auch: Fachwort): Das zusammengehörige Paar aus einem Begriff und seiner Benennung als Element einer Terminologie.“ […] unter Terminus [ wird ] nicht nur der sprachliche Ausdruck, sondern auch dessen Bedeutungsinhalt (Begriff) verstanden […] (Arntz, Picht und Mayer (Einführung in die Terminologiearbeit. Hildesheim u. a. 2004), zitiert nach https://de.wikipedia.org/wiki/Terminus)
Laut DIN 2342 ist eine Terminologie ein System von ein-eindeutig bezeichneten Begriffen:
DIN 2342 (2011, S. 16) definiert Terminologie als den „Gesamtbestand der Begriffe und ihrer Bezeichnungen in einem Fachgebiet“. (Drewer und Schmitz, Terminologiemanagement, 2017, S.6)
Da professionelle Terminologiearbeit heute nicht auf der Ebene von Lexemen, sondern eher auf der Ebene von Begriffen betrieben wird, liegt die Interpretation nahe, dass Terminologiearbeit ein Fachwort* oder einen Fachausdruck* aus dem Bereich des Lexikons herausführt und in den Bereich der Begriffe hineinführt. Insgesamt ist es sinnvoll, “Terminus” als eindeutige Bezeichnung für einen Begriff zu verwenden, für den (Begriff) in einer (meist Fach-)Sprache mindestens eine eindeutige Primärbezeichnung und ggf. weitere Sekundärbezeichnungen festgelegt wurden. Terminologiemanagement in diesem Sinne ist kein begriffsloses Benennungs-, sondern ein sprachgebundenes Begriffs- und Benennungsmanagement.
Semantisches Netz#
REDAKTION
Kurze Einführung … ein KOS … Problem benennen: Semantik der Kanten? … ausführlich unten XXXX
Taxonomie#
REDAKTION
Klassifikationssystem … relativ rigide Meta-Ontologie dahinter: Klassen lassen sich durch ihre charakteristischen Eigenschaften unterscheiden … Ontologie als Unterschieds-Lehre; ausführlicher auch unten XXXXXXX
Ontologie#
REDAKTION
Allgemeine, im Idealfall gerade noch berechbare Formalisierung … bisweilen auch OWL Full, modal etc.: In dieser Form nur noch geeignet als Kommunikation zwischen Menschen; dann gibt es aber oft auch weniger aussagemächtige Abzüge
Theorie#
REDAKTION
Formalisierung als Theoriekern … normalsprachliche Brückentheorie, nicht formalisierbar … in der GenDifS Methodik ist das die Verankerung in Wikipedia
e_strukturalismus_stegmueller; auch Klaus Manhard, Zemlinsky (??)
(Der vorliegende Text versucht, eine Ontologie als einen Teil des Theoriekerns im Kontext der Strukturalistischen Theorienkonzeption Wolfgang Stegmüllers zu verstehen. Das ist eine wissenschaftstheoretische Position aus der zweiten Hälfte des 20. Jhdt, die z.B. auf der Homepage von Klaus Manhart sehr anschaulich dargestellt wird.)
Ontologien sind Terminologien, die besonders weitgehend formal-logisch formalisiert wurden. Ontologien formalisieren nicht nur Begriffe, sondern normieren sie auch. Wenn Wittgenstein recht hat, dass die Grenzen meiner Sprache die Grenzen meiner Welt bedeuten, greifen Ontologien in Denken ein. Es stellt sich die wissenschaftstheoretische Frage, wie wir die “Wahrheit” oder “Angemessenheit” einer Ontologie beurteilen können.
In Einführungen in „die“ Logik wird oft die vereinfachende Annahme gemacht, dass sich die “Bedeutung” eines Ausdrucks aus den Bedeutungen seiner Teilausdrücke zusammensetzt (Frege-Prinzip, Kompositionalitätsthese). Dementsprechend können Zusammenhänge zwischen verschiedenen Begriffen auch durch die Analyse grammatischer Strukturen der Umgangs- oder Schriftsprache erschlossen werden. Wer sich intensiver mit menschlichem Denken und Sprache beschäftigt, erkennt, dass diese Vereinfachung wesentliche Aspekte des Denkens vernachlässigt. Vielmehr ist die menschliche Sprache ein Faszinosum, das durch seine Unschärfe und seine Einbettung in menschliche Handlungszusammenhänge immer wieder neue Bedeutungen erzeugt.
Sprache als Faszinosum zu betrachten heißt nicht, dass man Sprache nicht auch der mathematisch-strukturwissenschaftlichen Modellierung zuführen kann. Es heißt nur, dass man sich darauf einstellen sollte, dass die mathematisch-strukturwissenschaftliche Modellierung nur Teilaspekte von Sprache abbilden kann und dass man gut daran tut, auch die nicht abbildbaren Aspekte im Blick zu behalten. (“Im Blick behalten” ist natürlich ein metaphorischer Ausdruck, und in der Tat leisten Metaphern einen wichtigen Beitrag zur sprachlichen Verständigung über formal nicht abbildbare Kommunikationsinhalte).
Terminologien erklären Begriffe und Ontologien fügen dem eine formale Ebene hinzu. Grundsätzlich werden verschiedene Arten von Definitionen unterschieden:
“Eine Realdefinition oder Sacherklärung ist eine Definition, die Aussagen über Eigenschaften eines Gegenstandes oder Sachverhalts enthält, die im Hinblick auf diesen Gegenstand oder Sachverhalt für wesentlich gehalten werden. […] Eine Realdefinition ist also […] informativ bezüglich des Bezeichneten.” https://de.wikipedia.org/wiki/Realdefinition
“Eine Nominaldefinition ist die Festlegung der Bedeutung eines Begriffs (Definiendum) durch einen bereits bekannten Begriff oder mehrere bereits bekannte Begriffe (Definiens). Da das Definiendum bedeutungsgleich mit dem Definiens ist, könnte man von einer tautologischen Umformung sprechen. […] Nominaldefinitionen enthalten keine empirischen Informationen und erleichtern so z. B. Diskussionen über Fachjargon. Sie können folglich auch nicht wahr oder falsch sein, sondern erweisen sich in der konkreten Verwendung als brauchbar/zweckmäßig bzw. als unbrauchbar/unzweckmäßig. Sie sind normativ.” https://de.wikipedia.org/wiki/Nominaldefinition
Formale Systeme bewegen sich immer und ausschließlich auf der nominalen Ebene. Manche Mathematiker sind geradezu stolz darauf, sich in rein formalen Räumen zu bewegen und Beziehungen ohne Bezug zur realen Welt herzustellen. Ihre Welt ist die der abstrakten Glasperlenspiele, und in der Konstruktion solcher Spiele sind sie Nichtmathematikern haushoch überlegen.
Umgekehrt gilt: Die Mathematik als Wissenschaft bietet keine Methodik für die Anwendung und Anwendbarkeit von Glasperlenspielen. Wenn überhaupt, dann sind es Mathematiker-Menschen, die uns mathematische Strukturen an gut geeigneten Beispielen anschaulich erklären. Diese Erklärungskomponente ist menschlich, nicht mathematisch.
Die Unterscheidung von Glasperlenspiel und Wirklichkeit ist eine metaphorische, um Anschaulichkeit bemühte Interpretation des strukturalistischen Theoriebegriffs in der Fassung von Wolfgang Stegmüller, anschaulich dargestellt in https://www.klaus-manhart.de/mediapool/28/284587/data/07-strukturalismus.pdf. Eine Theorie besteht, kurz gesagt, aus zwei Teilen:
Der Theoriekern ist nur eine formale, mathematische Struktur, die nichts über die Welt aussagt, insbesondere auch nicht, was überhaupt von der Welt erfasst werden soll. Anders als mathematische Theorien wollen empirische Theorien aber Informationen über bestimmte Realitätsausschnitte liefern. Dies bedeutet, dass der Theoriekern in Beziehung gesetzt werden muss zu dem Weltausschnitt, den die Theorie behandeln soll. Diese für die Theorie vorgesehenen Realitätsausschnitte bezeichnet man als Menge der intendierten Anwendungen und benutzt dafür das Symbol I. https://www.klaus-manhart.de/mediapool/28/284587/data/07-strukturalismus.pdf, S. 10
Eine Ontologie - d.h. einen Zustand eines Glasperlenspiels - als formalisierte Terminologie zu interpretieren, bedeutet anzugeben, welche Brücken zwischen den formalen Symbolen und der Wirklichkeit bestehen. Im strukturalistischen Theorieverständnis kann dies nur informell geschehen. Die Brücken zwischen Glasperlenspiel und Wirklichkeit sind umso tragfähiger, je weniger fachsprachliche Anteile in ihre Konstruktion einfließen. (Dies ist eine empirische These, die auch falsch sein kann):
Halte Realdefinitionen und Nominaldefinitionen klar voneinander getrennt und vermische sie nicht.
Verwende für Realdefinitionen eine anschauliche, empirisch aussagekräftige, metaphorische Sprache.
Vermeide es insbesondere, in Realdefinitionen auch Nominaldefinitionen einzubetten.
Integraler Bestandteil einer Ontologie muss es sein, mit Hilfe von Realdefinitionen Vorstellungen von Begriffen zu kommunizieren, die von anderen zu formalisierenden Begriffen weitestgehend unabhängig sind. Denn nur vor dem Hintergrund einer von Nominaldefinitionen unabhängigen Kommunikation können die vielfältigen logischen Axiome von Begriffssystemen aufgestellt und auf ihre Angemessenheit hin überprüft werden.
Kompakte Zusammenfassung: Was ist eine Theorie? Ein Glasperlenspiel kann der Kern einer Theorie sein. Die Steine entsprechen Dingen in der Welt; die Position der Steine spiegelt die Beziehung der Dinge in der Welt wider; die Spielregeln legen fest, wie und von wem die Steine bewegt werden dürfen: So wird das Glasperlenspiel zu einem Modell der Welt. Eine sehr einfache Theorie ist z.B. “alles fließt”, eine andere “e = m * c^2”; auch ein ausführbares Logikprogramm, z.B. in PROLOG formuliert, kann als Theorie betrachtet werden (Klaus Manhard). Dazu müssen wir sagen, welche Steine welchen Dingen in der Welt entsprechen; und auch, welche Teile oder Sachverhalte in der Welt der Mechanik des Spiels entsprechen; diese Angaben sind die Brücke vom Kern der Theorie zur Welt. Wenn die Brücke von Menschen gemacht und von Menschen verstanden werden soll, und wenn die modellierte Welt die analoge Welt ist, dann wird diese Brücke in natürlicher Sprache kommuniziert. Eine Theorie besteht immer aus Theorie-Kern und Theorie-Brücke. Theorien haben einen beabsichtigten Anwendungsbereich, d.h. wir können angeben, welcher Teil von Welt sich wie ein bestimmtes Glasperlenspiel verhält. Da die reale Welt komplexer und vielfältiger ist als alle Glasperlenspiele zusammen, reduziert eine Theorie Ausschnitte der Welt auf wenige Aspekte. Die gleiche Theorie kann verschiedene Ausschnitte der Welt beschreiben; und ähnliche Ausschnitte der Welt können manchmal nur mit verschiedenen Theorien beschrieben werden, je nachdem, welche Phänomene man beschreiben will (wir kennen das aus dem sogenannten Welle-Teilchen-Dualismus). Bestandteile einer Theorie sind also: der Kern, der u.a. aus Glasperlen und Verschieberegeln besteht; die Brücke, die in natürlicher Sprache kommuniziert wird; und die beabsichtigten Anwendungsbereiche, die ebenfalls in natürlicher Sprache kommuniziert werden.
Ebenen von Ontologien#
Das sog. “Semantic Web” modelliert einen Gegenstandsbereich durch die Definition und Vernetzung von Begriffen; es entsteht im Wortsinn ein weltweit verknüpftes semantisches Netz. Die Knoten (Begriffe, Inhaltsbausteine) und Kanten (Links, Relationen) dieses Netzes sind mit Etiketten versehen, die die Bedeutung - die Semantik - der Teilnetze und ihrer Inhalte einheitlich definieren.
Die folgende Abbildung aus http://www.w3.org/TR/swbp-classes-as-values/ zeigt ein solches Teilnetz exemplarisch:
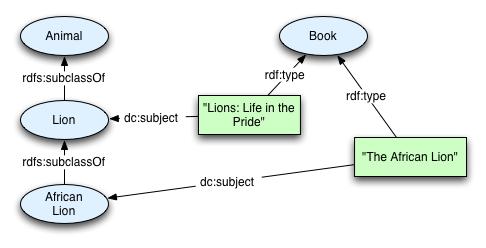
Im Spiel sind hier vier z.T. quer zueinander stehende Ebenen:
Auf der Sachebene werden die Dinge selbst beschrieben und zueinander in Beziehung gesetzt.
Im obigen Beispiel wird das Objekt Lions: Life in the Pride durch die Relation cd:subject mit dem Objekt Lion in Beziehung gesetzt.
Schriftlich-grafisch werden im obigen Beispiel die Objekte selbst durch gelbe Rechtecke dargestellt.
Auf der Metaebene werden Klassen und Relationstypen definiert. Die Metaebene legt fest, welche Verknüpfungen auf der Sachebene strukturell angemessen oder zulässig sind bzw. was aus den Verknüpfungen auf der Sachebene abgeleitet werden kann.
Im obigen Beispiel sind z.B. Löwe oder Buch als Klassen definiert.
Schriftlich-grafisch werden Klassen im obigen Beispiel durch blaue Ellipsen dargestellt.
Auf der Meta-Meta-Ebene wird diskutiert, welche Strukturen der Meta-Ebene zugrunde liegen.
In unserem Beispiel gibt es offensichtlich Klassen, Instanzen und Beziehungen.
Semantik vs. Syntax#
Das Semantic Web zeichnet sich dadurch aus, dass nicht die Syntax (das Format) der Inhalte vernetzt wird, sondern die Semantik (die Bedeutung) der Inhalte.
Eine Syntax, also ein Dateiformat, gibt an, in welcher Form Daten gespeichert werden und wie sie gelesen werden können (Manifestations-Ebene). Eine Syntax entspricht der Schreibweise eines Satzes.
Beispiel: Der Satz Das Buch ‘Löwen im Rudel’ handelt von Löwen ist syntaktisch korrekt, er folgt der Satzstruktur Subjekt-Satz > Prädikat > Objekt-Satz.
Bekannte Textformate sind z.B. Office, Plaintext, XML
Relevante Datenformate aus dem Semantic Web sind z.B. RDF/XML, Turtle, RDF striped, RDFa, OWL/XML, OWL Manchester Syntax und einige mehr.
Eine Semantik gibt – ergänzend zur Syntax – Auskunft über die Bedeutung der Daten. Die Datenhaltung dafür ist in vielen Dateiformaten möglich und prinzipiell unabhängig von bestimmten Dateiformaten. Daher ist es auch möglich – und notwendig – nahezu beliebige Datenformate in eine einheitliche Bedeutungsschicht zu überführen. (Man spricht dann von semantischer Datenintegration).
Beispiel: Der Satz Das Buch ‘Löwen im Rudel’ handelt von Löwen ist semantisch korrekt: Beide darin enthaltenen Aussagen ‘Löwen im Rudel’ ist ein Buch und ‘Löwen im Rudel’ beschreibt das Leben von Löwen sind wahr.
Relevante Sprachen zur Definition einer Semantik sind z.B. Web Ontology Language (OWL), Frame Logic oder Rich Description Framework (RDF).
Das Verhältnis von Syntax und Semantik lässt sich zwar in einem Schichtenmodell beschreiben. Dies wird sowohl im Semantic Web Stack W als auch in der Linguistik als Verhältnis von Syntax, Semantik und Pragmatik behandelt.
Für die Untersuchung der verschiedenen Ebenen von Ontologien ist diese Unterscheidung jedoch nicht hilfreich und wird hier nur zur Vermeidung von Verwechslungen erwähnt.
Sachebene und Metaebene: Aussagen und ihre Terminologie#
Die Sachebene stellt die eigentliche Faktenbasis dar. Sie wird manchmal auch als Aussagenebene (box of assertions) bezeichnet. In unserem Beispiel ist die Sachebene textuell gegeben durch Begriffe wie “Lion”, “African Lion” oder Relationen wie “dc:subject” oder “rdf:type”.
Die Metaebene - man spricht hier auch von der Terminologie (terminology box) - entwickelt das Begriffssystem, das für die Beschriftung (hauptsächlich der Kanten) des Netzes verwendet wird In unserem Beispiel gehört die Kantenbeschriftung “rdf:subclassOf” zur Metaebene: Hier wird zum Beispiel ausgedrückt, dass jedes Element der Klasse “Lion” automatisch auch ein Element der Klasse “Animal” ist. Das Ergebnis ist eine sogenannte “Klassifikation”.
Kanten mit dem Label “rdf:type” verbinden die Aussagenebene mit der Terminologieebene. In unserem Beispiel wird ausgedrückt, dass das Objekt “Der afrikanische Löwe” ein Element der Klasse “Buch” ist. Der Prozess, eine solche Klassenzugehörigkeit zu bestimmen, wird “Klassifikation” oder “Prädikation” genannt.
Wie in der aristotelischen Logik ist es durchaus möglich, dasselbe Ding gleichzeitig verschiedenen Klassen zuzuordnen. In der Praxis des Knowledge Engineering ist dies sogar der Normalfall: Fast nie lässt sich die Terminologie eines Gegenstandsbereichs als Baum von Begriffen rekonstruieren. Meist entsteht ein Netz (eine sogenannte Polyhierarchie) von Begriffen.
Häufig werden die vielen Begriffe einer Terminologie noch in Ebenen zunehmender Allgemeinheit geordnet:
Domänen-Ontologie, z.B. Tourismus-Ontologie http://www.harmonet.org/
Integrations-Ontologie
mittlere Ebene
fundamental, upper level oder top level ontology, z.B. SUMO oder DOLCE DnS
Es entstehen Schichten von Terminologien. Aus der hier entwickelten systematischen Sicht handelt es sich dabei um eine interne Partitionierung von Begriffsmengen, jedoch nicht um Metaebenen im eigentlichen Sinne. Einen Überblick über verschiedene Upper-Level-Ontologien gibt http://en.wikipedia.org/wiki/Upper_ontology_(information_science).
Meta-Metaebene: Ontologiesprachen#
Die Ontologiesprache gibt implizit vor, wie Begriffssysteme modelliert und ineinander übersetzt werden können. In unserem Beispiel sind die Modellierungsmöglichkeiten durch die Symbole unserer grafischen Modellierungssprache gegeben, wie z.B. “Klasse” (ovaler Knoten), “Instanz” (rechteckiger Knoten) oder “Eigenschaft” (gerichtete beschriftete Kante mit einfachem Pfeil).
Die formale Semantik einer Ontologiesprache zu klären ist Spezialistenarbeit. Ein elegantes Verfahren ist die Übersetzung einer abstrakteren Ontologiesprache in eine andere Ontologiesprache, deren Semantik bereits geklärt ist. Auch hier entsteht eine Schichtung von Ontologiesprachen. Als unterste Schicht – gewissermaßen die formale Basis – wird wird meist die Prädikatenlogik der ersten Stufe herangezogen.
Meta-Meta-Meta-Ebene: Hintergrundannahmen einer Ontologiesprache
Interessant ist für uns die Einsicht, dass auch eine Ontologiesprache eine Sprache im eigentlichen Sinne ist, wenn auch nur schriftlich. Als Sprache legt sie fest, was gesagt werden kann, prägt die möglichen impliziten Strukturen unserer Modelle – und sogar unseres Weltbildes?
Diese Strukturen selbst aufzudecken und zu beschreiben – und, wenn nötig, teilweise auch formal zu modellieren – gehört zur gehobenen Methodologie des Ontology Engineering.
Auf dieser Meta-Meta-Meta-Ebene werden dann Begriffe wie “open vs. closed world assumption”, “class vs. frame” oder “entity attribute value views” diskutiert.
Auf dieser Ebene wird Ontology Engineering im philosophischen Sinne ontologisch relevant – und zwar gerade auch für die Praxis: Ein Knowledge Engineer würde einen schweren Fehler begehen, wenn er die damit verbundenen philosophischen Konzepte nicht kennen oder die feinen Unterschiede zwischen den verschiedenen Sprachen übersehen würde.
In der Praxis kann ein Wissensingenieur Formalisierungen weder konstruieren noch kommunizieren – und schon gar nicht einem Wissensarbeiter ihre Bedeutung aufzeigen –, wenn er nicht in der Lage ist, die begrifflichen (sic!) Grundlagen seiner Modelle zu erklären und ihre Grenzen aufzuzeigen.
Der Begriff “Schema#
Diskussion: Eine Ontologie ist kein Datenschema. Eine XSD-Datei (XML Schema Definition) beschreibt die Struktur von (hier XML-) Dateien. Eine XSD-Beschreibung wird üblicherweise verwendet, um die - hier syntaktische - Integrität einer XML-Datei sicherzustellen, nach dem Muster: Wenn dieses Elternelement vorhanden ist, dann muss dieses Kindelement auch vorhanden sein, und dieses Kindelement darf nicht vorhanden sein.Ein XSD-Schema betrifft die Ebene der Syntax, der Formate, der Datenspeicherung, in der Sprache von WEMI die Manifestation. Die Semantik, die Bedeutung der einzelnen XML-Elemente bleibt davon völlig unberührt. Analog dazu beschreibt ein Schema im Datenbankbereich die Struktur einer Datenbank mit ihren Datentypen, Indizes, Fremdschlüsseln etc. Auch hier sichert das Schema die Integrität der Datenbank und auch hier bleibt die Semantik der einzelnen Tabellenspalten unberührt.
<Schemata können in ihrer Komplexität von einfachen Attributlisten bis hin zu komplexen Ontologien reichen. https://de.wikipedia.org/wiki/Schema_(Informatik) –>
Wenn im Zusammenhang mit Ontologien das Wort “Schema” verwendet wird, ist damit nicht das Format gemeint: Ob Ontologie-Daten als XML-Datei, als Excel-Tabelle oder im Turtle-Format gespeichert werden, spielt keine Rolle. Anders als ein XML- oder ein Datenbankschema dient eine Ontologie nicht dazu, Korrektheit zu garantieren, sondern vielmehr dazu, bisher nur implizit vorhandenes Wissen explizit zu machen. Sei z.B. liebt in geeigneter Weise als Unter-Eigenschaft von kennt definiert und in einem Wissensgraphen z.B. liebt(X, Y) ausgesagt: Dann können wir daraus auch kennt(X, Y) ableiten, explizit machen. Wir müssen nicht extra angeben, dass X Y kennt, denn diese Information ist durch das Schema bereits implizit gegeben und damit redundant. Insbesondere ist unser Wissensgraph nicht “falsch”, wenn wir diese Information nicht explizit angeben.
SKOS#
Ein Baum auf Instanzebene, keine Klassen
Simple_Knowledge_Organisation_System
https://de.wikipedia.org/wiki/Simple_Knowledge_Organisation_System
Das Simple Knowledge Organization System (SKOS, frei übersetzt „einfaches System zur Organisation von Wissen“) ist eine auf dem Resource Description Framework (RDF) und RDF-Schema (RDFS) basierende formale Sprache zur Kodierung von Dokumentationssprachen wie Thesauri, Klassifikationen oder anderen kontrollierten Vokabularen. Mit SKOS soll die einfache Veröffentlichung und Kombination kontrollierter, strukturierter und maschinenlesbarer Vokabulare für das Semantische Web ermöglicht werden.
SKOS ist eine Ontologie … die 3 (drei) Klassen definiert, insbesonder die Klasse skos:Concept … mit instanzen dieser Klasse bauen wir nun einen Knowledge Graphen in Form eines Baumees
Lizenz auch der Abbildungen: Copyright ©2005 W3C®. W3C liability trademark and document use rules apply.
Permission to copy, and distribute the contents of this document, or the W3C document from which this statement is linked, in any medium for any purpose and without fee or royalty is hereby granted, provided that you include the following on ALL copies of the document, or portions thereof, that you use:
A link or URL to the original W3C document.
The pre-existing copyright notice of the original author, or if it doesn’t exist, a notice (hypertext is preferred, but a textual representation is permitted) of the form: “Copyright © [$date-of-document] World Wide Web Consortium. https://www.w3.org/copyright/document-license-2023/”
If it exists, the STATUS of the W3C document.
Homepage SKOS:

Fig. 10 Quelle: SKOS Core Guide (2005), (c) W3C W3C Document License#
SKOS in 3 Sätzen#
SKOS in seiner Grundform ist vergleichsweise einfach aufgebaut: Resources vom Typ skos:concept (bei kleinen und mittleren Vokabularen typischerweise HashURIs) …
zeigen über labelling properties wie
skos:prefLabeloderskos:altLabelauf Literale, die wir typischerweise als Lemmata oder Nounphrases wiedererkennen;zeigen über documentation properties wie
skos:definitionauf die Definition eines Begriffs (die als Literal, als HashURI oder als ein Web Dokument angegeben sein kann, siehe SKOS Core Guide > Documentation Properties);zeigen über semantic relationships wie
skos:broader,skos:narrowerundskos:relatedauf andere Resources vom Typskos:concepthttps://www.w3.org/TR/swbp-skos-core-guide/#secrel
Weblinks#
Didaktisierte Einführungen:
Priscilla Jane Frazier: SKOS. A Guide for Information Professionals. March 2015. https://www.ala.org/alcts/resources/z687/skos
DINI Arbeitsgruppe KIM: https://dini-ag-kim.github.io/skos-einfuehrung/#/
SKOS in Linked Open Vocabularies (LOV): https://lov.linkeddata.es/dataset/lov/vocabs/skos
Details#
skos:broaderist nicht transitiv:By convention,
skos:broaderandskos:narrowerare only used to assert a direct (i.e., immediate) hierarchical link between two SKOS concepts. This provides applications with a convenient and reliable way to access the direct broader and narrower links for any given concept. Note that, to support this usage convention, the propertiesskos:broaderandskos:narrowerare not declared as transitive properties. https://www.w3.org/TR/skos-reference/#L2810SKOS verwendet eine übliche, aber in RDF nicht normierte terminologische Unterscheidung zwischen
relationship als Relation zwischen zwei Resources, sowie
property als Relation zwischen Resource und Literal.
In OWL entspricht dies der Unterscheidung zwischen object properties (
owl:ObjectProperty) und data properties (owl:DatatypeProperty) https://www.w3.org/TR/owl-ref/#PropertySKOS gibt es auch in einer XL-Version, in der die einzelnen Labels nicht als Literale, sondern als Resources modelliert sind: https://www.w3.org/TR/skos-reference/skos-xl.html
öffentliche SKOS-Vokabulare#
Einige wichtige öffentliche Vokabulare benutzen SKOS als Schema, siehe https://dini-ag-kim.github.io/skos-einfuehrung/#/skos-anwendungsbeispiele
SKOS-Visualisierungen#
Die SKOS-Dokumentation visualisiert den Unterschied von URI und Literal so:
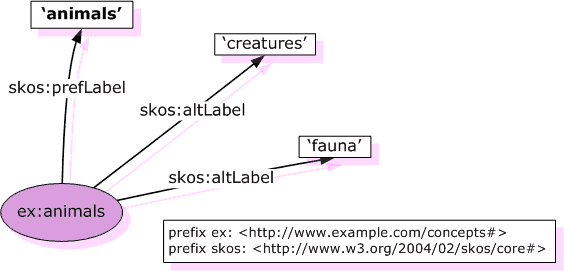
Quelle: https://www.w3.org/TR/2005/WD-swbp-skos-core-guide-20051102/
Die wesentlichen Aspekte von SKOS sind in dieser Abbildung zusammengefasst:
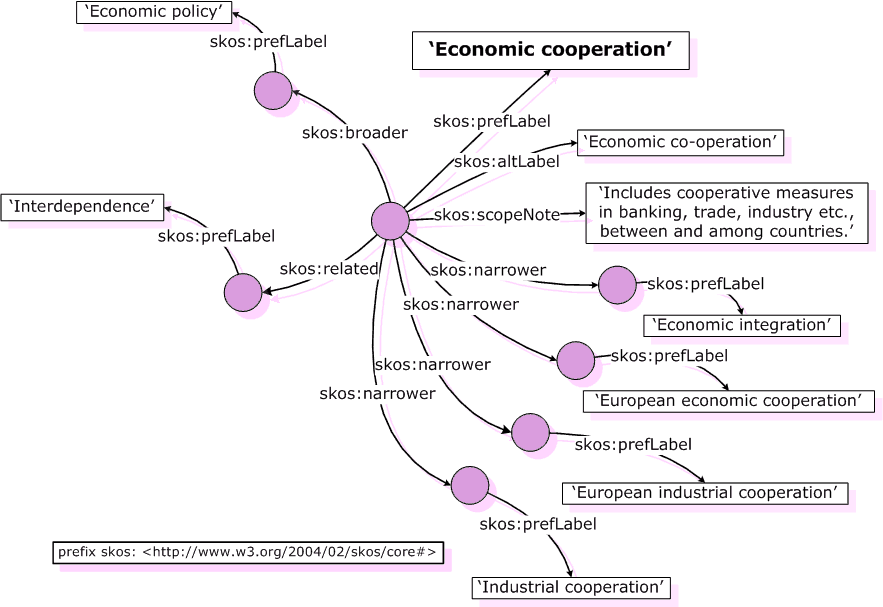
Quelle: https://www.w3.org/TR/2005/WD-swbp-skos-core-guide-20051102/#secintro
Die folgende Abbildung visualisiert SKOS in der nicht nicht mehr gepflegten Modellierungs-Notation semAuth:
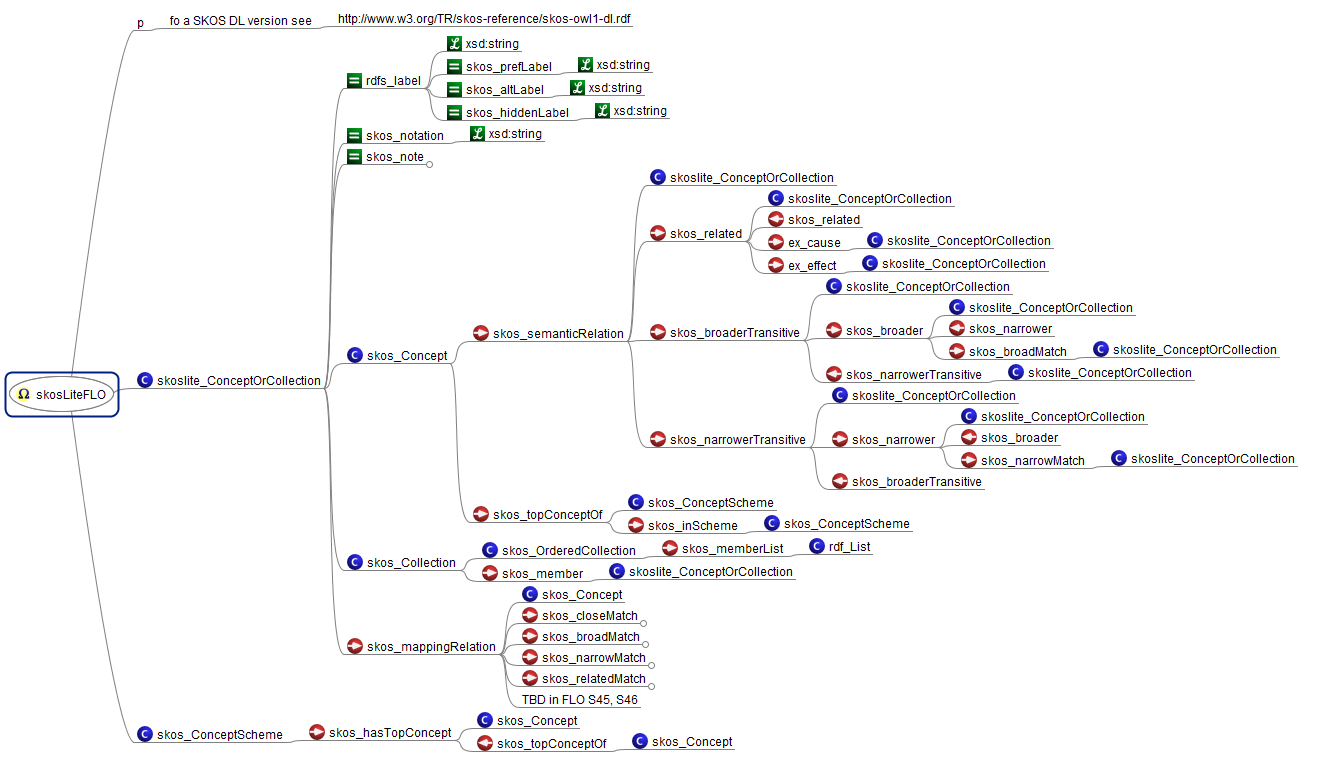
Quelle: SemAuth (Version 0.8), ca 2011, http://www.jbusse.de/semauth/smmm2013_ anwendung_schema-visualisierung.html
TBD#
skos:subjectIndicator; andere skos-Relationen
B 2024-04-26: https://www.jbusse.de/dtt2023/e_skos.html
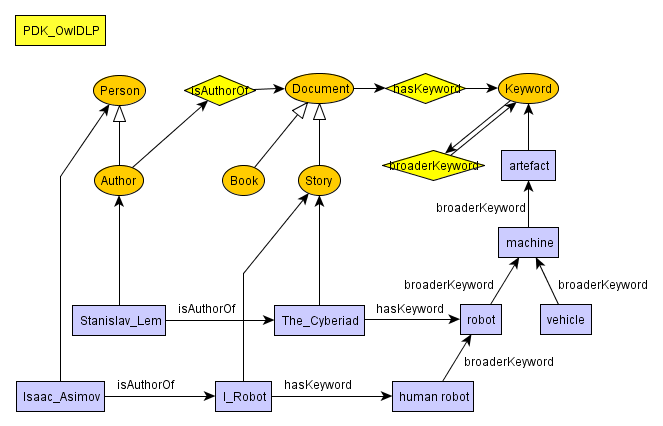
JB 2024-04-26: SKOS Begriffe sind Instanzen, keine Klassen! z.B. Personen, Dokumente, Begriffe (PDK): https://www.jbusse.de/semauth/pdkSandboxOntologies.html#ID_1976288145
2024-04-26: Visualisierung JB des SKOS-Schema: https://www.jbusse.de/semauth/smmm2013_ anwendung_schema-visualisierung.html

Bibliographie:
Grundlagen:
https://dini-ag-kim.github.io/skos-einfuehrung/ (auf github: dini-ag-kim/skos-einfuehrung)
swwo2020, Chapter SKOS—managing vocabularies with RDFS-Plus https://doi.org 10.1145/3382097.3382109
Ontoloex Lemon#
Ontolex
Lizenz: https://www.w3.org/community/about/process/fsa-deed/ : The community is free to: Share – copy and distribute the Specification. Modify the Specification – make new versions of the Specification. If you make new versions of the Specification you must include attribution to the original Specification (but not in any way that suggests that they endorse you or your use of the work).
https://www.jbusse.de/dtt2023/e_ontolex-lemon.html , Figure 1 Lemon_OntoLex_Core.png : Nachbauen?
auch https://en.wikipedia.org/wiki/OntoLex > https://en.wikipedia.org/wiki/OntoLex#/media/File:Lemon_OntoLex_Core(1).png
.png){kind=link}
Integration von SKOS, Wordnet, Ontologie: Ontoloex
Ontolex setzt u.a. Ontologieklassen und skos:Concept in Beziehung, und auch lexikalische Infos …
Gibt es einen Zusammenhang mit Halpin, httprange-14 Problem?
Zusammenhang mit WEMI? Denn in FRBR spielt ja auch skos:Concept eine wichtige Rolle
JB 2024-04-26: Text siehe https://www.jbusse.de/dtt2023/e_ontolex-lemon.html, insbesondere die 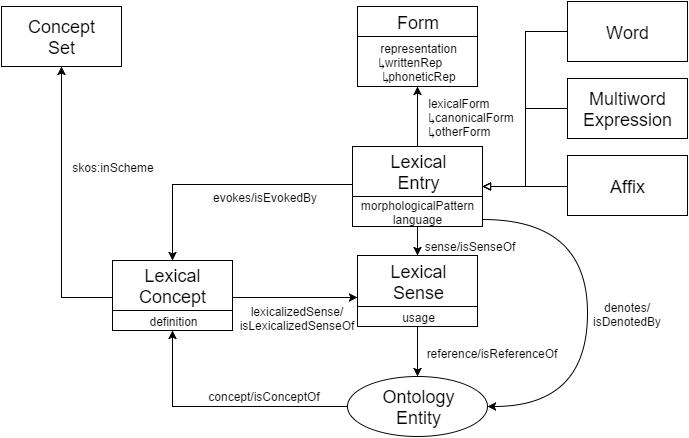
Literatur:
(eine) Original-Publikation (von mehreren): cimiano2020, “Chapter 4: Modelling Lexical Resources as Linked Data” [CCMG20c]
Online:
Anwendung: [Abg20] https://www.researchgate.net/publication/342391981_Using_Ontolex-Lemon_for_Representing_and_Interlinking_Lexicographic_Collections_of_Bavarian_Dialects
mehr ggf. auch https://www.jbusse.de/dtt2023/e_ontolex-lemon.html
Semantik von assoziativen Relationen#
REDAKTION
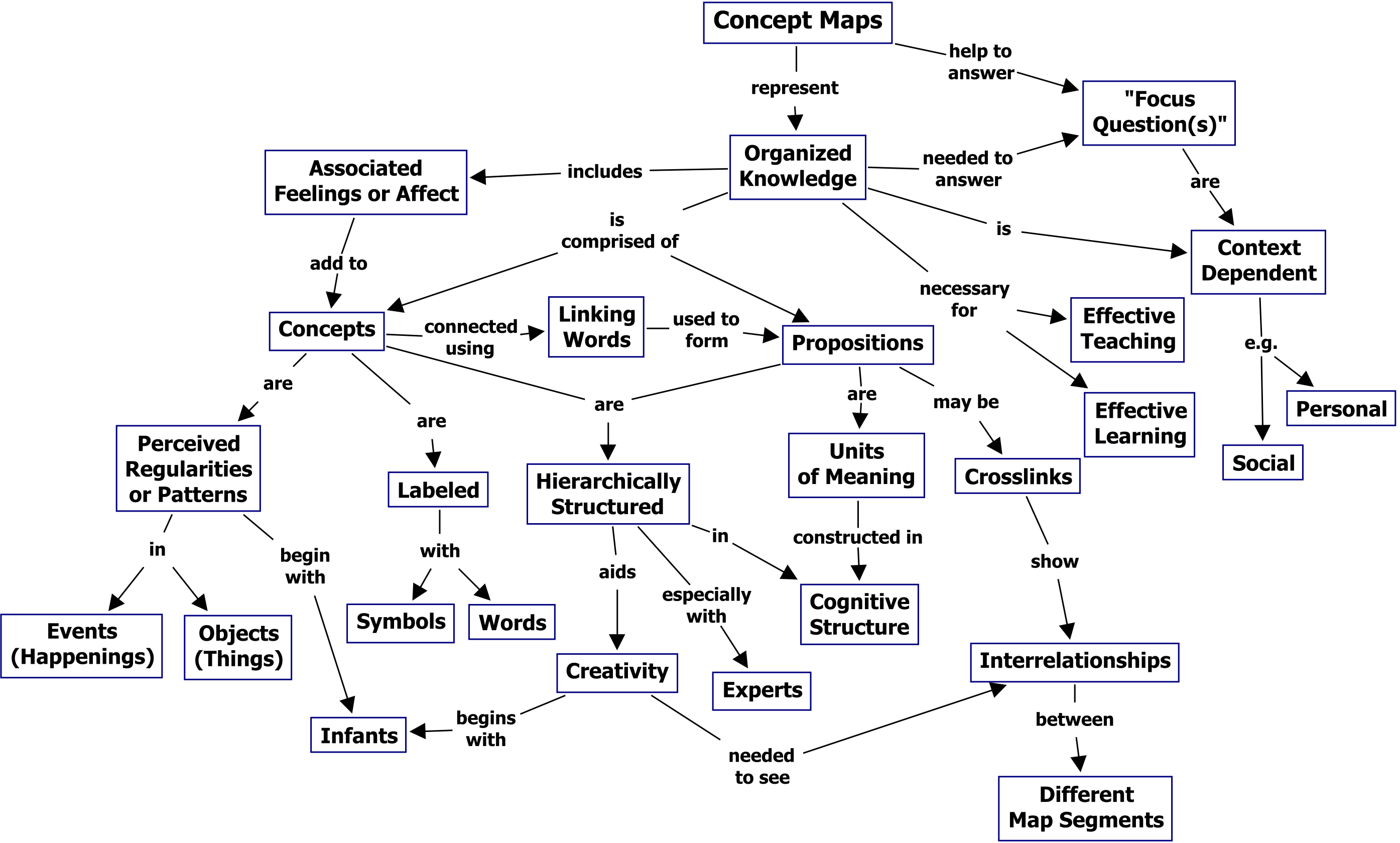
Es gibt eine Tradition, Zusammenhänge als semantisches Netz darzustellen (siehe z.B. https://cmap.ihmc.us/docs/theory-of-concept-maps.php > Abbildung Fig1CmapAboutCmaps) … verschiedene formale Interpretationsmöglichkeiten
{kind=link}
Auch im Umfeld der Semantic Web Ontologien taucht in weit verbreiteten Illustrationen und Erklärungstexten zu “Ontologie” immer wieder ein Modellierungselement auf, das wir in SKOS als assoziative Relation kennengelernt haben. Während die Semantik solcher Relationen intuitiv völlig klar erscheint, ist sie bei näherer Betrachtung weitgehend undefiniert. Insbesondere sind assoziative Relationen nur bedingt geeignet, das Konzept und die Leistungsfähigkeit von Ontologien im Sinne von Tom Gruber (1995) zu illustrieren. Tatsächlich sind assoziative Relationen semantisch so unterbestimmt und damit so vielfältig verwendbar, dass sie sich einer Axiomatisierung geradezu verschließen.
Das muss nicht schlimm sein: Assoziative Relationen sind als genuin semiformale Notationen von hoher Praxisrelevanz. Sie “erzählen eine Geschichte” und nehmen ähnlich wie normalsprachliche Äußerungen einen Platz in den “Brücken” nach dem Theoriebegriff von von W. Stegmüller ein (siehe Kapitel XXX).
Vertikale Relationen#
Als vertikale Relationen wollen wir die Relationen bezeichnen, die “ungefähr” einen Baum aufspannen und dafür verantwortlich sind, dass es ein “Oben” oder “Unten” gibt.
In einer Klassifikation ist es die Teilmengenrelation
isa, die einen Baum aufspannt;In SKOS ist es die Relation
skos:broaderTransitive(oder auch nurskos:broader);in einem Thesaurus ist es die Relation
broader term(BT);in einer Meronymie ist es die Relation
partOf.
Baumrelationen spannen nur “ungefähr” einen Baum auf, da wir auch Mehrfachvererbung zulassen. Je mehr Mehrfachvererbungen wir haben, desto mehr verändert sich der Baum zu einem Netzwerk. (Anders als in der Mathematik ist der Unterschied zwischen Baum und Netzwerk also graduell.)
Unabhängig davon, ob wir es mit einem reinen Baum, einem “angenäherten” Baum oder einem mehrfach verknüpften Netzwerk zu tun haben, sind diese Eigenschaften für eine solche Struktur entscheidend:
Wir verlangen, dass der Graph gerichtet und azyklisch ist (directed acyclic graph, DAG), d.h. dass er sich nach oben und unten ausrichtet.
Der Baumtyp wird durch eine einzige “primäre” Baumrelation definiert. Verschiedene Baumrelationen werden nicht nebeneinander im selben Baum verwendet.
Alle Knoten im Baum sind durch die primäre Baumrelation verbunden.
Im Allgemeinen werden Baumrelationen als transitive Relationen betrachtet; aber Diskussion erforderlich:
Manchmal wird nur
skos:broadernotiert, wo eigentlichskos:broaderTransitivegemeint ist.Ist
partOftransitiv?
Vertikale Relationen werden in SKOS hierarchical genannt.
Assoziative (“horizontale”) Relationen#
Als horizontale Relationen wollen wir solche Relationen bezeichnen, die praktisch beliebige Querbeziehungen zwischen einzelnen Knoten in einem Baum (oder Näherungsbaum oder gerichteten Graphen) aufspannen.
Bäume, die horizontale Relationen enthalten, haben die folgenden Eigenschaften:
Es gibt keine Einschränkungen bezüglich der Zyklen.
Es können beliebig viele verschiedene horizontale Relationen verwendet werden.
Nicht alle Knoten sind durch dieselbe horizontale Relation verbunden. Im Gegenteil, Knoten können sogar danach unterschieden werden, über welche spezifischen horizontalen Relationen sie miteinander verbunden sind.
Im Allgemeinen werden horizontale Relationen nicht als transitiv betrachtet.
In SKOS ist die Relation skos:related eine solche horizontale Relation und wird dort semantic relation oder auch associative link genannt (https://www.w3.org/TR/skos-reference/#semantic-relations).
ABBILDUNG: https://www.w3.org/2004/02/skos/core/guide/2005-10-06/img/ex-rel-rel.png Quelle: https://www.w3.org/2004/02/skos/core/guide/2005-10-06/
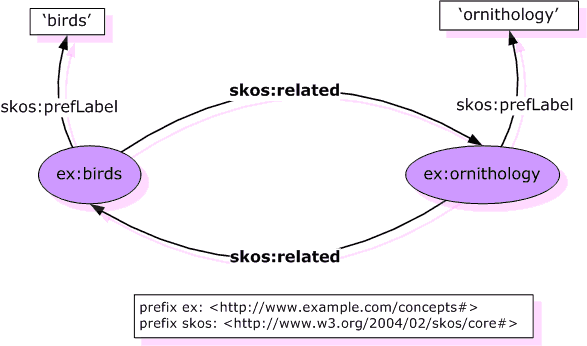{kind=link}
ex:bird skos:related ex:ornithology .
ex:ornithology skos:related ex:bird .
Zur Vollständigkeit: Von skos:related lassen sich in RDFS dann auch Sub-Properties bilden:
ex:knows rdfs:subPropertyOf skos:related .
ex:loves rdfs:subPropertyOf ex:knows .
SKOS#
Wir haben schon öfters SKOS zitiert, und auch GenDifS exportiert nach SKOS. Wir tun dies, obwohl und weil SKOS ein völlig anderes Konzept der Wissensrepräsentation verfolgt als OWL.
SKOS wurde in seiner ursprünglichen Form als eine (sehr schlanke, schöne) Ontologie in OWL Full (!) veröffentlicht, aber es gibt auch eine praktische Version in OWL DL. SKOS ist also ein Schema, das sogar als Ontologie formalisiert wurde. Eine in SKOS formulierte Terminologie (also eine Menge von Instanzen) ist dagegen selbst keine Ontologie. Die SKOS-Referenz https://www.w3.org/TR/skos-reference/#L1045 weist explizit auf diesen Unterschied hin:
SKOS can, in more advanced applications, also be used side-by-side with OWL to express and exchange knowledge about a domain. […] However, SKOS is not a formal knowledge representation language. To understand this distinction, consider that the “knowledge” made explicit in a formal ontology is expressed as sets of axioms and facts. A thesaurus or classification scheme is of a completely different nature, and does not assert any axioms or facts. Rather, a thesaurus or classification scheme identifies and describes, through natural language and other informal means, a set of distinct ideas or meanings, which are sometimes conveniently referred to as “concepts”. These “concepts” may also be arranged and organized into various structures, most commonly hierarchies and association networks. These structures, however, do not have any formal semantics, and cannot be reliably interpreted as either formal axioms or facts about the world. […]
To make the “knowledge” embedded in a thesaurus or classification scheme explicit in any formal sense requires that the thesaurus or classification scheme be re-engineered as a formal ontology. […] Converting such KOS to a formal logic-based representation may, in practice, involve changes which result in a representation that no longer meets the originally intended purpose.
Taking this approach, the “concepts” of a thesaurus or classification scheme are modeled as individuals in the SKOS data model, and the informal descriptions about and links between those “concepts” as given by the thesaurus or classification scheme are modeled as facts about those individuals, never as class or property axioms. […] these are not facts about the way the world is arranged within a particular subject domain, as might be expressed in a formal ontology.
Semantische Netze#
Assoziative Relationen sind ein wichtiges Element in semantischen Netzen. Die Software CMap beschreibt die Funktion und Bedeutung von sog. “Concept Maps” selbstbezüglich als ein Semantisches Netz:

Quelle: https://cmap.ihmc.us/docs/theory-of-concept-maps.php
Dieses Beispiel quillt über von assoziativen Beziehungen, während vertikale Beziehungen fast völlig fehlen. In SKOS können wir fast alle diese assoziativen Beziehungen als Sub-Properties von skos:related anlegen. Aber wie sieht das in OWL aus? Gibt es eine “OWL-Semantik” von assoziativen Relationen in einem semantischen Netz?
Wir nähern uns diesem Problem anhand einer intuitiven Abbildung aus Wikipedia > Semantic network:
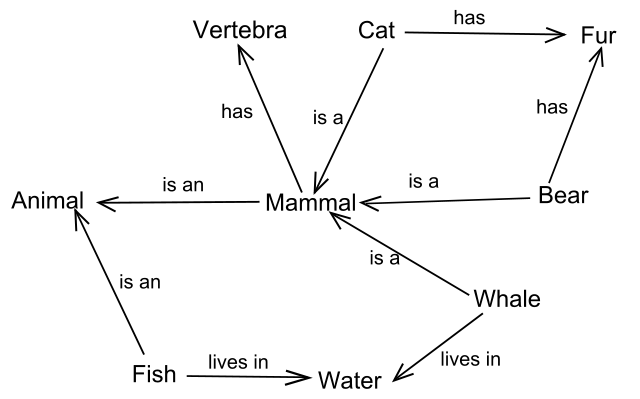
(Der aufmerksamen Leserin wird auffallen, dass in der englischen Version sowohl is an als auch is a vorkommt. Wir interpretieren diese beiden Relationen hier als Synonyme mit der Begründung, dass wir solche Netze nicht direkt als formales System, sondern zunächst als Visualisierung oder Semiformalisierung von normalsprachlichen Sätzen verstehen wollen).
Die Umsetzung nach SKOS ist einfach und straight forward:
Cat,Fur,Mammal,Vertebrawird als Instanz vonskos:Conceptangelegthaswird angelegt als Subproperty vonskos:relatedis_awird interpretiert alsskos:broaderTransitive
Als Ergebnis entsteht - als A-Box der Ontologie SKOS - ein SKOS-Thesaurus. Um so mehr stellt sich die Frage: Welche Semantik könnten wir in OWL vermuten? Dazu müssen wir eine Lösung sowohl für die “vertikalen” Relationen (hier: isa) wie auch die verschiedenen assoziativen Relationen finden.
isa#
Gehen wir in o.A. semantischem Netz von der Ausage Bear has Fur aus. Dann müssen wir entscheiden:
Instanz: Reden wir über einen bestimmten Bär, oder einen prototypischen Bären, den “Bären an sich”?
Klasse: Oder reden wir über die Menge der Bären?
Instanz: isa als element_of#
Wenn wir der Instanzinterpretation folgen, formalisieren wir is_a als is element of. Dann ist Bär ein (bestimmtes oder prototypisches) Element der Menge Säugetier, und über diesen Bären sagen wir nun, dass er ein (ebenfalls bestimmtes oder prototypisches) Fell hat.
Etwas unklar ist, was in dieser Instanzinterpretation dann über Säugetier ausgesagt wird. Mammal wäre dann ein Element, aber keine Unterklasse der Menge “Tier”. Über dieses eine prototypische Exemplar Säugetier, sozusagen das Säugetier an sich, könnte man dann problemlos sagen: Dieses (bestimmte oder prototypische) Tier Säugetier hat einen (bestimmten oder prototypischen) Wirbelsäulenknochen.
Aber auch diese Instanzinterpretation ist problematisch. Denn leider haben wir auch die Aussage, dass Katze ein Element von Säugetier ist. Damit wird Mammal automatisch zu einer Menge und kann kein (spezifisches oder prototypisches) Säugetier mehr sein. Ein solches Problem entsteht typischerweise immer dann, wenn man eine solche Interpretation von is a als is element of “schichtet”. In OWL entsteht dann ein sogenanntes OWL-Full-Modell. Dieses wollen wir aber vermeiden, zumindest dann, wenn wir mit formallogischer Inferenz arbeiten wollen, andererseits aber unentscheidbare Logiksysteme erzeugen (Why is OWL Full undecidable?).
Instanzinterpretation scheidet daher aus.
Klasse: is_a als is_subclass_of#
Tatsächlich legt die Abbildung nahe, dass wir nicht über einen bestimmten oder prototypischen Bären mit einem bestimmten oder prototypischen Fell sprechen, sondern allgemein über Bären und Felle und Säugetiere und Wirbeltiere. Bär und Fell sind also Klassen, und is_a wird als is subclass of interpretiert.
Aber dann wird die Semantik von has unklar. Denn wenn das Subjekt in der Aussage Bär hat Fell eine Menge ist: Will man dann sagen, dass diese Menge ein Fell hat? Das ist natürlich Unsinn. Wahrscheinlich ist etwas ganz anderes gemeint:
Alle Katzen haben ein Fell!
Unter Berücksichtigung der Unterscheidung zwischen Klasse und Instanz ist wahrscheinlich gemeint:
Wenn
cein Element der MengeKatzeist,dann muss es ein Element
fder MengeFellgeben,so dass wahr ist:
c hat f.
Damit ist aber nur die Semantik von c hat f thematisiert, mit c und f als Instanzen der Mengen Cat und Fur. Wie aber formalisiert man diese Relation Katze hat Fell korrekt in OWL?
Eine mögliche Lösung ist ausführlich diskutiert und bestens beschrieben an dem strukturäquivalenten Beispiel Healthy_Person has_health_status Good_Health_Value, siehe https://www.w3.org/TR/swbp-specified-values/#pattern2.
Es ist leicht zu erkennen: Während ein Semantisches Netz in SKOS einfach modelliert werden kann, ist eine mögliche adäquate OWL-Modellierung recht anspruchsvoll. (Eine weitere mögliche Interpretation speziell für die Relation hat findet sich in Simple part-whole relations in OWL Ontologies. W3C Editor’s Draft 24 Mar 2005). Im Folgenden wollen wir has oder lives in nur als beliebige assoziative (“horizontale”, nicht-vertikale) Relation betrachten.
rdfs:range oder rdfs:domain?#
RDFS definiert Sprachkostrukte, mit denen man aus existierendem Wissen neues Wissen ableiten kann, sogenannte Entailment-Regeln. Wichtige Entailment-Reglen gibt es insbesondere für rdfs:range und rdfs:domain.
Aus https://www.w3.org/TR/rdf-schema/#ch_domain:
The triple
P rdfs:range Cstates that P is an instance of the classrdf:Property, thatCis an instance of the classrdfs:Classand that the resources denoted by the objects of triples whose predicate isPare instances of the classC.
Aus https://www.w3.org/TR/rdf11-mt/#patterns-of-rdfs-entailment-informative > RDFS entailment patterns (Formatierung und Variablen-Umbenennung JB):
rdfs2:
If S contains
P rdfs:domain X . yyy P zzz .then S RDFS entails recognizing D:
yyy rdf:type X .
rdfs3:
If S contains
P rdfs:range X . yyy P zzz .then S RDFS entails recognizing D:
zzz rdf:type X .
Es ist wichtig zu sehen, dass man mit rdfs:range und rdfs:domain ableiten kann, dass ein bestimmtes Beispielelement einen bestimmten Typ hat - aber man kann nicht kontrollieren, ob ein bestimmtes Beispielelement einen bestimmten Typ hat. Die Konstrukte rdfs:range und rdfs:domain sind Entailment-Regeln, aber keine Constraint-Regeln. Menschen, die den Begriff “Schema” im Datenbank- oder XML-Kontext kennen gelernt haben, mag diese Semantik unintuitiv erscheinen.
Die obigen Entailment-Regeln haben eine unintuitive Folge, auf die in der RDF-Spezifikation explizit hingewiesen wird:
Where
Phas more than onerdfs:rangeproperty, then the resources denoted by the objects of triples with predicatePare instances of all [Herv. JB] the classes stated by therdfs:rangeproperties. https://www.w3.org/TR/rdf-schema/#ch_range
Seien in einem Semantischen Netz die Kanten Bear lives_in Forest und Whale lives_in Water gegeben. Dann wäre es ein schwerer Fehler, diese Semantische-Netzwerk-Tripel in RDFS oder OWL etwa wie folgt zu interpretieren:
In einem semantischen Netz seien die Kanten Bear lives_in Forest und Whale lives_in Water gegeben. In diesem Fall wäre es ein schwerwiegender Fehler, dieses Semantische Netz-Tripel in RDFS oder OWL wie folgt zu interpretieren:
:lives_in rdfs:domain :Bear . #1
:lives_in rdfs:range :Forest . #2
:lives_in rdfs:domain :Whale . #3
:lives_in rdfs:range :Water . #4
:theGreatNorthernForest rdf:type :Forest . #5
:Benny_1234 :lives_in :theGreatNorthernForest . #6
Denn dann lässt sich gemäß den RDF Entailment Regeln für :Benny_1234 aus #6 und #1 ableiten, dass :Benny_1234 ein :Bear ist, sowie gemäß #6 und #3, dass :Benny_1234 ein :Whale ist. Und auch Zeile #5 ist redundant, denn diese Typ-Information ergibt sich ja aus #2 - ebenso wie die Information, dass :theGreatNorthernForest gemäß #4 auch vom Typ :Water ist ;-)
Wenn also in einem semantischen Netz eine Kante wie z.B. “Bären leben_in Wald” ausdrücken soll, dass Tiere vom Typ “Bär” immer (notwendig / typischerweise / per default?) an einem Ort vom Typ “Wald” leben: Dann lässt sich das in RDFS oder OWL nicht einfach und geradlinig durch rdfs:range oder rdfs:domain modellieren.
In GenDifS haben wir derzeit keine praxistaugliche Lösung, um REL nach OWL zu übersetzen. Daher ist REL bisher ausschließlich auf SKOS-Ebene implementiert, und zwar straight forward wie oben dargestellt.
frbroo: realises#
Wir haben Relationen mit dem gleichen Namen, aber verschiedenen systematischen bezeichnern, mit unterschidlichem Domain und Range:
R3 is realised in (realises) Domain: F1 Work Range: F22 Self-contained Expression Scope note: This property associates an instance of F22 Self-Contained Expression with an instance of F1 Work. […] This property expresses the association that exists between an expression (F22) and the work that this expression conveys. The semantics of the association will be different depending on what specific subtype of F1 Work the work is an instance of. (frbroo_v_2.4.pdf, p.87)
R9 is realised in (realises) Domain: F14 Individual Work Range: F22 Self-Contained Expression Subproperty of: F1 Work. R3 is realised in (realises): F22 Self-Contained Expression Scope note: This property associates an F14 Individual Work with the unique F22 Self-Contained Expression that completely conveys it.
R12 is realised in (realises) Domain: F20 Performance Work Range: F25 Performance Plan Subproperty of: F1 Work. R3 is realised in (realises): F22 Self-Contained Expression Scope note: This property associates an instance of F20 Performance Work with an instance of F25 Performance Plan that consists of signs (words, figures, etc.) which express the directions the instance of F20 Performance Work consists of.
R13 is realised in (realises) Domain: F21 Recording Work Range: F26 Recording Subproperty of: F1 Work. R3 is realised in (realises): F22 Self-Contained Expression Scope note: This property associates an instance of F21 Recording Work with an instance of F26 Recording realising the instance of F21 Recording Work.
Das kommt öfters vor. Aus Tabelle 2.5.3. FRBR OO Property Hierarchy (p.45 ff):
is realised in (realises): R3, R9, R12, R31, R40
created (was created by): R17, R18; created (was created through): R21,R24; created a realisation of (was realised through): R19, R22, R23
produced (was produced by): R28, R30
assigned (was assigned by): R45, R46, R49, R51, R53; assigned to (was assigned by): R48, R50,
In OO und einer Frame-basierten Logik - insbesondere F-Logic oder Object Logic - ist dies eine ganz normale Modellierung. In einer Locic-Beschreibung wären Domain und Range hier eine falsche Modellierung. Denn die Begriffe “Domain” und “Range” haben in der Objektorientierung eine ganz andere Semantik als “Domain” und “Range” in RDFS und OWL.
In einer Frame-Darstellung gibt es “Frames”, die “Slots” haben. Zum Beispiel kann der Frame “Vortrag” einen Slot “Länge” haben, und der Frame “Segelboot” kann einen Slot Länge haben. Um die Aussage “Länge: 27” zu interpretieren, müssen wir wissen, welche Länge gemeint ist. Bei mehrdeutigen Slotnamen kann man nicht ableiten, welcher Frame (hier: Vortrag? Segelboot?) gemeint ist, sondern man muss wissen, in welchem Frame er definiert ist. Der Begriff Domain kann in Frame-basierten Wissensrepräsentationen als der Frame verstanden werden, der den jeweiligen Slot definiert.
In RDFS sind Relationen first class objects, die insbesondere auch ohne zugehörige Klasse existieren. Es ist möglich, dass verschiedene Namen die gleiche Relation bezeichnen, aber es ist nicht möglich, dass der gleiche Name verschiedene Relationen bezeichnet. Mit dem RDFS-Axiom rdfs:domain (bzw. rdfs:range) kann angegeben werden, welcher Typ für eine Instanz abgeleitet werden kann, die als Subjekt (bzw. Objekt) in einer Relation auftritt.