Facetten-Klassifikation im OLAP-Würfel
Contents
Facetten-Klassifikation im OLAP-Würfel#
Die Genus Proximus Differentia Spezfica Classification Language (GPDSCL) ist eine Sprache, mit der man in Mindmaps als Facetten-Klassifikation (Wikipedia) modellieren kann.
Um eine Sache zu erklären und eine Fachbegrifflichkeit aufzubauen ist es didaktisch sehr hilfreich, an bekannte und anschauliche Konzepte anknüpfen zu können. Weil sich unser Einsatz der GPDSCL im Bereich der Wirtschaftsinformatik bewegt, unternehmen wir in diesem Text hier den Versuch, die Sprachelemente der GPDSCL auf Konzepte des Online Analytical Processing (OLAP) zu beziehen.
Auf Sachebene stammen unsere Beispiele aus Gegenstandsbereichen, die (a) überfachlich und alltagsnah unmittelbar verständlich sind, und die (b) auch schon modellierungstechnisch an anderer Stelle zur Verwendung kommen. (Kuhmilch: SKOS-Tutorial, Gewässer: Wikipedia FCA-Website).
Was ist ein OLAP-Würfel?#
Die Seite https://de.wikipedia.org/wiki/OLAP-W%C3%BCrfel liefert eine für unsere Zwecke ausreichende Einführung in OLAP-Würfel, die Seite https://en.wikipedia.org/wiki/OLAP_cube#Mathematical_definition eine mathematische Definition:
“””In database theory, an OLAP cube is[9] an abstract representation of a projection of an RDBMS relation. Given a relation of order N, consider a projection that subtends X, Y, and Z as the key and W as the residual attribute. Characterizing this as a function, f : (X,Y,Z) → W, the attributes X, Y, and Z correspond to the axes of the cube, while the W value corresponds to the data element that populates each cell of the cube. “””
Anschauliche Erklärung für Studierende im 1. Semester, “Grundlagen der Wirtschaftsinformatik”:
Gegeben sei eine Excel-Tabelle:
Spalte 0 (Null): eine eindeutige ID, z.B. eine URI
Spalten 1 bis n: charakteristische Eigenschaften, die man zu Klassifizierung, Sortierung, Suche etc. verwenden will … zugleich die Achsen unseres OLAP-Würfels
Spalten n+1 .. m: die eigentlichen Datenfelder
In unseren Beispielen sei n vorwiegend aus {1, 2, 3}, sowie m > n.
Gewässer als OLAP-Würfel#
Beispiel im Folgenden: CSV-Tabelle Gewässer
Spalte 0: eindeutiger Name, hier gegeben durch eine URL
Spalte 1: Binnengewässer oder Meer
Spalte 2, fließend / stehend
Spalte 3 .. m: weitere Daten über das Gewässer, wie z.B.
Ursache: natürlich oder künstlich
Persistenz: temporär, dauerhaft, episodisch etc.
Entwässerung: letzlich ins Meer, Verdunstung, Versickerung
Länge (bei Flüssen), Fläche (bei Seen, Meeren) etc.: reine Datenfelder
Zuflüsse, ggf. Entwässerung wohin: Referenzen auf andere Gewässer aus der selben Tabelle
Die Zeilen dieser Tabelle stellen unsere Datensätze dar. Beispiel:

Wir können die ersten beiden Spalten unseres Beispiels als die Achsen eines zweidimensionalen Koordinatensystems betrachten, und an den entsprechenden Kreuzungspunkten eintragen, wie viele Datensätze die jeweilige Kombination von Attribut-Ausprägungen aufweisen:
X-Achse = Binnengewässer oder Meer, binär codiert durch 1 oder 0
Y-Achse = Bewegtheit, mit den Kategorien “fließend” oder “stehend”
In Tools wie LibreOfiice Calc oder MS Excel nennt man solch einen Transfer von zwei ausgewählien Spalten in eine neue 2D-Gegenüberstellung eine Pivot-Tabelle:

Falls wir später eine zusätzliche charakteristische Eigenschaft - etwa “künstlich angelegt” - hinzunehmen, erweitert sich das 2D-Raster zu einem 3D-Modell, also einem Würfel - dem typischen OLAP-Würfel. https://de.wikipedia.org/wiki/OLAP-W%C3%BCrfel. In der Business Intelligence wird solch ein OLAP-Würfel didaktisch oft mit Facetten wie Produkt, Quartal und Vertriebsgebiet illustriert, so auch hier:
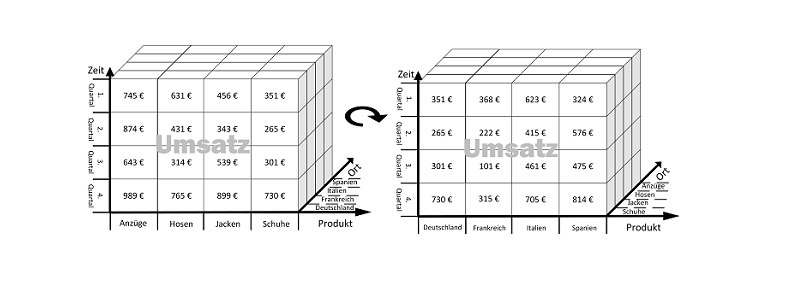
(Quelle: https://data-science-blog.com/blog/2019/02/16/olap-wuerfel/)
Kommen weitere charakteristische Eigenschaften - etwa temporär oder dauerhaft, unterirdisch oder überirdisch, Süßwasser oder Brackwasser oder Salzwasser etc. - hinzu, ensteht ein n-dimensionaler Würfel, der sich naturgemäß nur noch schwer visualisieren lässt. (Tatsächlich können die einzelnen Objekte in den einzelnen Kreuzungspunkten unabhängig voneinander durch Form, Farbe und Größe unterschieden werden, wodurch zusätzliche 3 Facetten eines Datensatzes bedingt dargestellt werden können.)
Wie viele Dimensionen?#
Nocheinmal die Terminolgie:
Die Spalten unserer Gewässer-Tabelle nennen wir allgemein Attribute.
Diejenigen n Attribute, die wir für die Konstruktion unseres Koordinatensystems oder Würfels heranziehen, nennen wir auch Facetten; die Facetten bilden einen n-dimensionalen OLAP-Würfel.
Die Zeilen in der Tabelle stellen die Datensätze dar.
Den Wert eines Attributs für einen bestimmten Datensatz nennen wir eine Ausprägung des Attributs.
Falls das Attribut eine Facette ist nennen wir seine Ausprägungen auch einen Focus.
Einen Datensatz, für den alle verfügbaren Facetten eine Ausprägung angegeben ist, können wir einem “Krezungspunkt” im Datenwürfel zuordnen.
Wir betrachten unsere Gewässer-Tabelle genauer.
Für das Attribut maritim bietet sich eine Codierung durch 1 (Meer) oder 0 (Binnengewässer) an. Entsprechend hat die Facette maritim 2 Werte. Wir wollen diese Facette eine binäre Facette nennen.
Nehmen wir an, dass wir für das Attribut Entwässerung die Ausprägungen “Entwässerung letztlich ins Meer”, “Entwässerung durch Verdunstung”, “Entwässerung durch Versickerung” haben. Entsprechend hat die Facette Entwässerung drei Werte. Diese Werte sind kategorial und nicht geordnet (eine numerische Codierung durch Zahlen (z.B. 0, 1, 2) wäre unglücklich, da in einer solchen eine Ordnungsrelation suggeriert wird, die ja so nicht vorliegt). Wir wollen solch eine Facette eine kategoriale Facette nennen.
Sollte unbedingt eine 0/1-Codierung für die einzelnen Ausprägungen (Foci) der Facette “Entwässerung” erforderlich werden - bestimmte Machine Learning Verfahren oder auch eine Formale Begriffsanalyse (FCA) erfordern dies - dann ist das Mittel der Wahl eine sogenannte 1-aus-n- (EN: one-hot-) Codierung (Wikipedia): Jede einzelne Ausprägung des Attributs Entwässerung wird als neue Spalte angelegt, die dann binäre Ausprägungen annehmen kann. Wir wollen solch eine Facette eine one hot Facette nennen.
(Für Fortgeschrittene: Bei einer One-Hot-Codierung für ein Attribut mit k verschiedenen Ausprägungen - beim Attribut “Entwässerung” haben wir k=3) - kann es sinnvoll sein, lediglich k-1 neue Attribute anzulegen (Diskussion HIER, TBD). Ganz intuitiv haben wir das im Attribut “maritim” gemacht, denn “Meer” oder “Binnengewässer” wird hier in einer einzigen Spalte mit den Werten 0/1 codiert.)
Nach dem Anwenden einer 1-aus-n-Codierung haben wir ein Modell mit den folgenden 4 Facetten, die alle 0 ode 1 als Ausprägung besitzen:
binäre Facette maritim
one hot Facette Entwässerung letztlich ins Meer
one hot Facette Entwässerung durch Verdunstung
one hot Facette Entwässerung durch Versickerung
Bei einer Umwandlung einer kategorialen Facette durch eine 1-aus-n-Codierung in k verschiedene one hot Facetten geht Information verloren, nämlich
der Name der ursprünglichen kategorialen Facette,
die Zuordnung den Ausprägungen der neuen one hot Facetten zur ursprünglichen kategorialen Facette,
die Information, welche one-hot Facetten sich wechselseitig ausschließen.
Zusammenfassung, was bisher geschah:
Excel-Tabelle
Spalte 0 ist die Datensatz-ID. Insbesondere eignet sich hierzu eine IRI ode URL, wie z.B. https://de.wikipedia.org/wiki/Donau .
Wir wählen nach Belieben einige Spalten aus, die wie als Achsen eines n-dimensionalen Würfels interpretieren: Diese Spalten nennen wir Facetten.
kategoriale Facetten mit k verschiedenen Ausprägungen können wir einer one-hot-Codierung zuführen, um so k (oder auch k-1) neue one hot Facetten zu generieren: Jede einzelne mögliche Ausprägung einer kategorialen Facetten Facette wird zu einer neuen Spalte, deren Ausprägungen dann wieder 0 oder 1 sind.
Vom Beispiel zur Klasse#
Wichtig zu sehen:
Implizit gehen wir in unserem Beispiel davon aus, dass die IDs (hier: die URLs) unserer Datensätze Individuen bezeichnen: Donau, Steinhuder Meer, Panamakanal.
Die Ausprägungen der Facetten beschreiben eine Eigenschaft des durch die ID bezeichneten spezifischen Individuums: Die Donau fließt und ist ein Binnengewässer, das Steinhuder Meer ist ein stehendes Binnengewässer etc.
Die Datensätze https://de.wikipedia.org/wiki/Steinhuder_Meer und https://de.wikipedia.org/wiki/Bodensee unterscheiden sich in Ihrer ID, ihrer Fläche, Tiefe etc - aber in den Ausprägungen derjenigen Attribute, die wir als Facetten ausgewählt haben, unterscheiden sich sich nicht. Insbesondere das Attribut “Typ” lautet für beide Datensätze “See”.
Hier verwenden wir eine fundamentale Idee der Mathematik:
Das Steinhuder Meer und der Bodensee sind Elemente einer Menge, nämlich der Menge der Seen
Auch alle anderen Individuen, die Elemente dieser Menge sind, haben bestimmte Ausprägungen von Facetten gemeinsam: So sind z.B. Seen u.A. durch die Ausprägungen “Binnengewässer” und “stehend” (sowie einige andere Eigenschaften) definiert.
Eine Herausforderung besteht also darin zu analysieren, welche Ausprägungen welcher Facetten typisch sind für den jeweiligen “Typ”.
Das können wir empirisch anhand der vorgegebenen Beispiele machen: Wir geben in unserem Beispiel für jeden “Typ” genau ein (Ausnahme Seen: mehr als ein) Beispiel an. Tatsächsächlich haben wir exakt das Beispiel aus der Seite https://de.wikipedia.org/wiki/Formale_Begriffsanalyse verwendet. Die Formale Begriffsanalyse (Formal Concept Analysis, FCA) errechnet uns auf Basis einer Mange von - idealerweise typischen - Beispielen ein Netzwerk aus Teilmengen-Beziehungen, siehe https://de.wikipedia.org/wiki/Formale_Begriffsanalyse#Beispiel.
Wir können es aber auch “analytisch” machen: Wir können versuchen, die Vielzahl von Attribut-Ausprägungen anhand unseres Weltwissens, unseres Sprachverständnisses, unserer Erfahrung mit Gewässern manuell überschaubarer zu machen.
Schritt 1: Gruppierung von Eigenschaften zu Facetten#
“Überschaubarer machen” kann man eine große Menge von Ausprägungen in einem ersten Schritt insbesondere dadurch, dass man sie in zusammenhängende Teilmengen untergliedert, z.B. so:
ungeordnete Menge: { temporär, fließend, natürlich, stehend, konstant, maritim }
in Teilmengen untergliederte Menge: { { stehend, fließend} , { konstant, temporär}, { maritim , nicht maritim}, { natürlich, nicht natürlich } }
Benennung der Teilmengen: Bewegtheit = { stehend, fließend} u.s.w.
Als Ergebnis entsteht aus einer großen, schwer überschaubaren Menge von Attribut-Ausprägungen eine Menge von Mengen von besser überschaubaren Ausprägungen von Facetten.
Anhand welches Kriteriums hat diese Gruppierung und Benennung stattgefunden? Man sieht leicht: { stehend, fließend} , { konstant, temporär} etc. sind Eigenschaften,
die sich innerhalb ihrer Teilmenge wechselseitig ausschließen,
mit anderen Eigenschaften ansonsten aber - im Prinzip - frei kombinieren lassen.
Haben wir solche Teilmengen von sich wechselseitig ausschließenden Eigenschaften gefunden, können wir diese verwenden, um sie zu benennen und als Facetten zu interpretieren. Aus einer “flachen” Menge von Eigenschaften enstehen so die Dimensionen unseres OLAP-Würfels oder die Facetten einer Facetten-Klassifikation.
Der EN und der DE Artikel aus Wikipedia zu Gewässer zeigen beide Stufen nebeneinander:
Der Artikel https://en.wikipedia.org/wiki/Body_of_water führt nebeneinander ca. 90 Typen von Gewässern in Form eines Glossars nebeneinander auf, wie z.B.:
River – a natural waterway usually formed by water derived from either precipitation or glacial meltwater, and flows from higher ground to lower ground.
Wadi – a usually-dry creek bed or gulch that temporarily fills with water after a heavy rain, or seasonally; located in North Africa and Western Asia. See also Arroyo (creek).
Lake – a body of water, usually freshwater, of relatively large size contained on a body of land.
Ocean – a major body of salty water that, in totality, covers about 71% of the Earth’s surface.
Offensichtliche Aufgabe:
Schreiben aus dieser Liste von 90 Begriffen alle Eigenschaften heraus.
Gruppiere sie.
Idenifiziere solche Attribute, die wir als Facetten / für einen OLAP-Cube verwenden wollen.
Dabei beachten: Nicht jede Information in einer Definition ist eine Facette:
Wenn etwa ein Wadi wird als ein “normalerweise trockenes creek bed” beschrieben wird, ist crek bed keine Eigenschaft, sondern ein Oberbegriff, der hier spezialisiert wird.
Auch die bei Ozeanen genannte Abdeckungsquote von 71% ist natürlich keine definierende Eigenschaft von Ozeanen
Der DE Artikel verfolgt eine deutlich höhere Strukturierung: https://de.wikipedia.org/wiki/Gew%C3%A4sser.
Letztlich suchen wir in Schritt 1 nach Methoden und unterstützenden Tools, um aus der Darstellung body of water (EN) Vorformen der Darstellung Gewässer (DE) zu generieren.
Schritt 2: Definition von Klassen durch Genus Proximum und Differentia Specifica#
In der Geschichte der Logik gibt es ein grundlegendes Pattern der Klassifikationslehre: Man unterscheidet Dinge, indem man
zuerst ihre Gemeinsamkeit feststellt, indem man sie einer gemeinsamen (Ober-) Klasse, dem sog. Genus Proximum (GP), zuordnet, und
sie dann anhand von spezifischen Unterschieden - der sog. differentia spezifika - in Unterklassen einteilt.
Diese Einteilung in Unterklassen kann anhand verschiedener Gruppen von spezifischen Unterschieden geschehen.
Beispiel 1, Kuhmilch:
Kuhmilch, Schafsmilch, Tetrapackmilch, Vollmilch, fettarme Milch: Diese Milche lassen sich unterscheiden z.B. (a) duch ihre Quelle, (b) durch ihren Fettgehalt, (c) durch ihre Verpackung.
genus proximum ist Milch
Milch lässt sich unterscheiden anhand von Attributen, z.B. hat_Quelle(), hat_Fettgehalt() etc.
die spezifischen Eigenschaften, anand derer dann die Unterklassen gebildet werden, sind Kombinationen von Attributen und ihren möglichen sinnvollen Ausprägungen, z.B. hat_Quelle(Kuh), hat_Quelle(Schaf), hat_Verpackung(Tetrapack) usw.
Beispiel 2, Gewässer:
Meer, Binnengewässer, Fluss, See, Teich, Pfütze, Wadi
genus proximum ist Gewässer
Gewässer lassen sich z.B. unterscheiden in (a) in meeres-artige und binnen-artige, (b) fließende und stehende, (c) dauerhafte (perennierende) und zeitweise trockene (episodische, periodische, ephemere) Gewässer (siehe Wkidpedia > Gewässer)
Anders als im bereits sehr hoch vorstrukturierten Beispiel 1 lässt sich der sprachlichen Formulierung von Beispiel 2 nicht unmittelbar ablesen, wie die einzelnen Attribute benannt werden.
In Beispiel 2 kommt auch ein weiteres Konzept hinzu, das in Beispiel 1 nicht auftrat: In weiterem Sinn kann man Unter-Kategorien auch dadurch unterscheiden, dass man ihnen mehr als ein genus proximum zuordnet. (Wir kennen das z.B. aus der OO als Mehrfach-Vererbung).
In obigem Beispiel kann man ein Wadi charakterisieren
entweder als als fluss-artige, episodische Binnengewässer
oder als episodische Binnengewässer, für die als weiteres genus proximum “Fluss” eingetragen ist (und entsprechend Fluss als ein fluss-artiges Gewässer definiert wurde).