Wordnet#
The core concept in WordNet is the synset. A synset groups words [JB: UNGENAU! exakter wäre “senses”, notfalls auch “word meanings”, “lemma_name”, “wordsense ID”] with a synonymous meaning, such as
{car, auto, automobile, machine, motorcar}. Another sense of the word “car” is recorded in the synset{car, railcar, railway car, railroad car}. Although both synsets contain the word “car”, they are different entities in WordNet because they have a different meaning. https://www.w3.org/TR/wordnet-rdf/#wnmetamodel
Bildung von Wortfeldern und Begriffsfeldern, indem man Synonyme zu einem Feld, einem „Konzept“[1] (im Sinne einer Begrifflichkeit) zusammenfasst. https://de.wikipedia.org/wiki/Synset
According to WordNet, a synset or synonym set is defined as a set of one or more synonyms that are interchangeable in some context without changing the truth value of the proposition in which they are embedded. https://en.wikipedia.org/wiki/Synonym_ring

Quelle / dieses Beispiel live: WordNet > Search > “car”
Text:
{02961779} S: (n) car#1, auto#1, automobile#1, machine#6, motorcar#1 (a motor vehicle with four wheels; usually propelled by an internal combustion engine) “he needs a car to get to work”
{02963378} S: (n) car#2, railcar#1, railway car#1, railroad car#1 (a wheeled vehicle adapted to the rails of railroad) “three cars had jumped the rails”
{02963937} S: (n) car#3, gondola#3 (the compartment that is suspended from an airship and that carries personnel and the cargo and the power plant)
{02963788} S: (n) car#4, elevator car#1 (where passengers ride up and down) “the car was on the top floor”
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('motorcar'))
# Ausgabe: [Synset('car.n.01')]
print(wn.synset('car.n.01').lemma_names())
# Ausgabe: ['car', 'auto', 'automobile', 'machine', 'motorcar']
Für unsere Argumentation lässt sich die Idee von WordNet auf eine Tabelle reduzieren.
Datenmodell: Im Kern eine Tabelle, mit
Spalten: WordSense-ID
menschenlesbar:
car#1,car#2
Zeilen: Synset-ID
{15180180}
ABBILDUNG? Oder einfacher ein Dict von Listen, dann ein Pandas Dataframe … programmatisch erzeugen mit NLTK und car
Tatsächlich ist es natürlich komplexer. Für Interesserte:
BEGINN ZITAT der Quelle wordnet/wordnet:
Lexeme - unit of lexical meaning that exists regardless of the number of inflectional endings it may have or the number of words it may contain (e.g. run, ran, runs)
Lemma - particular form of a lexeme that is chosen by convention to represent a canonical form of a lexeme (e.g. run)
Sense - a Lexeme associated with particular meaning. Each Lexeme can have multiple Senses. In Wordnet each Sense is associated with number to easily distinguish (e.g. I can write run 4 meaning an unbroken series of events, or run 5 meaning the act of running)
Synset - a set of Senses (not Lexemes) with similar meaning, i.e. synonyms (e.g. run 2 forms Synset with following Senses: bunk 3, escape 6, turn tail 1).
Sense Relation - a relationship between two Senses, i.e. relationship between two particular meanings of words (e.g. big 1 is antonym of little 1)
Synset Relation - a relationship between two Synsets, i.e. relationship between two groups of Senses (e.g. Synset { act 10, play 25 } is hyponym of Synset { overact 1, overplay 1 }).
Relation Type - each SenseRelation and SynsetRelation has its type, it can be among others: antonym, hyponym, hyperonym, meronym, …
In summary: Each Lexeme is represented by Lemma. Each Lexeme has multiple Senses. Each Sense forms Synset with other Senses. Each Sense can be in SenseRelation to other Senses. Each Synset can be in SynsetRelation to other Synsets.
Above concepts of Wordnet are modelled in application in following way:

(Bild: https://raw.githubusercontent.com/wordnet/wordnet/master/doc/class_diagram.png)
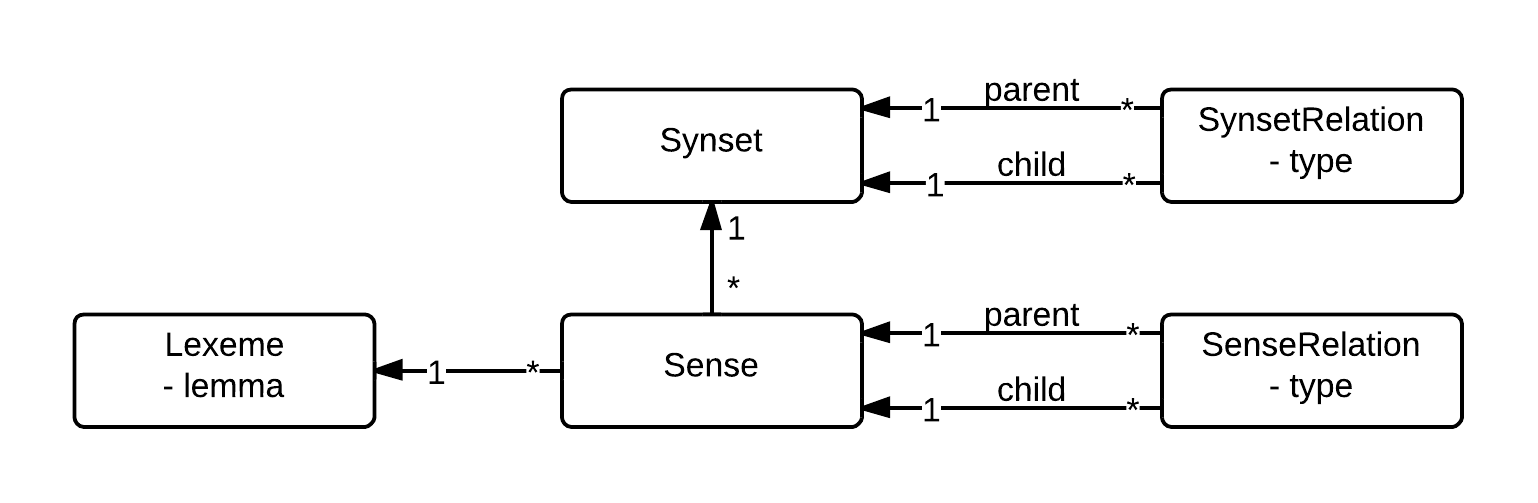{kind=link}
ENDE ZITAT der Quelle
WordNet hat also ein sehr differenziertes Datenmodell. Die für unsere Argumentation ausreichende maximale Vereinfachung ist die: Wir haben technisch gesehen zwei Tabellen, nämlich
Wort (repräsentiert durch Lemma) vs. WordSense
WordSense vs. Synset
Etwas differenzierter bilden beide Tabellen zusammen einen dreidimensionalen Raum:
Dimension 1, x-Achse: Wort
Vertreter: Rechtschreib-Duden Band 1: Lemmata plus grammatikalische Informationen wie Genus, Pluralformen, Deklination / Konjugation etc.
Wort
lemon:lexical_entry
Dimension 2, y-Achse: EN:Sense, DE:Bedeutung, Term
Gottlieb Frege verwendet um 1890 “Sinn” und “Bedeutung” gerade umgekehrt, der heutige Sprachgebrauch in DE ist anders; Wordnet verwendet “sense” * Vertreter: große, dicke Wörterbücher wie z.B. “Wahrig”: Es werden verschiedene Bedeutungen unterschieden
lemon:lexical_sense
skos: concept (?)
Tag(1): 24h; Tag(2): heller Teil eines Tag(1); Tag(3): Gedenk~, Geburts~ etc.
Dimension 3, z-Achse: Synset
Menge von Senses, die in einem bestimmten Verwendungszusammenhang eine ähnliche Bedeutung (sense) haben.
Vertreter: Wordnet
skos: concept (?)
Wichtig: im Princeton Wordnet besteht ein Synset aus Entitäten der y-Achse, also Senses, und nicht Lemmata aus der x-Achse
Interpretation JB:
Wortfeld Dimension 1 betrifft Syntax: Wort, Lexem, Syntax, Wortformen
Wortfeld Dimension 2 betrifft Semantik: Term
Wortfeld Dimension 3 betrifft zusätzlich auch Pragmatik: Synset
Zum Weiterlesen:
RDF/OWL Representation of WordNet. W3C Working Draft 19 June 2006 https://www.w3.org/TR/wordnet-rdf/
Kategorien in Germanet: Beschreibung
https://www.w3.org/2015/09/bpmlod-reports/multilingual-dictionaries/