Cosinus Ähnlichkeit, Markdown
Contents
Cosinus Ähnlichkeit, Markdown#
J.Busse, www.jbusse.de, 2021-04-12, 2022-04-19, spaCy: 2022-06-09
Lizenz: public domain / CC 0
Dieses Notebook: Erstes Eingangs-Beispiel für die LV dsci-txt SS 2021 HAW LA … ein minimales Mini-Programm, das die Cosinus-Ähnlichkeit zwischen (Markdown-) Texten als seaborn-Clustermap visualisiert.
Beabsichtigte Verwendung:
Studierende haben einen lauffähigen Ausgangspunkt,
den sie hier und da spielerisch verändern können.
VEREINBARUNG: Wenn Code-Snippets im Netz recherchiert und nur unwesentlich verändert wurden, dann wird die Quelle in der ersten Zeile einer Zelle mit URL referenziert (siehe z.B. unten glob). Es liegt damit auch kein Plagiat mehr vor. Umgekehrt gilt: Eine Zelle, die keine Quellenangabe enhält, gilt als “aus dem Kopf” selbst geschrieben.
Dateien:
auspacken; das Verzeichnis
regex_XX/sollte idealerweise als Geschwister-Verzeichnis des aktuellen Arbeitsverzeichnismd/angelegt werden.
import numpy as np
import pandas as pd
Global Parameters#
# path to files, incl. glob mask
#path_to_ipynb = "md/*.md"
path_to_ipynb = "../regex_XX/*.md"
# show intermediary results
# 0 none, 1 informative, 2 debug
verbosity = 1
def verbose(level,item):
if level <= verbosity:
display(item)
Read Files#
# https://stackoverflow.com/questions/3207219/how-do-i-list-all-files-of-a-directory
import glob
files = glob.glob(path_to_ipynb)
verbose(1,len(files))
verbose(2,files)
15
files
['../regex_XX/regex_8.md',
'../regex_XX/regex_6.md',
'../regex_XX/regex_5.md',
'../regex_XX/regex_12.md',
'../regex_XX/regex_wiki_2.md',
'../regex_XX/regex_9.md',
'../regex_XX/regex_2.md',
'../regex_XX/regex_15.md',
'../regex_XX/regex_4.md',
'../regex_XX/regex_wiki_1.md',
'../regex_XX/regex_14.md',
'../regex_XX/regex_10.md',
'../regex_XX/regex_7.md',
'../regex_XX/regex_1.md',
'../regex_XX/regex_13.md']
type(files[0])
str
corpus_dict = {}
for file in files:
with open(file, 'r') as f:
corpus_dict[file] = f.read()
corpus_dict
{'../regex_XX/regex_8.md': 'Reguläre Ausdrücke finden in der Informatik sehr häufige Anwendung.\nSie sind vor allem bei der Suche von großer Bedeutung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".*" jede beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und der Stern dahinter für eine beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_6.md': 'Kann beim Programmieren für diverse Problemlösungen verwendet werden um in Strings etwas zu \nsuchen oder darin etwas zu prüfen bzw. zu bearbeiten. \nReguläre Ausdrücke werden auch als RegEx abgekürzt.',
'../regex_XX/regex_5.md': '\nRegex wird benutzt um Texte nach bestimmten Mustern zu durchsuchen.\nDafür wird eine Zeichenkette aus verschiedenen Symbolen verwendet welche das zu suchende Muster beschreiben.\nReguläre Ausdrücke gehören zu den formalen Sprachen.\nDie Symbole sind teil der Sprachgrammatik.\nAußerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_12.md': 'Reguläre Ausdrücke sind ein Tool, um Teile eines Texts zu extrahieren oder um einen Text auf ein bestimmtes Format zu überprüfen. Reguläre Ausdrücke können dabei beliebig lang sein.\nSie bestehen aus Character-Klassen, Gruppen, Wildcard, Wiederholungen und festen Zeichen. Zum Kompilieren von Regulären Ausdrücken wird eine spezielle Enginge genutzt.',
'../regex_XX/regex_wiki_2.md': 'Reguläre Ausdrücke können als Filterkriterien in der Textsuche verwendet werden, indem der Text mit dem Muster des regulären Ausdrucks abgeglichen wird. Dieser Vorgang wird auch Pattern Matching genannt. So ist es beispielsweise möglich, alle Wörter aus einer Wortliste herauszusuchen, die mit S beginnen und auf D enden, ohne die dazwischen liegenden Buchstaben oder deren Anzahl explizit vorgeben zu müssen.\n\n',
'../regex_XX/regex_9.md': 'Der Begriff Regex steht für einen Regulären Ausdruck (Zeichenfolge). Diese werden vor allem dafür verwendet eine gewissen Ausdruck in einem vorgegebenen Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien zu implementieren, so kann man mittels des *-Operators 0 oder beliebig viele Zeichen des vorangehenden Ausdrucks gesucht werden. Zudem müssen gewisse Operatoren wie ein * oder ein + mithilfe eines \\ "escaped" werden. \n',
'../regex_XX/regex_2.md': "Unter dem Begriff Regex versteht man einen reguläre Ausdrücke (Zeichenfolgen). Diese werden dafür verwendet einen beliebigen Ausdruck in einem vorgegebenem Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien festzulegen. Beispielsweise können mittels des '*'-Operators 0 - beliebig viele Zeichen des vorangehenden Ausdrucks 'gematched' werden. Falls man aber nach dem '*'-Symbol im Text suchen möchte, muss dieses Zeichen mit einem '\\' (escape-character) gekennzeichnet werden.",
'../regex_XX/regex_15.md': '# Regex\n\nUnter Regex bzw. Regular Expressions versteht man sogenannte Charaktersequenzen (Regex Strings) mit denen man gezielt Strings durchsuchen, prüfen oder auch ersetzen kann.\n\n\n```elixir\n# A simple regular expression that matches foo anywhere in the string\nregex = ~r/foo/\nString.match("foo bar Hello World" , regex)\n````\nAußerdem gibt es noch Flags die am Ende des RegexStrings gesetz werden können:\n```elixir\n# A regular expression with case insensitive and Unicode options\n~r/foo/iu\n```',
'../regex_XX/regex_4.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_wiki_1.md': 'Ein regulärer Ausdruck (englisch regular expression, Abkürzung RegExp oder Regex) ist in der theoretischen Informatik eine Zeichenkette, die der Beschreibung von Mengen von Zeichenketten mit Hilfe bestimmter syntaktischer Regeln dient. Reguläre Ausdrücke finden vor allem in der Softwareentwicklung Verwendung. Neben Implementierungen in vielen Programmiersprachen verarbeiten auch viele Texteditoren reguläre Ausdrücke in der Funktion „Suchen und Ersetzen“. Ein einfacher Anwendungsfall von regulären Ausdrücken sind Wildcards.\n',
'../regex_XX/regex_14.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_10.md': 'Regex kann benutzt werden um Texte nach bestimmten Mustern zu durchsuchen. Dafür verwendet man eine Zeichenkette aus verschiedenen Symbolen welche den zu suchenden Text beschreiben können. Reguläre Ausdrücken sind Teil von formalen Sprachen. Die Symbole sind teil der Sprachgrammatik. Außerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_7.md': 'Reguläre Ausdrücke (REGEX) sind vor allem bei der Suche von großer Bedeutung.\nSie finden in der Informatik sehr häufige Anwendung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".+" mindestens eine beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und das Plus dahinter für mindestens ein beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_1.md': 'Reguläre Ausdrücke sind ein Tool, das es erlaubt Ausschnitte eines Texts zu extrahieren oder ihn auf ein gewisses Format zu überprüfen. Die Länge des Regex ist dabei egal.\nDie Ausdrücke bestehen aus festen Zeichen, Wildcards, Gruppen und Character-Klassen.\nEine Regex Engine wird benötigt, um die Ausdrücke zu kompilieren.\n',
'../regex_XX/regex_13.md': 'Mithilfe von *Regex* kann man **Texte** nach bestimmten Eigenschaften **überprüfen und Filtern**.\n> Beispielsweise kann man somit Telefonnummern aus einem Webseite herausfinden, ohne groß suchen zu müssen.\n\n'}
corpus = list(corpus_dict.values())
corpus
['Reguläre Ausdrücke finden in der Informatik sehr häufige Anwendung.\nSie sind vor allem bei der Suche von großer Bedeutung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".*" jede beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und der Stern dahinter für eine beliebige Anzahl dieses vorangegangenen Zeichens.',
'Kann beim Programmieren für diverse Problemlösungen verwendet werden um in Strings etwas zu \nsuchen oder darin etwas zu prüfen bzw. zu bearbeiten. \nReguläre Ausdrücke werden auch als RegEx abgekürzt.',
'\nRegex wird benutzt um Texte nach bestimmten Mustern zu durchsuchen.\nDafür wird eine Zeichenkette aus verschiedenen Symbolen verwendet welche das zu suchende Muster beschreiben.\nReguläre Ausdrücke gehören zu den formalen Sprachen.\nDie Symbole sind teil der Sprachgrammatik.\nAußerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'Reguläre Ausdrücke sind ein Tool, um Teile eines Texts zu extrahieren oder um einen Text auf ein bestimmtes Format zu überprüfen. Reguläre Ausdrücke können dabei beliebig lang sein.\nSie bestehen aus Character-Klassen, Gruppen, Wildcard, Wiederholungen und festen Zeichen. Zum Kompilieren von Regulären Ausdrücken wird eine spezielle Enginge genutzt.',
'Reguläre Ausdrücke können als Filterkriterien in der Textsuche verwendet werden, indem der Text mit dem Muster des regulären Ausdrucks abgeglichen wird. Dieser Vorgang wird auch Pattern Matching genannt. So ist es beispielsweise möglich, alle Wörter aus einer Wortliste herauszusuchen, die mit S beginnen und auf D enden, ohne die dazwischen liegenden Buchstaben oder deren Anzahl explizit vorgeben zu müssen.\n\n',
'Der Begriff Regex steht für einen Regulären Ausdruck (Zeichenfolge). Diese werden vor allem dafür verwendet eine gewissen Ausdruck in einem vorgegebenen Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien zu implementieren, so kann man mittels des *-Operators 0 oder beliebig viele Zeichen des vorangehenden Ausdrucks gesucht werden. Zudem müssen gewisse Operatoren wie ein * oder ein + mithilfe eines \\ "escaped" werden. \n',
"Unter dem Begriff Regex versteht man einen reguläre Ausdrücke (Zeichenfolgen). Diese werden dafür verwendet einen beliebigen Ausdruck in einem vorgegebenem Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien festzulegen. Beispielsweise können mittels des '*'-Operators 0 - beliebig viele Zeichen des vorangehenden Ausdrucks 'gematched' werden. Falls man aber nach dem '*'-Symbol im Text suchen möchte, muss dieses Zeichen mit einem '\\' (escape-character) gekennzeichnet werden.",
'# Regex\n\nUnter Regex bzw. Regular Expressions versteht man sogenannte Charaktersequenzen (Regex Strings) mit denen man gezielt Strings durchsuchen, prüfen oder auch ersetzen kann.\n\n\n```elixir\n# A simple regular expression that matches foo anywhere in the string\nregex = ~r/foo/\nString.match("foo bar Hello World" , regex)\n````\nAußerdem gibt es noch Flags die am Ende des RegexStrings gesetz werden können:\n```elixir\n# A regular expression with case insensitive and Unicode options\n~r/foo/iu\n```',
'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'Ein regulärer Ausdruck (englisch regular expression, Abkürzung RegExp oder Regex) ist in der theoretischen Informatik eine Zeichenkette, die der Beschreibung von Mengen von Zeichenketten mit Hilfe bestimmter syntaktischer Regeln dient. Reguläre Ausdrücke finden vor allem in der Softwareentwicklung Verwendung. Neben Implementierungen in vielen Programmiersprachen verarbeiten auch viele Texteditoren reguläre Ausdrücke in der Funktion „Suchen und Ersetzen“. Ein einfacher Anwendungsfall von regulären Ausdrücken sind Wildcards.\n',
'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'Regex kann benutzt werden um Texte nach bestimmten Mustern zu durchsuchen. Dafür verwendet man eine Zeichenkette aus verschiedenen Symbolen welche den zu suchenden Text beschreiben können. Reguläre Ausdrücken sind Teil von formalen Sprachen. Die Symbole sind teil der Sprachgrammatik. Außerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'Reguläre Ausdrücke (REGEX) sind vor allem bei der Suche von großer Bedeutung.\nSie finden in der Informatik sehr häufige Anwendung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".+" mindestens eine beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und das Plus dahinter für mindestens ein beliebige Anzahl dieses vorangegangenen Zeichens.',
'Reguläre Ausdrücke sind ein Tool, das es erlaubt Ausschnitte eines Texts zu extrahieren oder ihn auf ein gewisses Format zu überprüfen. Die Länge des Regex ist dabei egal.\nDie Ausdrücke bestehen aus festen Zeichen, Wildcards, Gruppen und Character-Klassen.\nEine Regex Engine wird benötigt, um die Ausdrücke zu kompilieren.\n',
'Mithilfe von *Regex* kann man **Texte** nach bestimmten Eigenschaften **überprüfen und Filtern**.\n> Beispielsweise kann man somit Telefonnummern aus einem Webseite herausfinden, ohne groß suchen zu müssen.\n\n']
spaCy#
(2022-06-09)
Intro in spaCy: https://spacy.io/usage/spacy-101
import spacy
nlp = spacy.load("de_core_news_sm")
nlp(corpus[2])
Regex wird benutzt um Texte nach bestimmten Mustern zu durchsuchen.
Dafür wird eine Zeichenkette aus verschiedenen Symbolen verwendet welche das zu suchende Muster beschreiben.
Reguläre Ausdrücke gehören zu den formalen Sprachen.
Die Symbole sind teil der Sprachgrammatik.
Außerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.
def lemma_string(text, postags = None):
"""returns lemmata of a string, joined again to a string"""
txt = nlp(text)
txt_lemmata = [ t.lemma_ for t in txt if (not postags or t.pos_ in postags) ]
return " ".join(txt_lemmata)
postags = ['NOUN', 'VERB', 'ADJ']
lemma_string(corpus[2], postags)
'benutzen Text bestimmt Muster durchsuchen Zeichenkette verschieden Symbole verwenden welcher suchend Muster beschreiben regulär Ausdruck gehören formal Sprache Symbol Sprachgrammatik endlich Automat bilden'
corpus_lemmatized = [ lemma_string(c, postags) for c in corpus ]
corpus_lemmatized[2]
'benutzen Text bestimmt Muster durchsuchen Zeichenkette verschieden Symbole verwenden welcher suchend Muster beschreiben regulär Ausdruck gehören formal Sprache Symbol Sprachgrammatik endlich Automat bilden'
Bag of Words: CountVectorizer#
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
#bag_of_words = count.fit_transform(np.array(corpus))
bag_of_words = count.fit_transform(np.array(corpus_lemmatized))
verbose(2,type(bag_of_words))
bag_of_words
<15x149 sparse matrix of type '<class 'numpy.int64'>'
with 281 stored elements in Compressed Sparse Row format>
feature_names = count.get_feature_names()
len(feature_names)
/home/dsci/miniconda3/lib/python3.9/site-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
warnings.warn(msg, category=FutureWarning)
149
pd.DataFrame(bag_of_words.toarray(), columns=feature_names).T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| abgeglichen | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| abkürzen | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| abkürzung | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| angeben | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| anwendung | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| zeichenfolgen | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| zeichenkett | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| zeichenkette | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| äquivalent | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| überprüfen | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
149 rows × 15 columns
TfIdf#
https://chrisalbon.com/machine_learning/preprocessing_text/tf-idf/
Equivalent to CountVectorizer followed by TfidfTransformer:
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False)
verbose(1,transformer)
TfidfTransformer(smooth_idf=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TfidfTransformer(smooth_idf=False)
tfidf = transformer.fit_transform(bag_of_words)
verbose(1,pd.DataFrame(tfidf.toarray()))
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00000 | 0.000000 | 0.000000 | 0.204621 | 0.204621 | 0.000000 | 0.000000 | 0.177102 | 0.083015 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.260117 | 0.177102 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.00000 | 0.377075 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.124383 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.091374 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.194937 | 0.000000 | 0.000000 |
| 3 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.173448 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.135870 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.185016 |
| 4 | 0.24362 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.171441 | 0.160722 | 0.000000 | ... | 0.000000 | 0.171441 | 0.24362 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 5 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.270586 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.141308 | 0.192421 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 6 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.267777 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.279682 | 0.000000 | 0.270595 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 7 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.235875 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 8 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.164995 | 0.000000 | ... | 0.000000 | 0.351998 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.203346 | 0.000000 |
| 9 | 0.00000 | 0.000000 | 0.195483 | 0.000000 | 0.000000 | 0.195483 | 0.000000 | 0.000000 | 0.193447 | 0.158941 | ... | 0.195483 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.195483 | 0.137566 | 0.000000 | 0.000000 |
| 10 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.164995 | 0.000000 | ... | 0.000000 | 0.351998 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.203346 | 0.000000 |
| 11 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.235470 | ... | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.203802 | 0.000000 | 0.000000 |
| 12 | 0.00000 | 0.000000 | 0.000000 | 0.204621 | 0.204621 | 0.000000 | 0.000000 | 0.177102 | 0.083015 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.260117 | 0.177102 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 13 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.239961 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.125315 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.170643 |
| 14 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.268513 |
15 rows × 149 columns
Cosine Similarity#
interessant, ggf. auch noch ausprobieren?: https://stackoverflow.com/questions/17627219/whats-the-fastest-way-in-python-to-calculate-cosine-similarity-given-sparse-mat
Wir machen es hier eher low level, um unter die Motorhaube sehen zu können:
https://scikit-learn.org/stable/modules/metrics.html#cosine-similarity
didaktische Erklärung: http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(tfidf)
#verbose(2,similarity)
similarity_df = pd.DataFrame(similarity)
similarity_df.columns = files
similarity_df.index = files
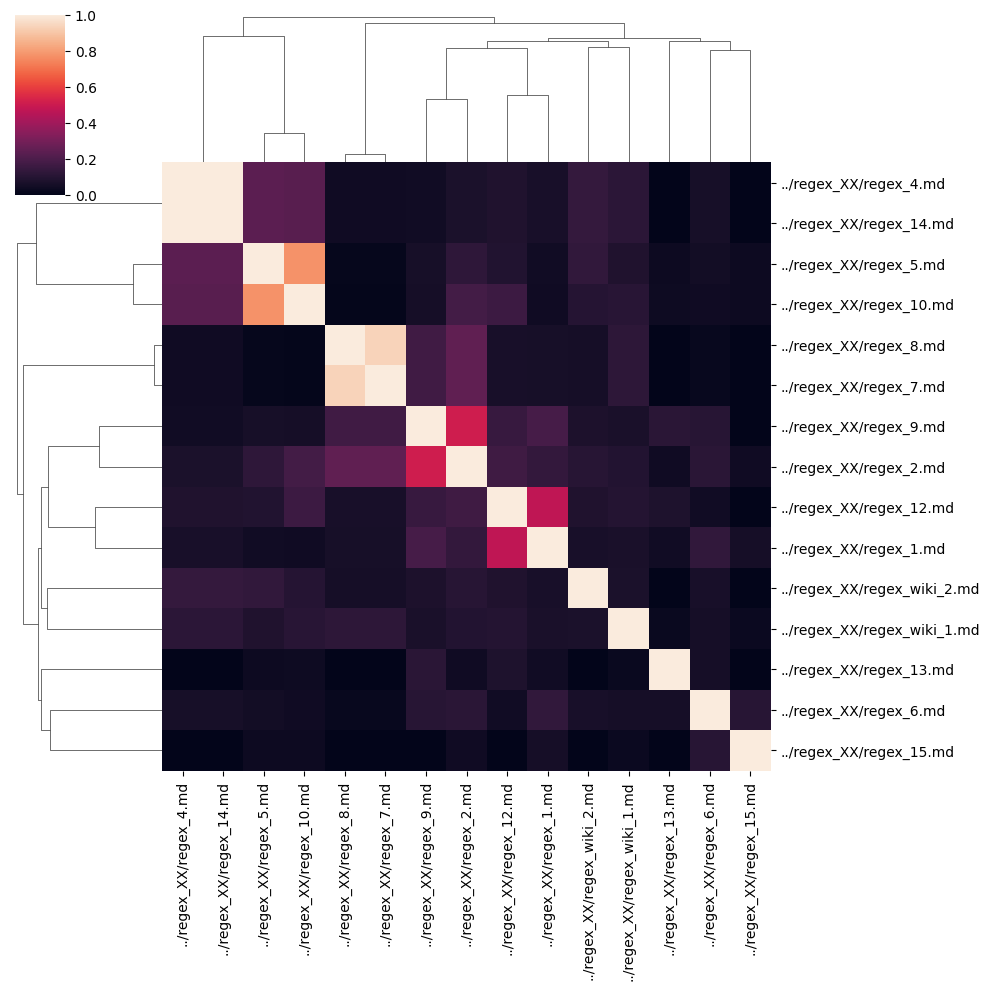
similarity_df
| ../regex_XX/regex_8.md | ../regex_XX/regex_6.md | ../regex_XX/regex_5.md | ../regex_XX/regex_12.md | ../regex_XX/regex_wiki_2.md | ../regex_XX/regex_9.md | ../regex_XX/regex_2.md | ../regex_XX/regex_15.md | ../regex_XX/regex_4.md | ../regex_XX/regex_wiki_1.md | ../regex_XX/regex_14.md | ../regex_XX/regex_10.md | ../regex_XX/regex_7.md | ../regex_XX/regex_1.md | ../regex_XX/regex_13.md | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ../regex_XX/regex_8.md | 1.000000 | 0.020651 | 0.015171 | 0.064139 | 0.057047 | 0.171460 | 0.247189 | 0.000000 | 0.041091 | 0.117714 | 0.041091 | 0.007930 | 0.936665 | 0.059157 | 0.000000 |
| ../regex_XX/regex_6.md | 0.020651 | 1.000000 | 0.050627 | 0.043148 | 0.064516 | 0.101615 | 0.111663 | 0.102845 | 0.061568 | 0.056143 | 0.061568 | 0.041048 | 0.020651 | 0.130359 | 0.056407 |
| ../regex_XX/regex_5.md | 0.015171 | 0.050627 | 1.000000 | 0.087919 | 0.129476 | 0.062059 | 0.123619 | 0.032358 | 0.235355 | 0.085406 | 0.235355 | 0.774468 | 0.015171 | 0.044405 | 0.033856 |
| ../regex_XX/regex_12.md | 0.064139 | 0.043148 | 0.087919 | 1.000000 | 0.084683 | 0.146126 | 0.164193 | 0.000000 | 0.085854 | 0.094753 | 0.085854 | 0.160074 | 0.064139 | 0.470051 | 0.081812 |
| ../regex_XX/regex_wiki_2.md | 0.057047 | 0.064516 | 0.129476 | 0.084683 | 1.000000 | 0.076323 | 0.104764 | 0.000000 | 0.139901 | 0.072546 | 0.139901 | 0.101004 | 0.057047 | 0.064764 | 0.000000 |
| ../regex_XX/regex_9.md | 0.171460 | 0.101615 | 0.062059 | 0.146126 | 0.076323 | 1.000000 | 0.511345 | 0.000000 | 0.044645 | 0.069465 | 0.044645 | 0.056916 | 0.171460 | 0.185277 | 0.109875 |
| ../regex_XX/regex_2.md | 0.247189 | 0.111663 | 0.123619 | 0.164193 | 0.104764 | 0.511345 | 1.000000 | 0.042195 | 0.073636 | 0.091767 | 0.073636 | 0.177865 | 0.247189 | 0.136080 | 0.040479 |
| ../regex_XX/regex_15.md | 0.000000 | 0.102845 | 0.032358 | 0.000000 | 0.000000 | 0.000000 | 0.042195 | 1.000000 | 0.000000 | 0.030482 | 0.000000 | 0.033829 | 0.000000 | 0.056650 | 0.000000 |
| ../regex_XX/regex_4.md | 0.041091 | 0.061568 | 0.235355 | 0.085854 | 0.139901 | 0.044645 | 0.073636 | 0.000000 | 1.000000 | 0.117032 | 1.000000 | 0.230297 | 0.041091 | 0.065987 | 0.000000 |
| ../regex_XX/regex_wiki_1.md | 0.117714 | 0.056143 | 0.085406 | 0.094753 | 0.072546 | 0.069465 | 0.091767 | 0.030482 | 0.117032 | 1.000000 | 0.117032 | 0.108236 | 0.117714 | 0.067051 | 0.023892 |
| ../regex_XX/regex_14.md | 0.041091 | 0.061568 | 0.235355 | 0.085854 | 0.139901 | 0.044645 | 0.073636 | 0.000000 | 1.000000 | 0.117032 | 1.000000 | 0.230297 | 0.041091 | 0.065987 | 0.000000 |
| ../regex_XX/regex_10.md | 0.007930 | 0.041048 | 0.774468 | 0.160074 | 0.101004 | 0.056916 | 0.177865 | 0.033829 | 0.230297 | 0.108236 | 0.230297 | 1.000000 | 0.007930 | 0.039360 | 0.035395 |
| ../regex_XX/regex_7.md | 0.936665 | 0.020651 | 0.015171 | 0.064139 | 0.057047 | 0.171460 | 0.247189 | 0.000000 | 0.041091 | 0.117714 | 0.041091 | 0.007930 | 1.000000 | 0.059157 | 0.000000 |
| ../regex_XX/regex_1.md | 0.059157 | 0.130359 | 0.044405 | 0.470051 | 0.064764 | 0.185277 | 0.136080 | 0.056650 | 0.065987 | 0.067051 | 0.065987 | 0.039360 | 0.059157 | 1.000000 | 0.045820 |
| ../regex_XX/regex_13.md | 0.000000 | 0.056407 | 0.033856 | 0.081812 | 0.000000 | 0.109875 | 0.040479 | 0.000000 | 0.000000 | 0.023892 | 0.000000 | 0.035395 | 0.000000 | 0.045820 | 1.000000 |
import seaborn as sns
mask = np.zeros_like(similarity)
mask[np.triu_indices_from(mask)] = True
#ax = sns.heatmap(similarity_df)
ax = sns.clustermap(similarity_df)
ax.savefig("clustermap.png")
https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.linkage.html
corpus_dict['regex_XX/regex_8.md']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In [23], line 1
----> 1 corpus_dict['regex_XX/regex_8.md']
KeyError: 'regex_XX/regex_8.md'
corpus_dict['regex_XX/regex_7.md']
corpus_dict['regex_XX/regex_wiki_1.md']