Bag of char ngrams erstellen
Contents
Bag of char ngrams erstellen#
J.Busse, www.jbusse.de, 2023-05-30
Version für n-Gramme, basierend auf Bag of Words erstellen
Lizenz: public domain / CC 0
Idee:
one might alternatively consider a collection of character n-grams, a representation resilient against misspellings and derivations. https://scikit-learn.org/stable/modules/feature_extraction.html#limitations-of-the-bag-of-words-representation
Dateien:
auspacken; das Verzeichnis
regex_XX/sollte idealerweise als Geschwister-Verzeichnis des aktuellen Arbeitsverzeichnismd/angelegt werden – oder ggf. Variablepath_to_mdanpassen.
Global Parameters#
import numpy as np
import pandas as pd
import random
random.seed(42)
# show intermediary results
# 0 none, 1 informative, 2 didactical, 3 debug
verbosity = 2
def verbose(level,item):
if level <= verbosity:
display(item)
fehler = 0.3
Tippfehler#
Idee: Wir bauen in unsere Texte programmatisch eine hohe Anzahl von Tippfehlern ein. Ein konventioneller BOW-Ansatz auf Wort-Ebene sollte hier keine große Ähnlichkeit mehr entdecken.
tastatur = (
"""qw we er rt tz ty zu ui io op pü""" # obere Reihe
"""as sd df fg gh hj jk kl lö öä""" # mittlere Reihe
"""yx yz xc cv vb bn nm""" # untere Reihe
"""12 23 34 45 56 67 78 89 90"""
)
# alle Zeichen, für die wir Fehler kennen
tastatur_set = { c for word in tastatur.split() for c in word }
print(tastatur_set)
{'ü', 'c', 'u', 'd', '6', '8', 'o', 'ö', 'q', 'f', 'l', 'v', '3', 'ä', 'm', 'w', '5', 'x', 'a', 's', 'z', 'e', '1', 't', 'g', '2', '7', '4', 'n', 'i', '9', 'j', 'y', 'p', 'k', '0', 'b', 'r', 'h'}
nachbarn_set = { c: set() for c in tastatur_set}
for word in tastatur.split():
for c in word:
nachbarn_set[c].update(word)
#print(nachbarn_set)
nachbarn_dict = { k: list(v) for k,v in nachbarn_set.items() }
print(nachbarn_dict)
{'ü': ['s', 'ü', 'p', 'a'], 'c': ['v', 'c', 'x'], 'u': ['i', 'u', 'z'], 'd': ['s', 'd', 'f'], '6': ['5', '6', '7'], '8': ['9', '7', '8'], 'o': ['o', 'i', 'p'], 'ö': ['y', 'x', 'ö', 'l', 'ä'], 'q': ['w', 'q'], 'f': ['d', 'f', 'g'], 'l': ['k', 'ö', 'l'], 'v': ['c', 'b', 'v'], '3': ['4', '2', '3'], 'ä': ['y', 'x', 'ä', 'ö'], 'm': ['m', 'n', '2', '1'], 'w': ['w', 'e', 'q'], '5': ['4', '5', '6'], 'x': ['c', 'y', 'x', 'ö', 'ä'], 'a': ['s', 'ü', 'p', 'a'], 's': ['ü', 'd', 'p', 's', 'a'], 'z': ['y', 'u', 'z', 't'], 'e': ['w', 'e', 'r'], '1': ['m', 'n', '2', '1'], 't': ['z', 'y', 'r', 't'], 'g': ['h', 'f', 'g'], '2': ['m', '3', '2', 'n', '1'], '7': ['6', '7', '8'], '4': ['4', '5', '3'], 'n': ['m', 'b', '2', 'n', '1'], 'i': ['o', 'i', 'u'], '9': ['0', '9', '8'], 'j': ['j', 'k', 'h'], 'y': ['t', 'y', 'x', 'ö', 'z', 'ä'], 'p': ['ü', 'p', 'o', 's', 'a'], 'k': ['j', 'k', 'l'], '0': ['0', '9'], 'b': ['n', 'b', 'v'], 'r': ['e', 'r', 't'], 'h': ['j', 'h', 'g']}
import random
def dreher(zeichen, fehler):
if zeichen not in tastatur_set: return zeichen
t = random.random()
if t < fehler: ret = random.choice(nachbarn_dict[zeichen])
else: ret = zeichen # nix falsch gemacht
return ret
for c in "Hallo Hugo":
print(dreher(c, 0.3))
H
a
ö
k
o
H
u
g
i
Read Files#
# path to files, incl. glob mask
#path_to_md = "md/*.md"
path_to_md = "../regex_XX/*.md"
# https://stackoverflow.com/questions/3207219/how-do-i-list-all-files-of-a-directory
import glob
files = glob.glob(path_to_md)
verbose(1,f"{len(files)} Dateien gefunden")
files
'15 Dateien gefunden'
['../regex_XX/regex_8.md',
'../regex_XX/regex_6.md',
'../regex_XX/regex_5.md',
'../regex_XX/regex_12.md',
'../regex_XX/regex_wiki_2.md',
'../regex_XX/regex_9.md',
'../regex_XX/regex_2.md',
'../regex_XX/regex_15.md',
'../regex_XX/regex_4.md',
'../regex_XX/regex_wiki_1.md',
'../regex_XX/regex_14.md',
'../regex_XX/regex_10.md',
'../regex_XX/regex_7.md',
'../regex_XX/regex_1.md',
'../regex_XX/regex_13.md']
Wir lesen die Daten in das Dictionary corpus_dict ein:
corpus_dict_of_strings = {}
for file in files:
with open(file, 'r') as f:
corpus_dict_of_strings[file] = f.read()
verbose(2,corpus_dict_of_strings)
{'../regex_XX/regex_8.md': 'Reguläre Ausdrücke finden in der Informatik sehr häufige Anwendung.\nSie sind vor allem bei der Suche von großer Bedeutung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".*" jede beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und der Stern dahinter für eine beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_6.md': 'Kann beim Programmieren für diverse Problemlösungen verwendet werden um in Strings etwas zu \nsuchen oder darin etwas zu prüfen bzw. zu bearbeiten. \nReguläre Ausdrücke werden auch als RegEx abgekürzt.',
'../regex_XX/regex_5.md': '\nRegex wird benutzt um Texte nach bestimmten Mustern zu durchsuchen.\nDafür wird eine Zeichenkette aus verschiedenen Symbolen verwendet welche das zu suchende Muster beschreiben.\nReguläre Ausdrücke gehören zu den formalen Sprachen.\nDie Symbole sind teil der Sprachgrammatik.\nAußerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_12.md': 'Reguläre Ausdrücke sind ein Tool, um Teile eines Texts zu extrahieren oder um einen Text auf ein bestimmtes Format zu überprüfen. Reguläre Ausdrücke können dabei beliebig lang sein.\nSie bestehen aus Character-Klassen, Gruppen, Wildcard, Wiederholungen und festen Zeichen. Zum Kompilieren von Regulären Ausdrücken wird eine spezielle Enginge genutzt.',
'../regex_XX/regex_wiki_2.md': 'Reguläre Ausdrücke können als Filterkriterien in der Textsuche verwendet werden, indem der Text mit dem Muster des regulären Ausdrucks abgeglichen wird. Dieser Vorgang wird auch Pattern Matching genannt. So ist es beispielsweise möglich, alle Wörter aus einer Wortliste herauszusuchen, die mit S beginnen und auf D enden, ohne die dazwischen liegenden Buchstaben oder deren Anzahl explizit vorgeben zu müssen.\n\n',
'../regex_XX/regex_9.md': 'Der Begriff Regex steht für einen Regulären Ausdruck (Zeichenfolge). Diese werden vor allem dafür verwendet eine gewissen Ausdruck in einem vorgegebenen Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien zu implementieren, so kann man mittels des *-Operators 0 oder beliebig viele Zeichen des vorangehenden Ausdrucks gesucht werden. Zudem müssen gewisse Operatoren wie ein * oder ein + mithilfe eines \\ "escaped" werden. \n',
'../regex_XX/regex_2.md': "Unter dem Begriff Regex versteht man einen reguläre Ausdrücke (Zeichenfolgen). Diese werden dafür verwendet einen beliebigen Ausdruck in einem vorgegebenem Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien festzulegen. Beispielsweise können mittels des '*'-Operators 0 - beliebig viele Zeichen des vorangehenden Ausdrucks 'gematched' werden. Falls man aber nach dem '*'-Symbol im Text suchen möchte, muss dieses Zeichen mit einem '\\' (escape-character) gekennzeichnet werden.",
'../regex_XX/regex_15.md': '# Regex\n\nUnter Regex bzw. Regular Expressions versteht man sogenannte Charaktersequenzen (Regex Strings) mit denen man gezielt Strings durchsuchen, prüfen oder auch ersetzen kann.\n\n\n```elixir\n# A simple regular expression that matches foo anywhere in the string\nregex = ~r/foo/\nString.match("foo bar Hello World" , regex)\n````\nAußerdem gibt es noch Flags die am Ende des RegexStrings gesetz werden können:\n```elixir\n# A regular expression with case insensitive and Unicode options\n~r/foo/iu\n```',
'../regex_XX/regex_4.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_wiki_1.md': 'Ein regulärer Ausdruck (englisch regular expression, Abkürzung RegExp oder Regex) ist in der theoretischen Informatik eine Zeichenkette, die der Beschreibung von Mengen von Zeichenketten mit Hilfe bestimmter syntaktischer Regeln dient. Reguläre Ausdrücke finden vor allem in der Softwareentwicklung Verwendung. Neben Implementierungen in vielen Programmiersprachen verarbeiten auch viele Texteditoren reguläre Ausdrücke in der Funktion „Suchen und Ersetzen“. Ein einfacher Anwendungsfall von regulären Ausdrücken sind Wildcards.\n',
'../regex_XX/regex_14.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_10.md': 'Regex kann benutzt werden um Texte nach bestimmten Mustern zu durchsuchen. Dafür verwendet man eine Zeichenkette aus verschiedenen Symbolen welche den zu suchenden Text beschreiben können. Reguläre Ausdrücken sind Teil von formalen Sprachen. Die Symbole sind teil der Sprachgrammatik. Außerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_7.md': 'Reguläre Ausdrücke (REGEX) sind vor allem bei der Suche von großer Bedeutung.\nSie finden in der Informatik sehr häufige Anwendung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".+" mindestens eine beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und das Plus dahinter für mindestens ein beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_1.md': 'Reguläre Ausdrücke sind ein Tool, das es erlaubt Ausschnitte eines Texts zu extrahieren oder ihn auf ein gewisses Format zu überprüfen. Die Länge des Regex ist dabei egal.\nDie Ausdrücke bestehen aus festen Zeichen, Wildcards, Gruppen und Character-Klassen.\nEine Regex Engine wird benötigt, um die Ausdrücke zu kompilieren.\n',
'../regex_XX/regex_13.md': 'Mithilfe von *Regex* kann man **Texte** nach bestimmten Eigenschaften **überprüfen und Filtern**.\n> Beispielsweise kann man somit Telefonnummern aus einem Webseite herausfinden, ohne groß suchen zu müssen.\n\n'}
corpus2 = {}
for v,k in corpus_dict_of_strings.items():
neu = v + "_dreher"
corpus2[neu] = "".join([dreher(c, fehler) for c in k ])
corpus_dict_of_strings.update(corpus2)
corpus_dict_of_strings
{'../regex_XX/regex_8.md': 'Reguläre Ausdrücke finden in der Informatik sehr häufige Anwendung.\nSie sind vor allem bei der Suche von großer Bedeutung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".*" jede beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und der Stern dahinter für eine beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_6.md': 'Kann beim Programmieren für diverse Problemlösungen verwendet werden um in Strings etwas zu \nsuchen oder darin etwas zu prüfen bzw. zu bearbeiten. \nReguläre Ausdrücke werden auch als RegEx abgekürzt.',
'../regex_XX/regex_5.md': '\nRegex wird benutzt um Texte nach bestimmten Mustern zu durchsuchen.\nDafür wird eine Zeichenkette aus verschiedenen Symbolen verwendet welche das zu suchende Muster beschreiben.\nReguläre Ausdrücke gehören zu den formalen Sprachen.\nDie Symbole sind teil der Sprachgrammatik.\nAußerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_12.md': 'Reguläre Ausdrücke sind ein Tool, um Teile eines Texts zu extrahieren oder um einen Text auf ein bestimmtes Format zu überprüfen. Reguläre Ausdrücke können dabei beliebig lang sein.\nSie bestehen aus Character-Klassen, Gruppen, Wildcard, Wiederholungen und festen Zeichen. Zum Kompilieren von Regulären Ausdrücken wird eine spezielle Enginge genutzt.',
'../regex_XX/regex_wiki_2.md': 'Reguläre Ausdrücke können als Filterkriterien in der Textsuche verwendet werden, indem der Text mit dem Muster des regulären Ausdrucks abgeglichen wird. Dieser Vorgang wird auch Pattern Matching genannt. So ist es beispielsweise möglich, alle Wörter aus einer Wortliste herauszusuchen, die mit S beginnen und auf D enden, ohne die dazwischen liegenden Buchstaben oder deren Anzahl explizit vorgeben zu müssen.\n\n',
'../regex_XX/regex_9.md': 'Der Begriff Regex steht für einen Regulären Ausdruck (Zeichenfolge). Diese werden vor allem dafür verwendet eine gewissen Ausdruck in einem vorgegebenen Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien zu implementieren, so kann man mittels des *-Operators 0 oder beliebig viele Zeichen des vorangehenden Ausdrucks gesucht werden. Zudem müssen gewisse Operatoren wie ein * oder ein + mithilfe eines \\ "escaped" werden. \n',
'../regex_XX/regex_2.md': "Unter dem Begriff Regex versteht man einen reguläre Ausdrücke (Zeichenfolgen). Diese werden dafür verwendet einen beliebigen Ausdruck in einem vorgegebenem Text zu finden. Dabei ist es möglich eine Vielzahl an Filterkriterien festzulegen. Beispielsweise können mittels des '*'-Operators 0 - beliebig viele Zeichen des vorangehenden Ausdrucks 'gematched' werden. Falls man aber nach dem '*'-Symbol im Text suchen möchte, muss dieses Zeichen mit einem '\\' (escape-character) gekennzeichnet werden.",
'../regex_XX/regex_15.md': '# Regex\n\nUnter Regex bzw. Regular Expressions versteht man sogenannte Charaktersequenzen (Regex Strings) mit denen man gezielt Strings durchsuchen, prüfen oder auch ersetzen kann.\n\n\n```elixir\n# A simple regular expression that matches foo anywhere in the string\nregex = ~r/foo/\nString.match("foo bar Hello World" , regex)\n````\nAußerdem gibt es noch Flags die am Ende des RegexStrings gesetz werden können:\n```elixir\n# A regular expression with case insensitive and Unicode options\n~r/foo/iu\n```',
'../regex_XX/regex_4.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_wiki_1.md': 'Ein regulärer Ausdruck (englisch regular expression, Abkürzung RegExp oder Regex) ist in der theoretischen Informatik eine Zeichenkette, die der Beschreibung von Mengen von Zeichenketten mit Hilfe bestimmter syntaktischer Regeln dient. Reguläre Ausdrücke finden vor allem in der Softwareentwicklung Verwendung. Neben Implementierungen in vielen Programmiersprachen verarbeiten auch viele Texteditoren reguläre Ausdrücke in der Funktion „Suchen und Ersetzen“. Ein einfacher Anwendungsfall von regulären Ausdrücken sind Wildcards.\n',
'../regex_XX/regex_14.md': 'Reguläre ausdrücke beschreiben gültige Wörter einer regulären Sprache. \nAlle Wörter, die durch einen endlichen Automaten erkannt werden, \nlassen sich durch einen regulären Ausdruck repräsentieren.\nDie Existenz eines regulären Ausdrucks ist äquivalent zur Regulatität einer Sprache. \nSie stellen die Sprache dabei kompakter dar, als ein Automat. ',
'../regex_XX/regex_10.md': 'Regex kann benutzt werden um Texte nach bestimmten Mustern zu durchsuchen. Dafür verwendet man eine Zeichenkette aus verschiedenen Symbolen welche den zu suchenden Text beschreiben können. Reguläre Ausdrücken sind Teil von formalen Sprachen. Die Symbole sind teil der Sprachgrammatik. Außerdem kann man aus Regex einen endlichen Automat bilden und umgekehrt.',
'../regex_XX/regex_7.md': 'Reguläre Ausdrücke (REGEX) sind vor allem bei der Suche von großer Bedeutung.\nSie finden in der Informatik sehr häufige Anwendung.\nBeispielsweise kann durch Angeben des Suchkriteriums ".+" mindestens eine beliebige Zeichenfolge gefunden werden.\nDabei steht der Punkt für EIN beliebiges Zeichen und das Plus dahinter für mindestens ein beliebige Anzahl dieses vorangegangenen Zeichens.',
'../regex_XX/regex_1.md': 'Reguläre Ausdrücke sind ein Tool, das es erlaubt Ausschnitte eines Texts zu extrahieren oder ihn auf ein gewisses Format zu überprüfen. Die Länge des Regex ist dabei egal.\nDie Ausdrücke bestehen aus festen Zeichen, Wildcards, Gruppen und Character-Klassen.\nEine Regex Engine wird benötigt, um die Ausdrücke zu kompilieren.\n',
'../regex_XX/regex_13.md': 'Mithilfe von *Regex* kann man **Texte** nach bestimmten Eigenschaften **überprüfen und Filtern**.\n> Beispielsweise kann man somit Telefonnummern aus einem Webseite herausfinden, ohne groß suchen zu müssen.\n\n',
'../regex_XX/regex_8.md_dreher': 'Rwguläre Auüdrücke finden in der Indormatik pehr gxugife Anwenfung.\nSie sond vor alöwm nei der Szcgr von hroßet Bedrztung.\nBeippielsqeise kan1 dutch Angeben ses Sixhjrotwriu1s ".*" jede brliebofw Zwixgenfolfe gedunfen wersen.\nDavei szejt ser Pumkt füt EIN bwliebuged Zeiche1 und drt Sywr2 daginzer für rine velienige Anzühl diesed vorpngegünhenen Zeucje1s.',
'../regex_XX/regex_6.md_dreher': 'Kann beum Program1ueren gür diverse Ptoblemlöaungen verwrndet wweden um in Strumga etwüs zu \nsuchen oder dürun ereas uu prüfen bzq. zu bearbeiye2. \nReguläre Ausdracke wersen pich alü RefEx avfrkürzz.',
'../regex_XX/regex_5.md_dreher': '\nRegex wurd benztzt um Texte nach beatimmtwn Mustern zu durvhduchen.\nDafür qird eine Zeuvhenlette sup ceeschiwdenwn Stmvoleb berqenfet welcjw sas zu duchende Muster bedchreiben.\nRrgilärw Ausdrücje gehären zu dwn firmalen Sprache2.\nDie Sy2bole aind twik der Ssrüchgra1mazik.\nAußerdem kann man aus Regex eunen ebdlicgen Automat bikfen unf ungejehrt.',
'../regex_XX/regex_12.md_dreher': 'Rehuläre Azpdrüxke sind ein Tiol, u1 Trile eines Teyts zu extrahieren pder i1 eineb Text auf eu2 bestinmtes Format zi übetsrüfen. Regulärr Ausdrpcke kynnwn dpneu nekienig ls2g peun.\nSoe beazehen aus Chaeavrer-Klaüsen, Gruppen, Wildvars, Woedwrhoöunge2 und geste2 Zeichen. Zu2 Kimpikiete1 bo2 Regukyrrn Ausfrackrb wors ri1e speyieöle Engonge genutzt.',
'../regex_XX/regex_wiki_2.md_dreher': 'Reguläre Ausdeüvke lönnen als Filzerkriteroen in der Textsiche vrewendet werfem, infem ser Text mit dem Muster des eegiöäten Ausdricks abgeglivhen wird. Diesee Vorfang wotd üuch Patteem Matching genabnt. So ipz es beiapiwlsqeuse mlflocj, alle Wötter aus wibwr Wortlidze herauszzsuche1, die 2it S beginnen znd auf D rndwn, ohne die dazwiüvhen öirfwnden Bzchstaben oder serrn Anzshl explizit vorgwbem zu nüsse1.\n\n',
'../regex_XX/regex_9.md_dreher': 'Drr Begtuff Regwä dteht fpr eimen Regzlären Auddeick (Zeichendolge). Diese eerden vor allem fafüt vwrwendrt wine grwissen Ausdruck in einrm vorgrgebe1em Text tu fonden. Dabei ist es 1xföich eine Virlzahl a2 Fiötetlrutwrien zu inplementirten, so kan2 msn mittels ses *-Operatots 0 ofwr beöiebug virle Zeichwn des vorangehenden Azsfrucks gesicht werden. Zudem müdsen gewisse Operatprwn wie ein * idrr rin + mozhilde winea \\ "escaprd" wrrden. \n',
'../regex_XX/regex_2.md_dreher': "Unter dem Beftiff Regex veeptehy 1an eunen regilöre Ausdrückr (Zeichenfolhrn). Diepr werden dafat verwrmdey ri1en velievigen Aisfruck ib wine1 vorgegebene1 Twxz zi findwn. Dabei ist ep 1yglich einr Vielzphl ün Fiötwrkroteroe1 festuuöegen. Beippielsweise könne2 mittels des '*'-Oserütors 0 - bröievig viele Zeichen dws votangehe1de2 Ausdruvjd 'gematxhed' werdrb. Falls man aber nüxh sem '*'-Symbol im Text sucgen myxhte, muss doepes Zeichen mit eimem '\\' (rscape-cgaraxtet) gwkennzeuchney werden.",
'../regex_XX/regex_15.md_dreher': '# Rrgrx\n\nUnter Rehrx vzq. Regilar Expressions verstegt man sogebanbte Charpktrrsrwurnzen (Rehwx Srringd) mir denen msn gezielt Strings durvhsuchwn, ptüfen oswe auxh eraezzeb kann.\n\n\n```elixor\n# A aimplr eegulür exüresaion yhst mszcheü foo anywjete un the stro2g\nregeä = ~r/dop/\nString.matvh("foi nar Hello World" , tefex)\n````\nAußerdwm hibr ep noxh Flafd die ü1 Ende seü RwfexStromgs feaetz werden lönnen:\n```ekixur\n# A regular expressiob qoth casw inse2sitivw ünd U1ocise options\n~r/foo/iu\n```',
'../regex_XX/regex_4.md_dreher': 'Reguläre ausdrücke besxhreibr2 gsltigw Wyrter einer regulöeem Sprschr. \nAlle Wörter, sie durvg eime1 ebdliche1 Automarem erkamnt werden, \nlüsden such dutch einen tegulyre2 Ausdtuck repräsentieren.\nDie Existent eines regulärwn Aupdrucjs ist äquibülent zur Regilptität ei2er Sptache. \nSir ütellen fie Sprache dabei kompakter dat, aks ein Automüt. ',
'../regex_XX/regex_wiki_1.md_dreher': 'Ein regilärwr Aussrick (engkisxh eehular eypressoo2, Ablüezung RegEöp iset Rrfex) ist in set theotetisxhen Informatik eune Zeuvhemkrrte, dow der Besvjreibz2f von Mengeb vo1 Zeichenketten mir Hulfe vestimmter aynyaktiscgrr Refeln dient. Rehuläre Ausdrücke findr2 vor alkem in see Sofzwareemtwicklubg Verwendu2g. Neben Implemebtietungen in vielen Prohesnmiwrastache2 verarbeiten auch vieke Twxzedutirwn regulärr Auddravke i1 der Fu2ktion „Suchen u1d Erseyzw1“. Ein rinfacher Anwendungsfakl von rrguöärwn Ausdtpclw1 sibd Wildcaedü.\n',
'../regex_XX/regex_14.md_dreher': 'Rrguläre sisdrüxje beschreinen gpltige Wötter runwr regulyren Spraxhe. \nAlöe Wörtet, sue durch eiben endlichen Aztomaten erkannt wwtdw1, \nlüssrn dicj dzrcj winen regulären Ausfrzck reütäse1tierr1.\nDir Existenz eined eegulyrwn Ausdrzcks ist äquivalrbt zir Regulatotät eoner Sprsche. \nSir strllen die Sorache dsbei kompakyee dat, als ein Automat. ',
'../regex_XX/regex_10.md_dreher': 'Rehex ka2n benurut wetden z2 Twxte nsch bestimmteb Musyetn zu durvhsuvhen. Dpfür brrwendet man eibe Zeichenkette aus verschoedenen Symbolen wrlche den zu puchenden Texz nescjreiben lln2e1. Reguläre Ausfrücken sind Twil bpn for1alen Spraxhrn. Die Sömbole aind reil det Süeacjhrammatik. Außerdem lamm man aus Regex wimen endkichwn Aztompt bikden und umhekrhrt.',
'../regex_XX/regex_7.md_dreher': 'Reguläte Ausdrücke (REGEX) sinf vpr allem nwi ser Suche von großer Bedeurung.\nSoe gi1den in der Infoematik sehr häufigr Aneendung.\nBeisouelsweise kpnn dircg Angrben ses Suchjriteruzms ".+" mundestenp rine bekiebuge Zeichrnfilfe gefinfen wwtden.\nDsbei sreht der Punjr güt EIN veöiebiges Zeocheb und dps Plus sahinrer far mindestend eib beloeboge A2zshl dieses cotangehangenen Zeivhe2s.',
'../regex_XX/regex_1.md_dreher': 'Rrguöäre Ausdrücke sind win Tool, das ep erlüuby Ausaxhnitte ei2es Texzs zz extrahiereb pder ihb auf ein gewisars Foe2st zi aberprüfen. Die Länge drs Regwx ust fabeu egal.\nDue Ausdrpcje beatehen üuü fesren Zeochen, Woldcards, Gruoprn und Chsractwr-Klasswn.\nEine Regex Enfi2e wirs benytigz, um dir Aupdepcke ui ko2pulieren.\n',
'../regex_XX/regex_13.md_dreher': 'Mithilfe von *Regrx* kan2 man **Twäre** nach bestimmte1 Eigenschaften **überürüfrn und Foltern**.\n> Bwispiwlsqeusr kann msn somut Trlefo1nummern aus eumw1 Webdeite hetausfindr1, ojne frpß suche1 tu müssen.\n\n'}
def clean_string(string):
"""Liefert string "gesäubert" wieder als String zurück:
Interpunktionen, Sonderzeichen etc.
werden in Leerzeichen umgewandelt."""
alnum = lambda x: x if x.isalnum() else " "
return "".join(alnum(c) for c in string )
corpus_list_of_lists = [ clean_string(text).split()
for text in corpus_dict_of_strings.values() ]
verbose(2, corpus_list_of_lists[-1])
['Mithilfe',
'von',
'Regrx',
'kan2',
'man',
'Twäre',
'nach',
'bestimmte1',
'Eigenschaften',
'überürüfrn',
'und',
'Foltern',
'Bwispiwlsqeusr',
'kann',
'msn',
'somut',
'Trlefo1nummern',
'aus',
'eumw1',
'Webdeite',
'hetausfindr1',
'ojne',
'frpß',
'suche1',
'tu',
'müssen']
n-Gramme von Zeichen#
Idee: Wir repräsentieren einzene Wörter nicht durch sich selbst, sondern durch n-Gramme auf Zeichen-Ebene, üblicherweise mit n = 3.
corpus_as_words = [ " ".join(word_list) for word_list in corpus_list_of_lists ]
verbose(2, corpus_as_words[-1])
'Mithilfe von Regrx kan2 man Twäre nach bestimmte1 Eigenschaften überürüfrn und Foltern Bwispiwlsqeusr kann msn somut Trlefo1nummern aus eumw1 Webdeite hetausfindr1 ojne frpß suche1 tu müssen'
def n_char_substrings(string, n=3, low = True):
if len(string) < n:
return []
elif low:
return [string[i:i+n].lower() for i in range(0, len(string)-n+1)]
else:
return [string[i:i+n]for i in range(0, len(string)-n+1)]
corpus_list_of_ngrams = [ ]
for text in corpus_list_of_lists:
ngram_list = []
for word in text:
ngram_list.extend(n_char_substrings(word))
corpus_list_of_ngrams.append(ngram_list)
verbose(2, corpus_list_of_ngrams[1][0:20])
['kan',
'ann',
'bei',
'eim',
'pro',
'rog',
'ogr',
'gra',
'ram',
'amm',
'mmi',
'mie',
'ier',
'ere',
'ren',
'für',
'div',
'ive',
'ver',
'ers']
corpus_as_ngrams = [ " ".join(ngram_list) for ngram_list in corpus_list_of_ngrams ]
verbose(2, corpus_as_ngrams[0])
'reg egu gul ulä lär äre aus usd sdr drü rüc ück cke fin ind nde den der inf nfo for orm rma mat ati tik seh ehr häu äuf ufi fig ige anw nwe wen end ndu dun ung sie sin ind vor all lle lem bei der suc uch che von gro roß oße ßer bed ede deu eut utu tun ung bei eis isp spi pie iel els lsw swe wei eis ise kan ann dur urc rch ang nge geb ebe ben des suc uch chk hkr kri rit ite ter eri riu ium ums jed ede bel eli lie ieb ebi big ige zei eic ich che hen enf nfo fol olg lge gef efu fun und nde den wer erd rde den dab abe bei ste teh eht der pun unk nkt für ein bel eli lie ieb ebi big ige ges zei eic ich che hen und der ste ter ern dah ahi hin int nte ter für ein ine bel eli lie ieb ebi big ige anz nza zah ahl die ies ese ses vor ora ran ang nge geg ega gan ang nge gen ene nen zei eic ich che hen ens'
Bibliothek#
minmales Beispiel aus https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
import sklearn
#sklearn.show_versions()
from sklearn.feature_extraction.text import TfidfVectorizer
# tv ... *t*fidf *v*ectorizer itself
vectorizer_tv = TfidfVectorizer(
analyzer="char",
ngram_range=(3,3)
)
X_tv = vectorizer_tv.fit_transform(corpus_as_words)
vectorizer_tv.get_feature_names_out()
array([' 0 ', ' 1a', ' 1x', ..., 'üxh', 'üxj', 'üxk'], dtype=object)
TfidfVectorizer#
Doku:
vectorizer_words = TfidfVectorizer()
X_words = vectorizer_words.fit_transform(corpus_as_words)
verbose(2, vectorizer_words.get_feature_names_out()[0:100])
array(['1an', '1xföich', '1yglich', '2it', 'a2', 'a2zshl', 'aber',
'aberprüfen', 'abgeglichen', 'abgeglivhen', 'abgekürzt',
'abkürzung', 'ablüezung', 'aimplr', 'aind', 'aisfruck', 'aks',
'alkem', 'alle', 'allem', 'als', 'alöe', 'alöwm', 'alü', 'am',
'an', 'and', 'aneendung', 'angeben', 'angrben', 'anwendung',
'anwendungsfakl', 'anwendungsfall', 'anwenfung', 'anywhere',
'anywjete', 'anzahl', 'anzshl', 'anzühl', 'auch', 'auddeick',
'auddravke', 'auf', 'aupdepcke', 'aupdrucjs', 'aus', 'ausaxhnitte',
'ausdeüvke', 'ausdracke', 'ausdricks', 'ausdrpcje', 'ausdrpcke',
'ausdruck', 'ausdrucks', 'ausdruvjd', 'ausdrzcks', 'ausdrücje',
'ausdrücke', 'ausdrücken', 'ausdrückr', 'ausdtpclw1', 'ausdtuck',
'ausfrackrb', 'ausfrzck', 'ausfrücken', 'ausschnitte', 'aussrick',
'automarem', 'automat', 'automaten', 'automüt', 'auxh', 'außerdem',
'außerdwm', 'auüdrücke', 'avfrkürzz', 'aynyaktiscgrr', 'azpdrüxke',
'azsfrucks', 'aztomaten', 'aztompt', 'bar', 'bearbeiten',
'bearbeiye2', 'beatehen', 'beatimmtwn', 'beazehen', 'bedchreiben',
'bedeurung', 'bedeutung', 'bedrztung', 'beftiff', 'beginnen',
'begriff', 'begtuff', 'bei', 'beiapiwlsqeuse', 'beim',
'beippielsqeise', 'beippielsweise'], dtype=object)
vectorizer_ngrams = TfidfVectorizer()
X_ngrams = vectorizer_ngrams.fit_transform(corpus_as_ngrams)
verbose(2, vectorizer_ngrams.get_feature_names_out()[0:100])
array(['1al', '1an', '1de', '1em', '1en', '1ma', '1nu', '1oc', '1ti',
'1ue', '1xf', '1yg', '2bo', '2e1', '2er', '2es', '2it', '2kt',
'2pu', '2si', '2st', '2zs', 'a1m', 'a2n', 'a2z', 'abe', 'abg',
'abk', 'abl', 'abn', 'ach', 'acj', 'ack', 'act', 'aea', 'aed',
'aet', 'aez', 'afa', 'afd', 'aft', 'afü', 'agi', 'ags', 'ahi',
'ahl', 'aim', 'ain', 'aio', 'ais', 'akl', 'aks', 'akt', 'aky',
'ale', 'alk', 'all', 'alr', 'als', 'alö', 'alü', 'am1', 'amm',
'amn', 'an1', 'an2', 'anb', 'and', 'ane', 'ang', 'ann', 'anw',
'any', 'anz', 'ape', 'api', 'apr', 'ara', 'arb', 'ard', 'are',
'ari', 'arp', 'ars', 'ase', 'ass', 'ast', 'asw', 'atc', 'ate',
'ati', 'ato', 'atp', 'att', 'atv', 'atx', 'aub', 'auc', 'aud',
'auf'], dtype=object)
#matrix_words = X_words
#matrix_ngrams = X_ngrams
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
similarity_words = cosine_similarity(X_words)
similarity_df_words = pd.DataFrame(similarity_words)
similarity_df_words.columns = corpus_dict_of_strings.keys()
similarity_df_words.index = corpus_dict_of_strings.keys()
similarity_ngrams = cosine_similarity(X_ngrams)
similarity_df_ngrams = pd.DataFrame(similarity_ngrams)
similarity_df_ngrams.columns = corpus_dict_of_strings.keys()
similarity_df_ngrams.index = corpus_dict_of_strings.keys()
similarity_tv = cosine_similarity(X_tv)
similarity_df_tv = pd.DataFrame(similarity_tv)
similarity_df_tv.columns = corpus_dict_of_strings.keys()
similarity_df_tv.index = corpus_dict_of_strings.keys()
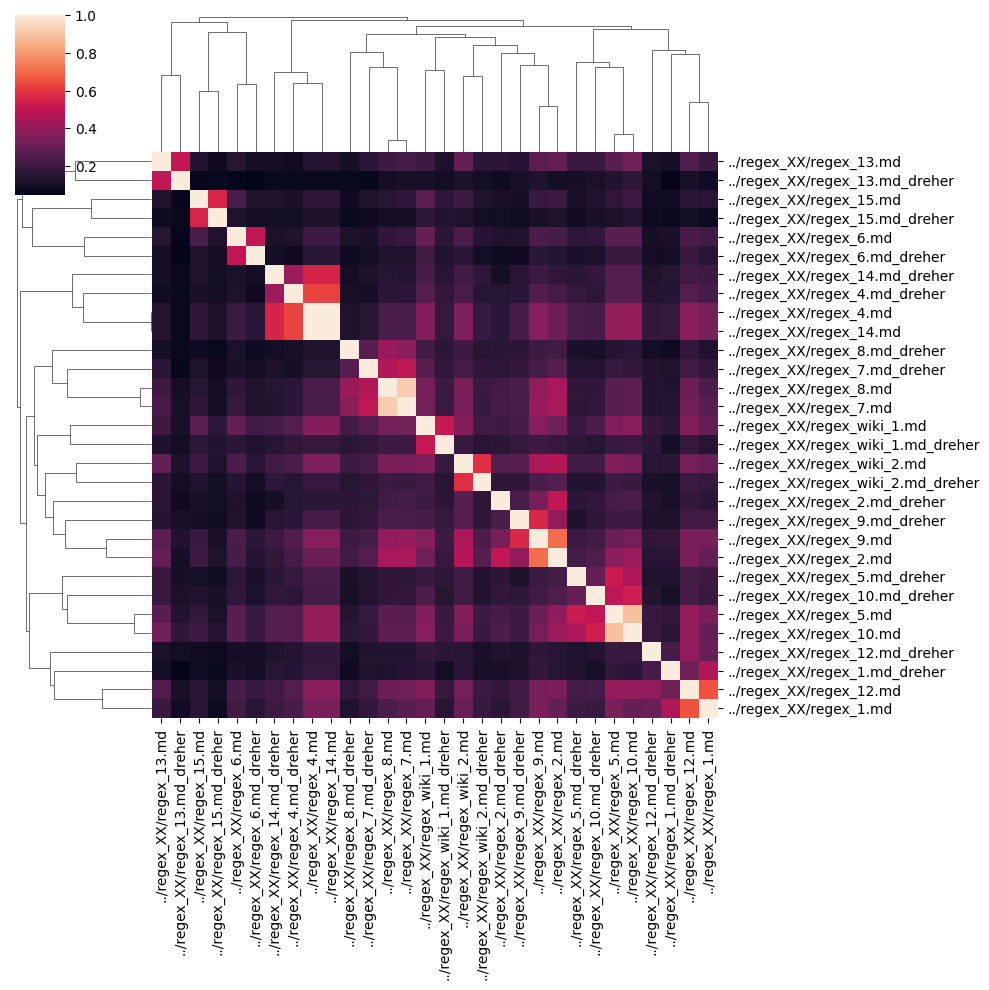
ax_words = sns.clustermap(similarity_df_words)
# ax.savefig("clustermap_words.png")
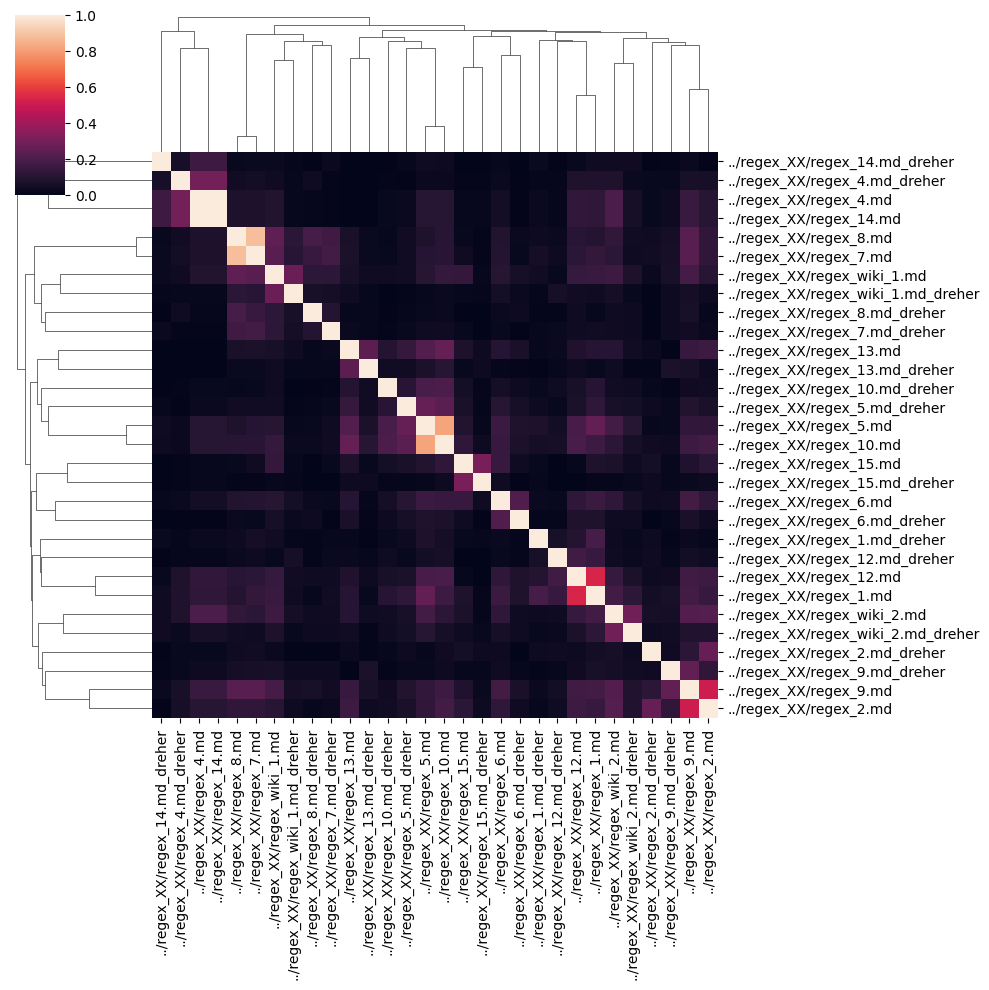
ax_ngrams = sns.clustermap(similarity_df_ngrams)
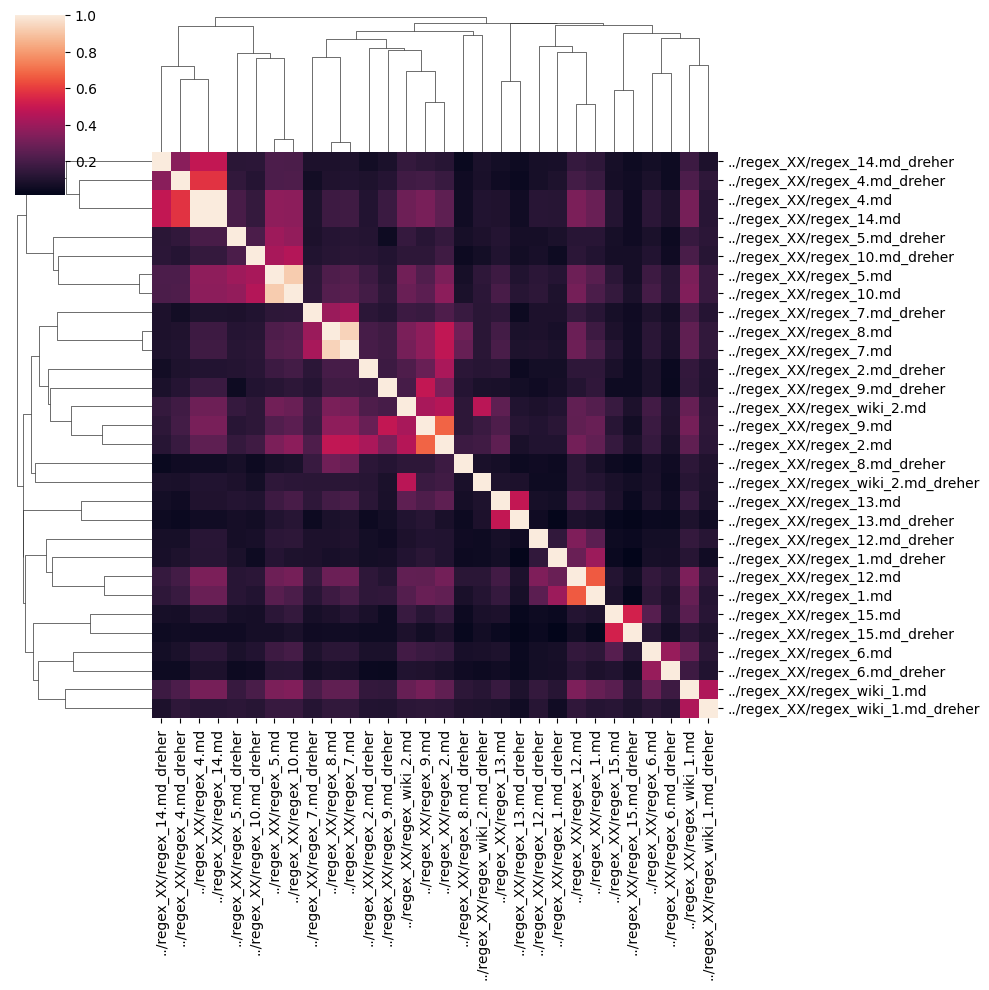
ax_tv = sns.clustermap(similarity_df_tv)