20 Newsgroups: Classifyer Comparison
Contents
20 Newsgroups: Classifyer Comparison#
Quellen#
5.6.2. The 20 newsgroups text dataset#
Einstieg:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_20newsgroups.html#sklearn.datasets.fetch_20newsgroups (scikit-learn 1.1.0)
Dort:
Read more in the User Guide > 7.2.2. The 20 newsgroups text dataset
Examples using sklearn.datasets.fetch_20newsgroups:
Wir starten hier: Classification of text documents using sparse features
Weitere Beispiele:
Sample pipeline for text feature extraction and evaluation; nutzt
SGDClassifiernutzt
SGDClassifier, aber auch sonst interessant? Weiß nicht: Semi-supervised Classification on a Text Dataset
Classification of text documents using sparse features#
ohne USE_HASHING, ohne SELECT_CHI2
reduziert um ein paar wenige Classifier, die trotz hoher Trainingszeit keinen guten Score liefern
# Optional feature selection: either False, or an integer: the number of
# features to select
#SELECT_CHI2 = False
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
# "sci.space",
]
data_train = fetch_20newsgroups(
subset="train", categories=categories, shuffle=True, random_state=42,
remove = ('headers', 'footers', 'quotes') # hinzugefügt JB
)
data_test = fetch_20newsgroups(
subset="test", categories=categories, shuffle=True, random_state=42,
remove = ('headers', 'footers', 'quotes') # hinzugefügt JB
)
#print("data loaded")
# order of labels in `target_names` can be different from `categories`
target_names = data_train.target_names
target_names
['alt.atheism', 'comp.graphics', 'talk.religion.misc']
def size_mb(docs):
return sum(len(s.encode("utf-8")) for s in docs) / 1e6
data_train_size_mb = size_mb(data_train.data)
data_test_size_mb = size_mb(data_test.data)
print(
"%d documents - %0.3fMB (training set)" % (len(data_train.data), data_train_size_mb)
)
print("%d documents - %0.3fMB (test set)" % (len(data_test.data), data_test_size_mb))
print("%d categories:" % len(target_names), target_names)
1441 documents - 1.655MB (training set)
959 documents - 1.376MB (test set)
3 categories: ['alt.atheism', 'comp.graphics', 'talk.religion.misc']
data_train.data[:3]
['Those things,\n\twhich ye have both learned, and received,\n\tand heard, and seen in me,\n\tdo:\n\tand the God of peace shall be with you.',
'Greetings all.\n\tAccording to a FAQ I read, on 30 July 1992, Joshua C. Jensen posted an \narticle on bitmap manipulation (specifically, scaling and perspective) to the \nnewsgroup rec.games.programmer. (article 7716)\n\tThe article included source code in Turbo Pascal with inline assembly \nlanguage.\n\n\tI have been unable to find an archive for this newsgroup, or a current \nemail address for Joshua C. Jensen.\n\tIf anyone has the above details, or a copy of the code, could they \nplease let me know.\tMany thanks.\n\t\t\t\t\tYours gratefully, etc. Myles.\n',
'\nAs many people have mentioned, there is no reason why insurers could not\noffer a contract without abortion services for a different premium.\nThe problem is that there is no guarantee that this premium would be\nlower for those who chose this type of contract. Although you are\nremoving one service, that may have feedbacks into other types of covered\ncare which results in a net increase in actuarial costs.\n\nFor an illustrative example in the opposite direction, it may be possible\nto ADD services to an insurance contract and REDUCE the premium. If you\nadd preventative services and this reduces acute care use, then the total\npremium may fall.']
set(data_train.target)
{0, 1, 2}
y_train, y_test = data_train.target, data_test.target
from time import time
from sklearn.feature_extraction.text import TfidfVectorizer
t0 = time()
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5, stop_words="english")
X_train = vectorizer.fit_transform(data_train.data)
duration = time() - t0
print("vectorizer.fit_transform() done in %fs at %0.3fMB/s" % (duration, data_train_size_mb / duration))
print("n_samples: %d, n_features: %d" % X_train.shape)
vectorizer.fit_transform() done in 0.124515s at 13.292MB/s
n_samples: 1441, n_features: 20052
t0 = time()
X_test = vectorizer.transform(data_test.data)
duration = time() - t0
print("done in %fs at %0.3fMB/s" % (duration, data_test_size_mb / duration))
print("n_samples: %d, n_features: %d" % X_test.shape)
done in 0.066754s at 20.607MB/s
n_samples: 959, n_features: 20052
feature_names = vectorizer.get_feature_names_out()
import numpy as np
from sklearn import metrics
from sklearn.utils.extmath import density
def trim(s):
"""Trim string to fit on terminal (assuming 80-column display)"""
return s if len(s) <= 80 else s[:77] + "..."
def benchmark(clf):
print("_" * 80)
print("Training: ")
print(clf)
t0 = time()
clf.fit(X_train, y_train)
train_time = time() - t0
print("train time: %0.3fs" % train_time)
t0 = time()
pred = clf.predict(X_test)
test_time = time() - t0
print("test time: %0.3fs" % test_time)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
if hasattr(clf, "coef_"):
print("dimensionality: %d" % clf.coef_.shape[1])
print("density: %f" % density(clf.coef_))
if feature_names is not None:
print("top 10 keywords per class:")
for i, label in enumerate(target_names):
top10 = np.argsort(clf.coef_[i])[-10:]
print(trim("%s: %s" % (label, " ".join(feature_names[top10]))))
print()
print("classification report:")
print(metrics.classification_report(y_test, pred, target_names=target_names))
print("confusion matrix:")
print(metrics.confusion_matrix(y_test, pred))
print()
clf_descr = str(clf).split("(")[0]
return clf_descr, score, train_time, test_time
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import RidgeClassifier
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import Perceptron
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.naive_bayes import BernoulliNB, ComplementNB, MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import NearestCentroid
from sklearn.ensemble import RandomForestClassifier
results = []
for clf, name in (
(RidgeClassifier(tol=1e-2, solver="auto"), "Ridge Classifier"), # solver="sag")
(Perceptron(max_iter=50), "Perceptron"),
(PassiveAggressiveClassifier(max_iter=50), "Passive-Aggressive"),
# (KNeighborsClassifier(n_neighbors=10), "kNN"),
# (RandomForestClassifier(), "Random forest"),
):
print("=" * 80)
print(name)
results.append(benchmark(clf))
for penalty in ["l2", "l1"]:
print("=" * 80)
print("%s penalty" % penalty.upper())
# Train Liblinear model
results.append(benchmark(LinearSVC(penalty=penalty, dual=False, tol=1e-3)))
# Train SGD model
results.append(benchmark(SGDClassifier(alpha=0.0001, max_iter=50, penalty=penalty)))
# Train SGD with Elastic Net penalty
print("=" * 80)
print("Elastic-Net penalty")
results.append(
benchmark(SGDClassifier(alpha=0.0001, max_iter=50, penalty="elasticnet"))
)
# Train NearestCentroid without threshold
print("=" * 80)
print("NearestCentroid (aka Rocchio classifier)")
results.append(benchmark(NearestCentroid()))
# Train sparse Naive Bayes classifiers
#print("=" * 80)
#print("Naive Bayes")
#results.append(benchmark(MultinomialNB(alpha=0.01)))
# results.append(benchmark(BernoulliNB(alpha=0.01)))
#results.append(benchmark(ComplementNB(alpha=0.1)))
print("=" * 80)
print("LinearSVC with L1-based feature selection")
# The smaller C, the stronger the regularization.
# The more regularization, the more sparsity.
results.append(
benchmark(
Pipeline(
[
(
"feature_selection",
SelectFromModel(LinearSVC(penalty="l1", dual=False, tol=1e-3)),
),
("classification", LinearSVC(penalty="l2")),
]
)
)
)
================================================================================
Ridge Classifier
________________________________________________________________________________
Training:
RidgeClassifier(tol=0.01)
train time: 0.011s
test time: 0.003s
accuracy: 0.779
dimensionality: 20052
density: 1.000000
top 10 keywords per class:
alt.atheism: motto islamic isn atheist deletion bobby religion islam atheists...
comp.graphics: files images 3d image computer looking file hi thanks graphics
talk.religion.misc: koresh blood rosicrucian order christ jesus children fbi ...
classification report:
precision recall f1-score support
alt.atheism 0.73 0.68 0.70 319
comp.graphics 0.86 0.97 0.91 389
talk.religion.misc 0.68 0.61 0.64 251
accuracy 0.78 959
macro avg 0.76 0.75 0.75 959
weighted avg 0.77 0.78 0.77 959
confusion matrix:
[[216 32 71]
[ 9 377 3]
[ 70 27 154]]
================================================================================
Perceptron
________________________________________________________________________________
Training:
Perceptron(max_iter=50)
train time: 0.005s
test time: 0.000s
accuracy: 0.765
dimensionality: 20052
density: 0.347114
top 10 keywords per class:
alt.atheism: imaginative motto enlightening keith atheist atheism position na...
comp.graphics: file 42 algorithm hello ftp code thanks keywords ditto graphics
talk.religion.misc: dead moment cult christians critus lunacy cockroaches chr...
classification report:
precision recall f1-score support
alt.atheism 0.71 0.66 0.68 319
comp.graphics 0.88 0.93 0.90 389
talk.religion.misc 0.64 0.65 0.64 251
accuracy 0.77 959
macro avg 0.74 0.74 0.74 959
weighted avg 0.76 0.77 0.76 959
confusion matrix:
[[209 31 79]
[ 15 363 11]
[ 69 20 162]]
================================================================================
Passive-Aggressive
________________________________________________________________________________
Training:
PassiveAggressiveClassifier(max_iter=50)
train time: 0.007s
test time: 0.000s
accuracy: 0.773
dimensionality: 20052
density: 0.724466
top 10 keywords per class:
alt.atheism: position religion claim perfect nanci islam atheists bobby athei...
comp.graphics: pc ftp computer hi software looking file thanks image graphics
talk.religion.misc: jesus order wrong blood children cult fbi christ christia...
classification report:
precision recall f1-score support
alt.atheism 0.72 0.66 0.69 319
comp.graphics 0.87 0.95 0.91 389
talk.religion.misc 0.66 0.63 0.65 251
accuracy 0.77 959
macro avg 0.75 0.75 0.75 959
weighted avg 0.77 0.77 0.77 959
confusion matrix:
[[212 29 78]
[ 14 370 5]
[ 68 24 159]]
================================================================================
L2 penalty
________________________________________________________________________________
Training:
LinearSVC(dual=False, tol=0.001)
train time: 0.017s
test time: 0.000s
accuracy: 0.777
dimensionality: 20052
density: 1.000000
top 10 keywords per class:
alt.atheism: isn perfect islamic deletion atheist religion bobby islam atheis...
comp.graphics: files images computer 3d looking hi file image thanks graphics
talk.religion.misc: cult jesus blood order rosicrucian christ children fbi ch...
classification report:
precision recall f1-score support
alt.atheism 0.73 0.67 0.70 319
comp.graphics 0.87 0.97 0.91 389
talk.religion.misc 0.67 0.62 0.64 251
accuracy 0.78 959
macro avg 0.75 0.75 0.75 959
weighted avg 0.77 0.78 0.77 959
confusion matrix:
[[214 32 73]
[ 9 376 4]
[ 71 25 155]]
________________________________________________________________________________
Training:
SGDClassifier(max_iter=50)
train time: 0.008s
test time: 0.000s
accuracy: 0.773
dimensionality: 20052
density: 0.620370
top 10 keywords per class:
alt.atheism: just deletion enlightening atheist islam keith religion nanci at...
comp.graphics: hello looking computer 3d ftp file hi image thanks graphics
talk.religion.misc: critus god commandment children cult quote wrong rosicruc...
classification report:
precision recall f1-score support
alt.atheism 0.73 0.65 0.68 319
comp.graphics 0.87 0.96 0.91 389
talk.religion.misc 0.65 0.65 0.65 251
accuracy 0.77 959
macro avg 0.75 0.75 0.75 959
weighted avg 0.77 0.77 0.77 959
confusion matrix:
[[206 32 81]
[ 11 373 5]
[ 66 23 162]]
================================================================================
L1 penalty
________________________________________________________________________________
Training:
LinearSVC(dual=False, penalty='l1', tol=0.001)
train time: 0.032s
test time: 0.000s
accuracy: 0.754
dimensionality: 20052
density: 0.016025
top 10 keywords per class:
alt.atheism: motto policy sea religion atheist islam atheists atheism bobby risk
comp.graphics: file 3d ftp images image computer 68070 software hi graphics
talk.religion.misc: blood rosicrucian 666 christian christians cult thou chil...
classification report:
precision recall f1-score support
alt.atheism 0.69 0.66 0.67 319
comp.graphics 0.85 0.95 0.90 389
talk.religion.misc 0.65 0.58 0.61 251
accuracy 0.75 959
macro avg 0.73 0.73 0.73 959
weighted avg 0.75 0.75 0.75 959
confusion matrix:
[[209 37 73]
[ 14 369 6]
[ 79 27 145]]
________________________________________________________________________________
Training:
SGDClassifier(max_iter=50, penalty='l1')
train time: 0.021s
test time: 0.000s
accuracy: 0.758
dimensionality: 20052
density: 0.057916
top 10 keywords per class:
alt.atheism: islamic motto nanci religion islam risk deletion bobby atheists ...
comp.graphics: thanks image 3d hi looking pov ftp software file graphics
talk.religion.misc: christian order creation rosicrucian children christians ...
classification report:
precision recall f1-score support
alt.atheism 0.72 0.61 0.66 319
comp.graphics 0.87 0.95 0.91 389
talk.religion.misc 0.62 0.64 0.63 251
accuracy 0.76 959
macro avg 0.74 0.74 0.73 959
weighted avg 0.75 0.76 0.75 959
confusion matrix:
[[195 33 91]
[ 9 371 9]
[ 67 23 161]]
================================================================================
Elastic-Net penalty
________________________________________________________________________________
Training:
SGDClassifier(max_iter=50, penalty='elasticnet')
train time: 0.032s
test time: 0.001s
accuracy: 0.773
dimensionality: 20052
density: 0.286588
top 10 keywords per class:
alt.atheism: deletion religion keith islam bobby atheist risk nanci atheists ...
comp.graphics: software ftp 3d looking computer image thanks file hi graphics
talk.religion.misc: christ commandment rosicrucian blood order cult fbi wrong...
classification report:
precision recall f1-score support
alt.atheism 0.73 0.66 0.69 319
comp.graphics 0.87 0.95 0.91 389
talk.religion.misc 0.66 0.64 0.65 251
accuracy 0.77 959
macro avg 0.75 0.75 0.75 959
weighted avg 0.77 0.77 0.77 959
confusion matrix:
[[210 32 77]
[ 13 371 5]
[ 66 25 160]]
================================================================================
NearestCentroid (aka Rocchio classifier)
________________________________________________________________________________
Training:
NearestCentroid()
train time: 0.004s
test time: 0.001s
accuracy: 0.764
classification report:
precision recall f1-score support
alt.atheism 0.71 0.63 0.66 319
comp.graphics 0.90 0.93 0.91 389
talk.religion.misc 0.63 0.69 0.66 251
accuracy 0.76 959
macro avg 0.74 0.75 0.74 959
weighted avg 0.76 0.76 0.76 959
confusion matrix:
[[200 23 96]
[ 22 360 7]
[ 61 17 173]]
================================================================================
LinearSVC with L1-based feature selection
________________________________________________________________________________
Training:
Pipeline(steps=[('feature_selection',
SelectFromModel(estimator=LinearSVC(dual=False, penalty='l1',
tol=0.001))),
('classification', LinearSVC())])
train time: 0.037s
test time: 0.001s
accuracy: 0.740
classification report:
precision recall f1-score support
alt.atheism 0.69 0.61 0.65 319
comp.graphics 0.84 0.95 0.89 389
talk.religion.misc 0.62 0.58 0.60 251
accuracy 0.74 959
macro avg 0.72 0.71 0.71 959
weighted avg 0.73 0.74 0.73 959
confusion matrix:
[[195 42 82]
[ 13 369 7]
[ 75 30 146]]
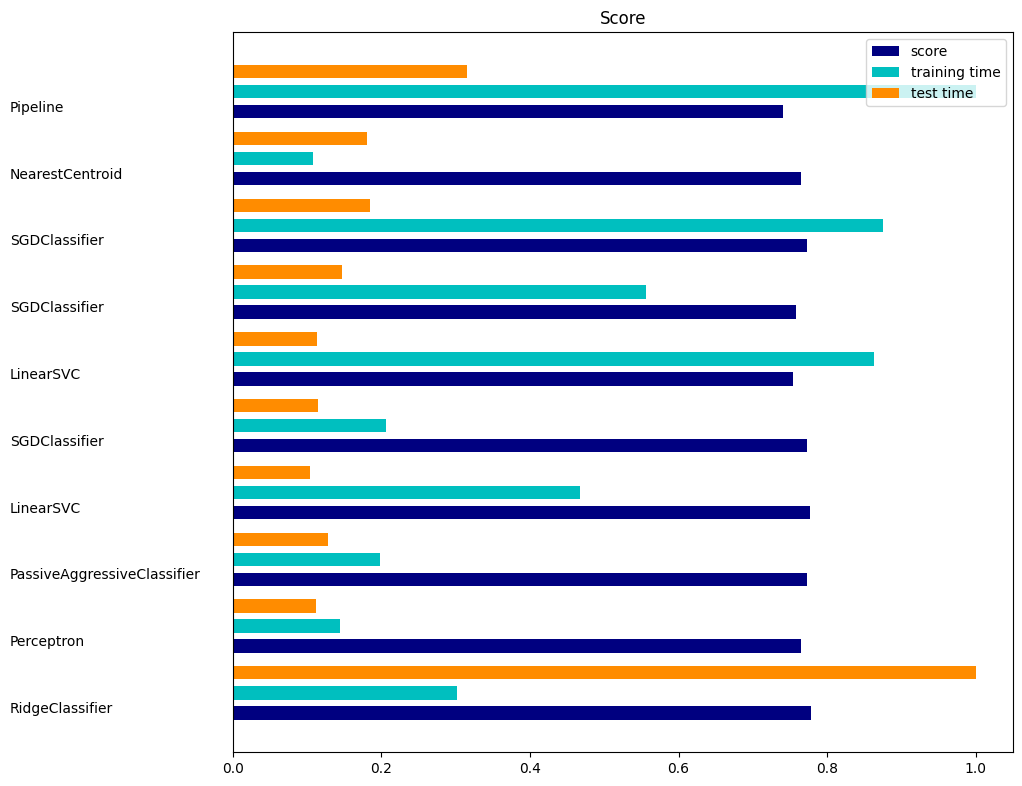
import matplotlib.pyplot as plt
indices = np.arange(len(results))
results = [[x[i] for x in results] for i in range(4)]
clf_names, score, training_time, test_time = results
training_time = np.array(training_time) / np.max(training_time)
test_time = np.array(test_time) / np.max(test_time)
plt.figure(figsize=(12, 8))
plt.title("Score")
plt.barh(indices, score, 0.2, label="score", color="navy")
plt.barh(indices + 0.3, training_time, 0.2, label="training time", color="c")
plt.barh(indices + 0.6, test_time, 0.2, label="test time", color="darkorange")
plt.yticks(())
plt.legend(loc="best")
plt.subplots_adjust(left=0.25)
plt.subplots_adjust(top=0.95)
plt.subplots_adjust(bottom=0.05)
for i, c in zip(indices, clf_names):
plt.text(-0.3, i, c)
plt.show()